Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
datastaxjp
1,893 views
(LT)Spark and Cassandra
Apache Cassandraがリアルタイム分析でNOSQLのApache Cassandraに出会った。(2016年 Hadoop/Spark Conference Japan)
Technology
◦
Read more
3
Save
Share
Embed
Embed presentation
1
/ 14
2
/ 14
3
/ 14
4
/ 14
5
/ 14
6
/ 14
7
/ 14
8
/ 14
9
/ 14
10
/ 14
11
/ 14
12
/ 14
13
/ 14
14
/ 14
More Related Content
PDF
SparkとCassandraの美味しい関係
by
datastaxjp
PDF
Apache Hadoop の現在と将来(Hadoop / Spark Conference Japan 2016 キーノート講演資料)
by
Hadoop / Spark Conference Japan
PDF
DB Tech showcase Tokyo 2015 Works Applications
by
2t3
PPTX
RDB開発者のためのApache Cassandra データモデリング入門
by
Yuki Morishita
PDF
Developers.IO 2019 Effective Datalake
by
Satoru Ishikawa
PDF
ゼロから始めるSparkSQL徹底活用!
by
Nagato Kasaki
PPTX
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
PDF
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
by
Future Of Data Japan
SparkとCassandraの美味しい関係
by
datastaxjp
Apache Hadoop の現在と将来(Hadoop / Spark Conference Japan 2016 キーノート講演資料)
by
Hadoop / Spark Conference Japan
DB Tech showcase Tokyo 2015 Works Applications
by
2t3
RDB開発者のためのApache Cassandra データモデリング入門
by
Yuki Morishita
Developers.IO 2019 Effective Datalake
by
Satoru Ishikawa
ゼロから始めるSparkSQL徹底活用!
by
Nagato Kasaki
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
by
Future Of Data Japan
What's hot
PDF
今こそクラウドへ!データの移行、連携、統合のコツ
by
株式会社クライム
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
PPT
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
PDF
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
PDF
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
PPTX
Yahoo! JAPANのOracle構成-2017年版
by
Makoto Sato
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
PPTX
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
PDF
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
PDF
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
PDF
Hadoop概要説明
by
Satoshi Noto
PDF
Oracle Cloudで始める、DBエンジニアのためのHadoop超入門(db tech showcase 2016 Oracle セッション資料)
by
オラクルエンジニア通信
PDF
日々進化するHadoopの 「いま」
by
NTT DATA OSS Professional Services
PDF
Kuduを調べてみた #dogenzakalt
by
Toshihiro Suzuki
PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
PDF
MapR と Vertica エンジニアが語る、なぜその組み合わせが最高なのか? - db tech showcase 大阪 2014 2014/06/19
by
MapR Technologies Japan
PPTX
分散グラフデータベース DataStax Enterprise Graph
by
Yuki Morishita
PPTX
Hadoopトレーニング番外編 〜間違えられやすいHadoopの7つの仕様〜
by
Cloudera Japan
PDF
[db tech showcase Tokyo 2017] E23: クラウド異種データベース(AWS)へのデータベース移行時の注意点 ~レプリケーション...
by
Insight Technology, Inc.
今こそクラウドへ!データの移行、連携、統合のコツ
by
株式会社クライム
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
20190314 PGStrom Arrow_Fdw
by
Kohei KaiGai
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
Yahoo! JAPANのOracle構成-2017年版
by
Makoto Sato
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...
by
Insight Technology, Inc.
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
Hadoop概要説明
by
Satoshi Noto
Oracle Cloudで始める、DBエンジニアのためのHadoop超入門(db tech showcase 2016 Oracle セッション資料)
by
オラクルエンジニア通信
日々進化するHadoopの 「いま」
by
NTT DATA OSS Professional Services
Kuduを調べてみた #dogenzakalt
by
Toshihiro Suzuki
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
MapR と Vertica エンジニアが語る、なぜその組み合わせが最高なのか? - db tech showcase 大阪 2014 2014/06/19
by
MapR Technologies Japan
分散グラフデータベース DataStax Enterprise Graph
by
Yuki Morishita
Hadoopトレーニング番外編 〜間違えられやすいHadoopの7つの仕様〜
by
Cloudera Japan
[db tech showcase Tokyo 2017] E23: クラウド異種データベース(AWS)へのデータベース移行時の注意点 ~レプリケーション...
by
Insight Technology, Inc.
