Downloaded 35 times










![Wrapping model training in UDF
Prepare the Matrix with inputs
for model training
Normalize the data using normalization
defined for this particular cluster
Generate sample weights which enable
controlling the learning rate
Get the current model from DB
(use in memory DB for fast response)
Preform partial fit using the sample weights
Important trick:
Converts numpy.ndarray[numpy.float64]
into native python list[float] which then
can be autoconverted to Spark List[Double]
Register UDF which returns Spark List[Double]](https://image.slidesharecdn.com/sparksummitjosefhabdankpredictionasaservicewithensemblemodelv3-161220133510/85/Prediction-as-a-service-with-ensemble-model-in-SparkML-and-Python-ScikitLearn-17-320.jpg)
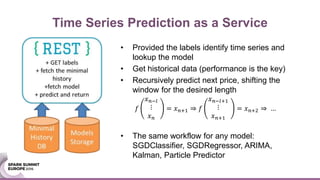







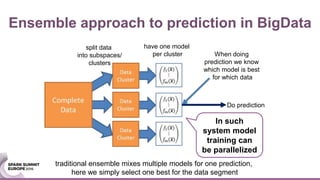
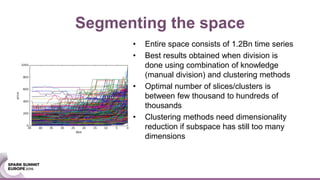
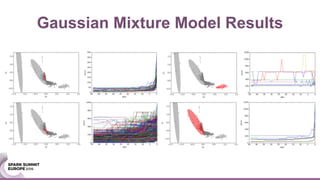
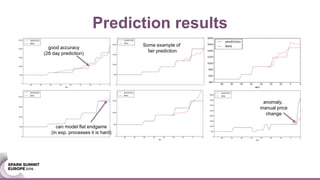
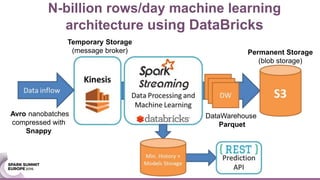
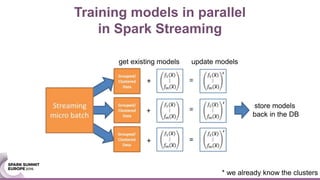
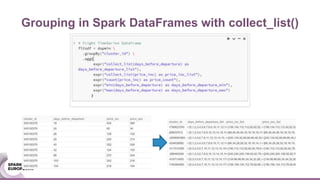
The document discusses an ensemble modeling approach for large-scale data science, specifically for predicting airfare prices using SparkML and Python's Scikit-learn. It highlights the need for a robust architecture that supports online learning and parallel model training on billions of rows daily, showcasing techniques for clustering and optimizing model predictions. The author emphasizes the effectiveness of combining various machine learning models and infrastructure for accurate and scalable prediction services in the aviation industry.























































































