


















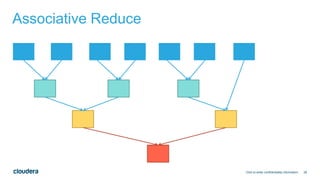
![29
WordCount SummingBird
def wordCount[P <: Platform[P]]
(source: Producer[P, String], store: P#Store[String, Long]) =
source.flatMap { sentence =>
toWords(sentence).map(_ -> 1L)
}.sumByKey(store)
val stormTopology = Storm.remote(“stormName”).plan(wordCount)
val hadoopJob = Scalding(“scaldingName”).plan(wordCount)
Click to enter confidentiality information](https://image.slidesharecdn.com/june111100amclouderashapira-150629234916-lva1-app6891/85/Have-your-Cake-and-Eat-it-Too-Architecture-for-Batch-and-Real-time-processing-29-320.jpg)

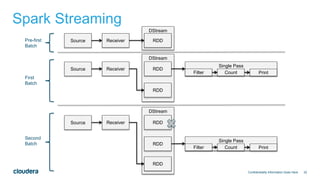
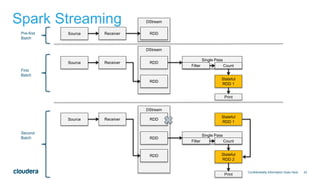

![35
Spark Example
©2014 Cloudera, Inc. All rights reserved.
1. val conf = new SparkConf().setMaster("local[2]”)
2. val sc = new SparkContext(conf)
3. val lines = sc.textFile(path, 2)
4. val words = lines.flatMap(_.split(" "))
5. val pairs = words.map(word => (word, 1))
6. val wordCounts = pairs.reduceByKey(_ + _)
7. wordCounts.print()](https://image.slidesharecdn.com/june111100amclouderashapira-150629234916-lva1-app6891/85/Have-your-Cake-and-Eat-it-Too-Architecture-for-Batch-and-Real-time-processing-35-320.jpg)
![36
Spark Streaming Example
©2014 Cloudera, Inc. All rights reserved.
1. val conf = new SparkConf().setMaster("local[2]”)
2. val ssc = new StreamingContext(conf, Seconds(1))
3. val lines = ssc.socketTextStream("localhost", 9999)
4. val words = lines.flatMap(_.split(" "))
5. val pairs = words.map(word => (word, 1))
6. val wordCounts = pairs.reduceByKey(_ + _)
7. wordCounts.print()
8. ssc.start()](https://image.slidesharecdn.com/june111100amclouderashapira-150629234916-lva1-app6891/85/Have-your-Cake-and-Eat-it-Too-Architecture-for-Batch-and-Real-time-processing-36-320.jpg)















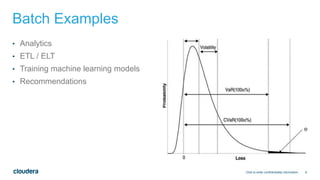
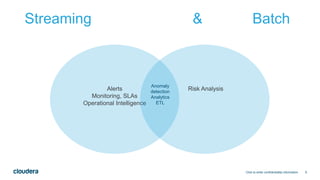
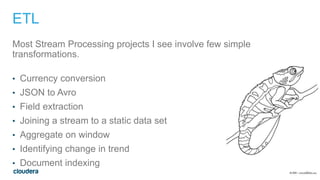
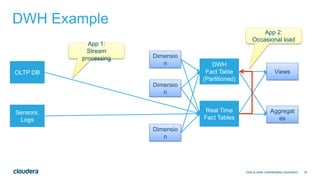
This document discusses architectures for processing both streaming and batch data. It begins by explaining why both streaming and batch processing are needed. It then discusses challenges with maintaining separate streaming and batch applications that do the same work. Various architectures and technologies are presented as solutions, including the Kappa architecture, Lambda architecture, SummingBird, Apache Spark, Apache Flink, and bringing your own framework. Specific examples are provided for how to implement word count in many of these technologies for both batch and streaming data.










































































