Viewers also liked
PDF
SnappyData Overview Slidedeck for Big Data Bellevue
by
SnappyData
PPTX
Thing you didn't know you could do in Spark
by
SnappyData
PDF
いろいろなストリーム処理プロダクトをベンチマークしてみた #hcj2016
by
Yahoo!デベロッパーネットワーク
PPTX
Cassandraのバックアップと運用を考える
by
Kazutaka Tomita
PDF
Apache Kylinについて #hcj2016
by
Yahoo!デベロッパーネットワーク
PDF
Guide to Cassandra for Production Deployments
by
smdkk
PPTX
Apache Geode で始める Spring Data Gemfire
by
Akihiro Kitada
PDF
本当にあったHadoopの恐い話 Blockはどこへきえた? (Hadoop / Spark Conference Japan 2016 ライトニングトー...
by
NTT DATA OSS Professional Services
PPTX
SnappyData, the Spark Database. A unified cluster for streaming, transactions...
by
SnappyData
PDF
僕の考える最強のビックデータエンジニア
by
Yu Yamada
PDF
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
PDF
Hadoop Conference Japan 2013 Winter オープニングスライド
by
hamaken
PDF
Hadoop Conference Japan 2016 LT資料 グラフデータベース事始め
by
オラクルエンジニア通信
PDF
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
PDF
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
PPT
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
PDF
Cassandra導入事例と現場視点での苦労したポイント cassandra summit2014jpn
by
haketa
PPTX
RDBとNoSQLの上手な付き合い方(勉強会@LIG 2013/11/11)
by
Yuji Otani
PPTX
これがCassandra
by
Takehiro Torigaki
PDF
NoSQL3
by
Shinya Kawanaka
SnappyData Overview Slidedeck for Big Data Bellevue
by
SnappyData
Thing you didn't know you could do in Spark
by
SnappyData
いろいろなストリーム処理プロダクトをベンチマークしてみた #hcj2016
by
Yahoo!デベロッパーネットワーク
Cassandraのバックアップと運用を考える
by
Kazutaka Tomita
Apache Kylinについて #hcj2016
by
Yahoo!デベロッパーネットワーク
Guide to Cassandra for Production Deployments
by
smdkk
Apache Geode で始める Spring Data Gemfire
by
Akihiro Kitada
本当にあったHadoopの恐い話 Blockはどこへきえた? (Hadoop / Spark Conference Japan 2016 ライトニングトー...
by
NTT DATA OSS Professional Services
SnappyData, the Spark Database. A unified cluster for streaming, transactions...
by
SnappyData
僕の考える最強のビックデータエンジニア
by
Yu Yamada
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
Hadoop Conference Japan 2013 Winter オープニングスライド
by
hamaken
Hadoop Conference Japan 2016 LT資料 グラフデータベース事始め
by
オラクルエンジニア通信
RDB技術者のためのNoSQLガイド NoSQLの必要性と位置づけ
by
Recruit Technologies
NetflixにおけるPresto/Spark活用事例
by
Amazon Web Services Japan
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
Cassandra導入事例と現場視点での苦労したポイント cassandra summit2014jpn
by
haketa
RDBとNoSQLの上手な付き合い方(勉強会@LIG 2013/11/11)
by
Yuji Otani
これがCassandra
by
Takehiro Torigaki
NoSQL3
by
Shinya Kawanaka
Similar to (LT)Spark and Cassandra
PDF
[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...
by
Insight Technology, Inc.
PPTX
Cassandra Meetup Tokyo, 2016 Spring
by
datastaxjp
PPT
Cassandra v0.6-siryou
by
あしたのオープンソース研究所
PDF
Db tech showcase 2016
by
datastaxjp
PDF
Cassandra Meetup Tokyo, 2016 Spring
by
Shigeru Harasawa
PPTX
Apache cassandraと apache sparkで作るデータ解析プラットフォーム
by
Kazutaka Tomita
PPTX
事例で学ぶApache Cassandra
by
Yuki Morishita
PDF
PostgreSQLのHTAP適応について考える (PostgreSQL Conference Japan 2024 講演資料)
by
NTT DATA Technology & Innovation
DOC
cassandra調査レポート
by
Akihiro Kuwano
PDF
db tech showcase2019 オープニングセッション @ 石川 雅也
by
Insight Technology, Inc.
PDF
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
PDF
NoSQLとビックデータ入門編Update版
by
Koichiro Nishijima
PPTX
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006
by
Cloudera Japan
PDF
Datastax Enterpriseをはじめよう
by
Yuki Morishita
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PDF
社会ネットワーク分析第7回
by
Satoru Mikami
PDF
Spark徹底入門 #cwt2015
by
Cloudera Japan
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
PDF
個人的にAmazon EMR5.0.0でSpark 2.0を使ってZeppelinでSQL集計してみる
by
Eiji Shinohara
[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...
by
Insight Technology, Inc.
Cassandra Meetup Tokyo, 2016 Spring
by
datastaxjp
Cassandra v0.6-siryou
by
あしたのオープンソース研究所
Db tech showcase 2016
by
datastaxjp
Cassandra Meetup Tokyo, 2016 Spring
by
Shigeru Harasawa
Apache cassandraと apache sparkで作るデータ解析プラットフォーム
by
Kazutaka Tomita
事例で学ぶApache Cassandra
by
Yuki Morishita
PostgreSQLのHTAP適応について考える (PostgreSQL Conference Japan 2024 講演資料)
by
NTT DATA Technology & Innovation
cassandra調査レポート
by
Akihiro Kuwano
db tech showcase2019 オープニングセッション @ 石川 雅也
by
Insight Technology, Inc.
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
NoSQLとビックデータ入門編Update版
by
Koichiro Nishijima
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006
by
Cloudera Japan
Datastax Enterpriseをはじめよう
by
Yuki Morishita
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
社会ネットワーク分析第7回
by
Satoru Mikami
Spark徹底入門 #cwt2015
by
Cloudera Japan
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
個人的にAmazon EMR5.0.0でSpark 2.0を使ってZeppelinでSQL集計してみる
by
Eiji Shinohara
More from datastaxjp
PPTX
Cassandra Meetup Tokyo, 2016 Spring 2
by
datastaxjp
PDF
検索エンジンPatheeがAzureとCassandraをどう利用しているのか
by
datastaxjp
PDF
Cassandra v3.0 at Rakuten meet-up on 12/2/2015
by
datastaxjp
PDF
Investigation of Transactions in Cassandra
by
datastaxjp
PDF
Cassandra summit 2015 レポート
by
datastaxjp
PDF
Cassandra Meetup Tokyo, 2015 Summer
by
datastaxjp
PDF
Cassandra and Spark
by
datastaxjp
PDF
[Cassandra summit Tokyo, 2015] Apache Cassandra日本人コミッターが伝える、"Apache Cassandra...
by
datastaxjp
PDF
[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)
by
datastaxjp
PDF
[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう
by
datastaxjp
PDF
[db tech showcase Tokyo 2015] A27: RDBエンジニアの為のNOSQL, 今どうしてNOSQLなのか?
by
datastaxjp
Cassandra Meetup Tokyo, 2016 Spring 2
by
datastaxjp
検索エンジンPatheeがAzureとCassandraをどう利用しているのか
by
datastaxjp
Cassandra v3.0 at Rakuten meet-up on 12/2/2015
by
datastaxjp
Investigation of Transactions in Cassandra
by
datastaxjp
Cassandra summit 2015 レポート
by
datastaxjp
Cassandra Meetup Tokyo, 2015 Summer
by
datastaxjp
Cassandra and Spark
by
datastaxjp
[Cassandra summit Tokyo, 2015] Apache Cassandra日本人コミッターが伝える、"Apache Cassandra...
by
datastaxjp
[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)
by
datastaxjp
[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう
by
datastaxjp
[db tech showcase Tokyo 2015] A27: RDBエンジニアの為のNOSQL, 今どうしてNOSQLなのか?
by
datastaxjp
Recently uploaded
PDF
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
PDF
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
PPTX
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
PDF
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
PDF
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
by
NTT DATA Technology & Innovation
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
by
PC Cluster Consortium
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
by
Sugiyama Yugo
DrupalCon Nara 2025の記録 .
by
iPride Co., Ltd.
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
by
たけおか しょうぞう
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
by
TomohiroKusu
(LT)Spark and Cassandra
1.
©2015 DataStax Confidential.
Do not distribute without consent. 1 DataStax 原沢滋 Apache Sparkがリアルタイム分析で NOSQLのApache Cassandraに出会った。(ウルルン風) Hadoop / Spark Conference Japan 2016
2.
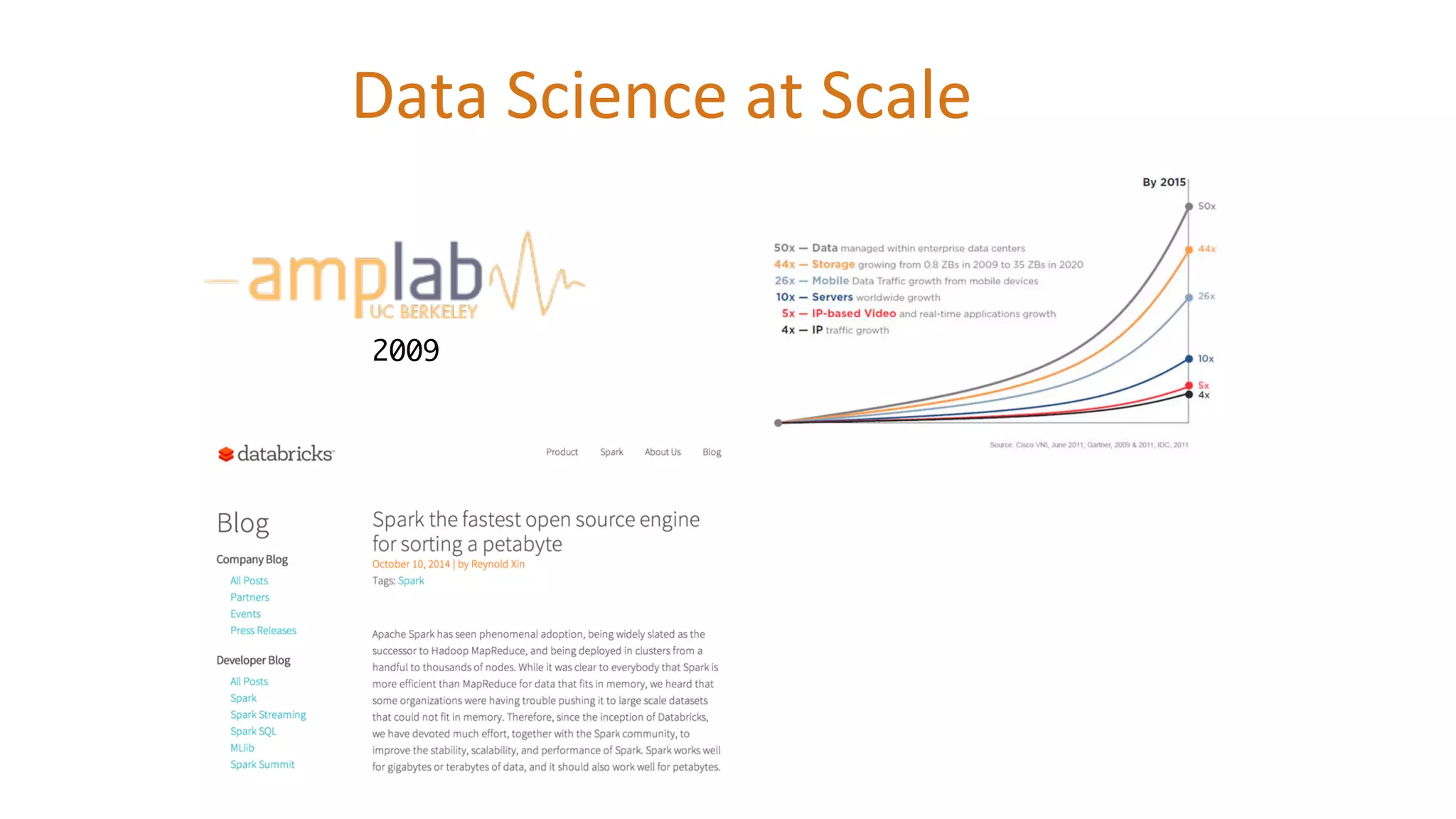
Data Science at
Scale 2009
3.
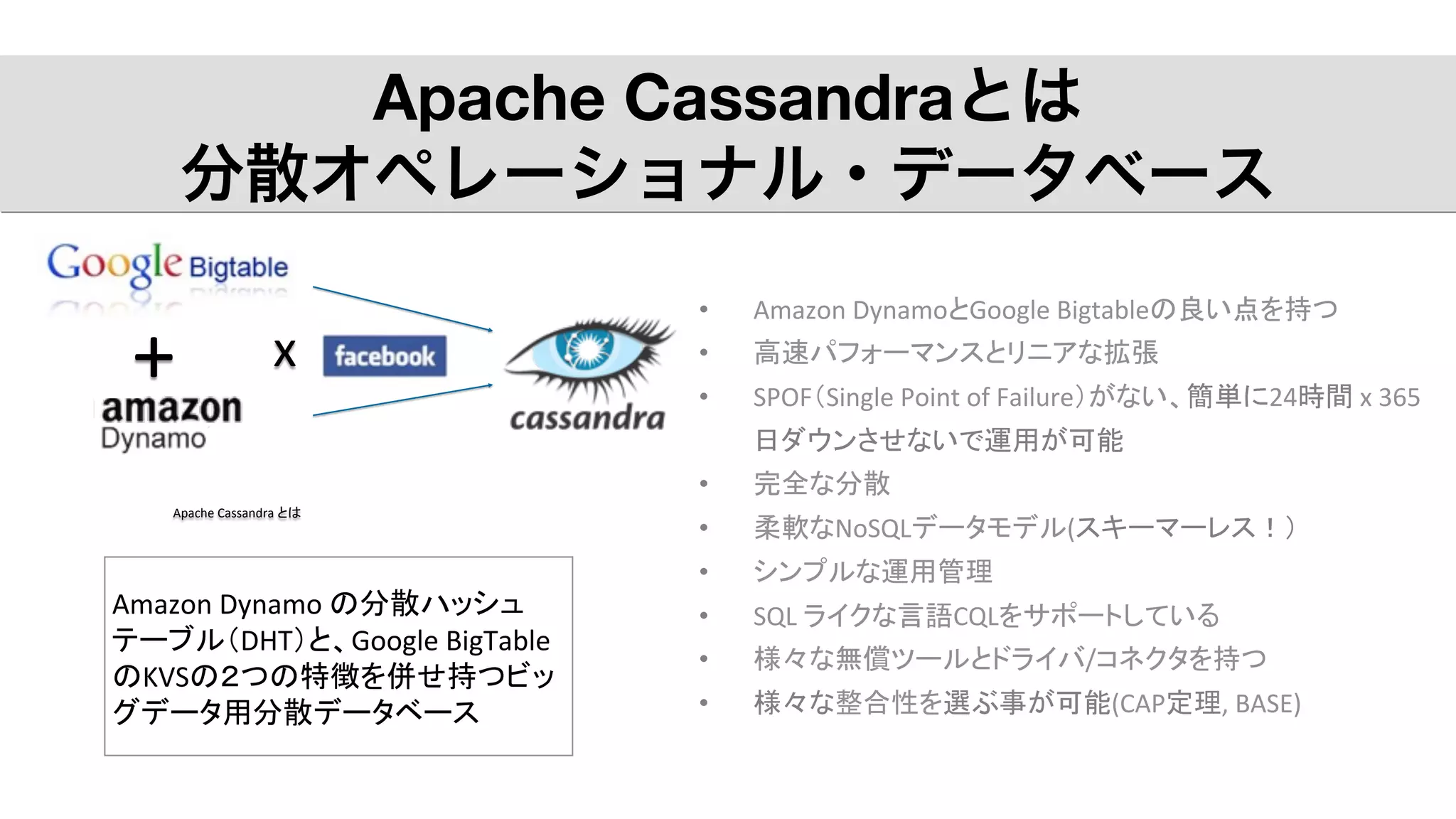
x Apache Cassandraとは 分散オペレーショナル・データベース Apache Cassandra
とは Amazon Dynamo の分散ハッシュ テーブル(DHT)と、Google BigTable のKVSの2つの特徴を併せ持つビッ グデータ用分散データベース • Amazon DynamoとGoogle Bigtableの良い点を持つ • 高速パフォーマンスとリニアな拡張 • SPOF(Single Point of Failure)がない、簡単に24時間 x 365 日ダウンさせないで運用が可能 • 完全な分散 • 柔軟なNoSQLデータモデル(スキーマーレス!) • シンプルな運用管理 • SQL ライクな言語CQLをサポートしている • 様々な無償ツールとドライバ/コネクタを持つ • 様々な整合性を選ぶ事が可能(CAP定理, BASE) +
4.
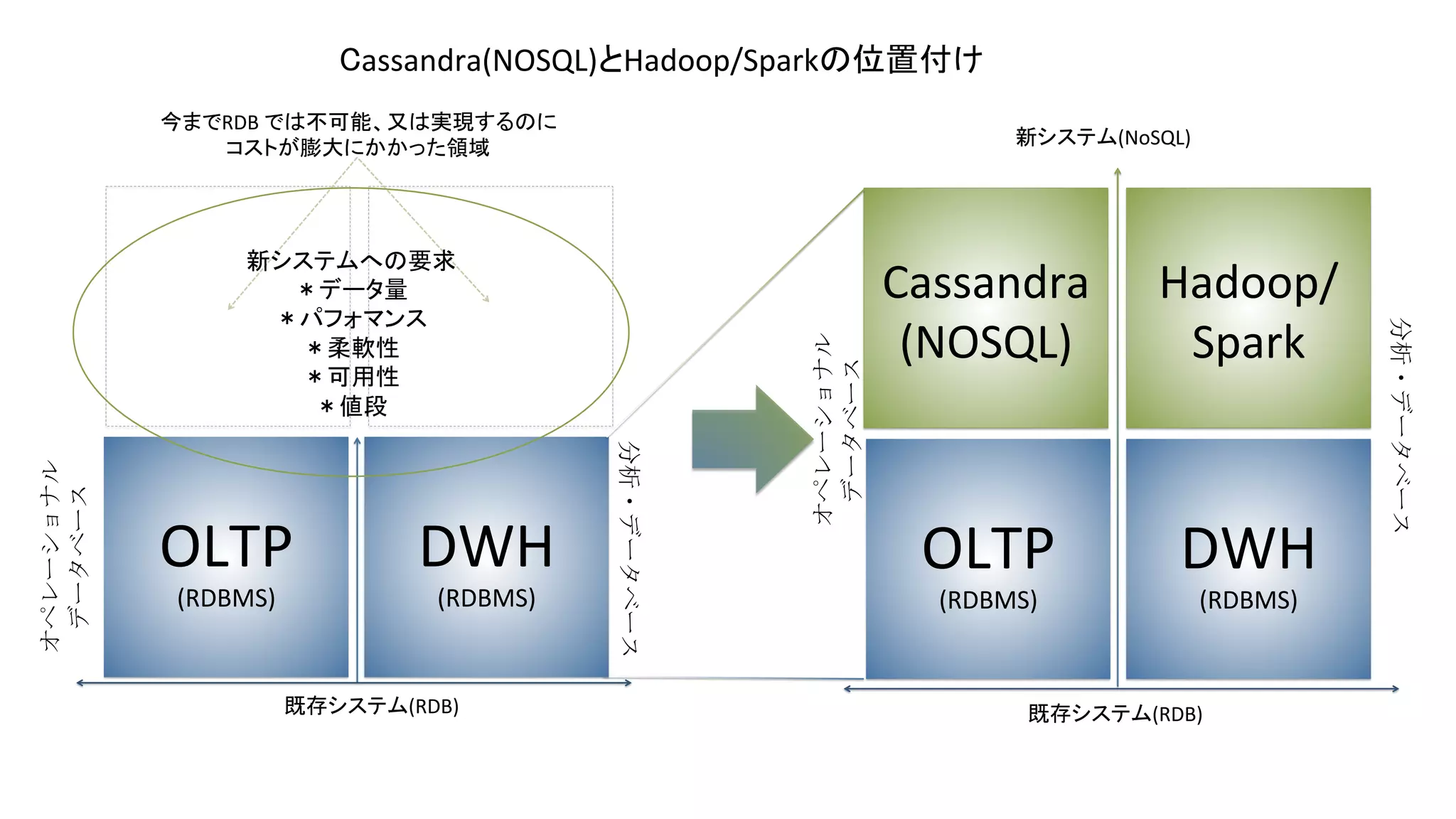
OLTP (RDBMS)
DWH (RDBMS) Cassandra (NOSQL) OLTP (RDBMS) DWH (RDBMS) Hadoop/ Spark 分析・データベース オペレーショナル データベース 既存システム(RDB) 新システムへの要求 *データ量 *パフォマンス *柔軟性 *可用性 *値段 分析・データベース オペレーショナル データベース 既存システム(RDB) 新システム(NoSQL) 今までRDB では不可能、又は実現するのに コストが膨大にかかった領域 Cassandra(NOSQL)とHadoop/Sparkの位置付け
5.
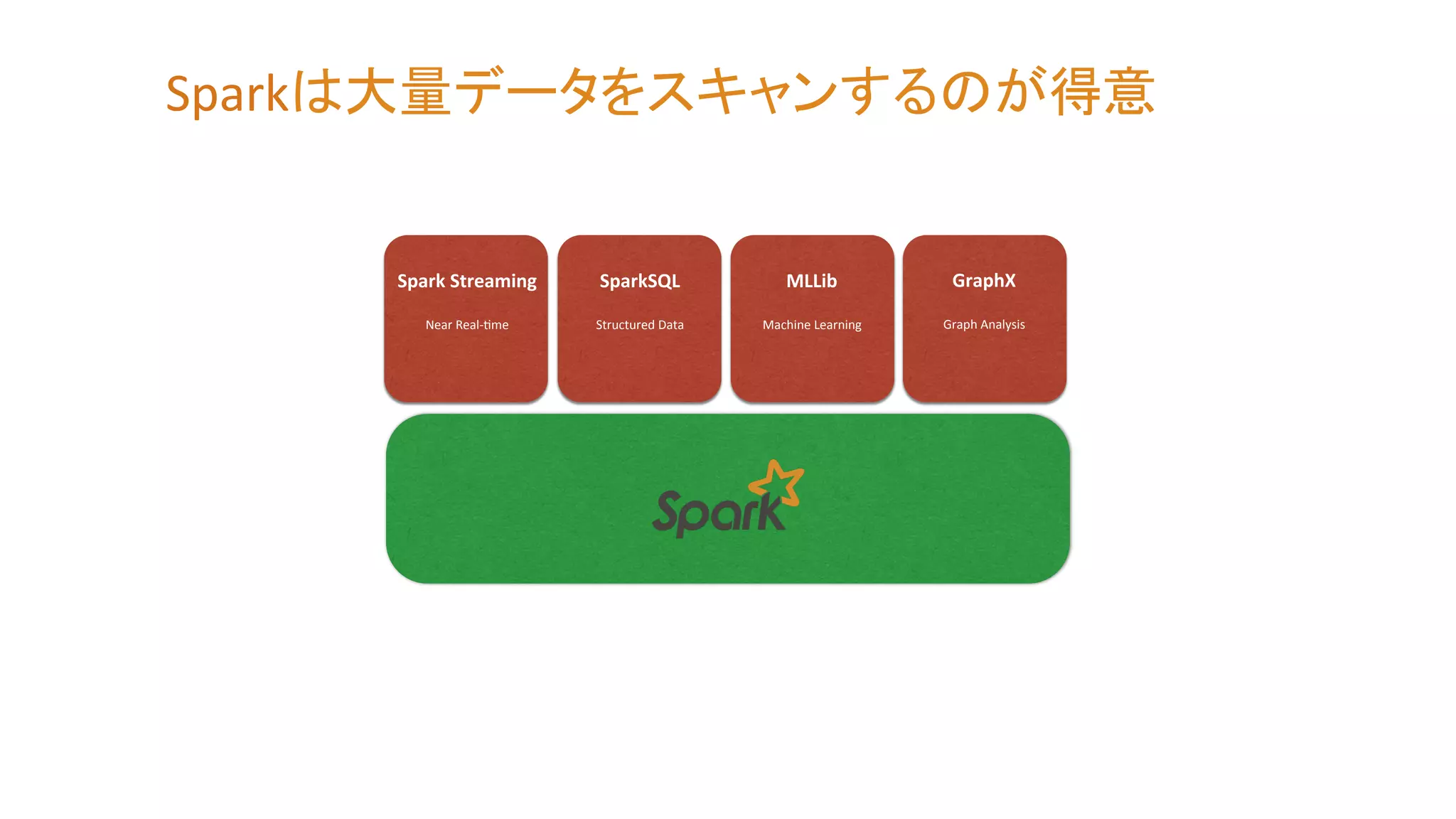
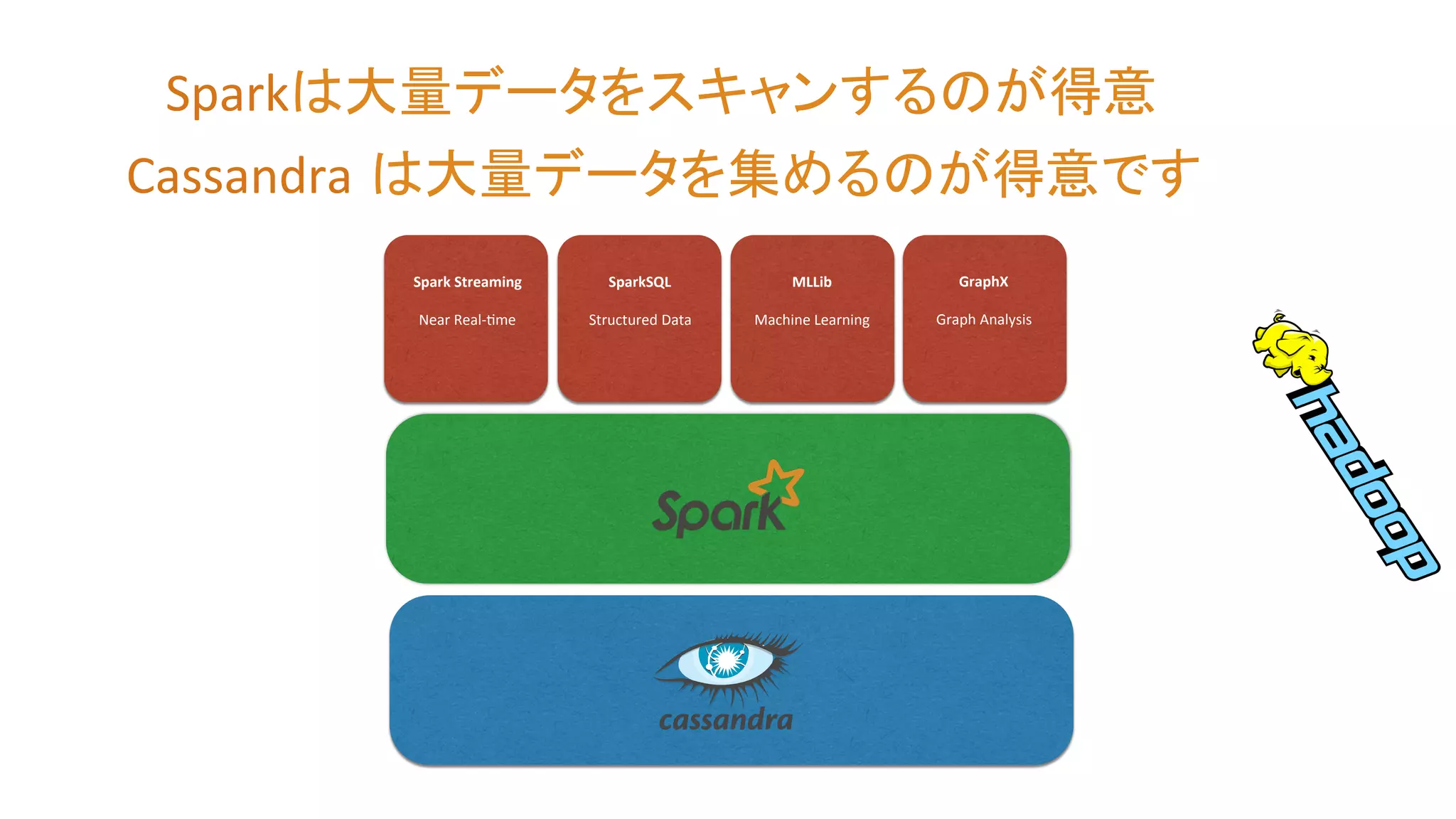
Spark Streaming
Near Real-‐Zme SparkSQL Structured Data MLLib Machine Learning GraphX Graph Analysis Sparkは大量データをスキャンするのが得意
6.
CREATE TABLE raw_weather_data
(! wsid text, ! year int, ! month int, ! day int, ! hour int, ! temperature double, ! dewpoint double, ! pressure double, ! wind_direction int, ! wind_speed double, ! sky_condition int, ! sky_condition_text text, ! one_hour_precip double, ! six_hour_precip double, ! PRIMARY KEY ((wsid), year, month, day, hour)! ) WITH CLUSTERING ORDER BY (year DESC, month DESC, day DESC, hour DESC);! Cassandra は大量データを集めるのが得意です
7.
Spark Streaming
Near Real-‐Zme SparkSQL Structured Data MLLib Machine Learning GraphX Graph Analysis Cassandra は大量データを集めるのが得意です Sparkは大量データをスキャンするのが得意
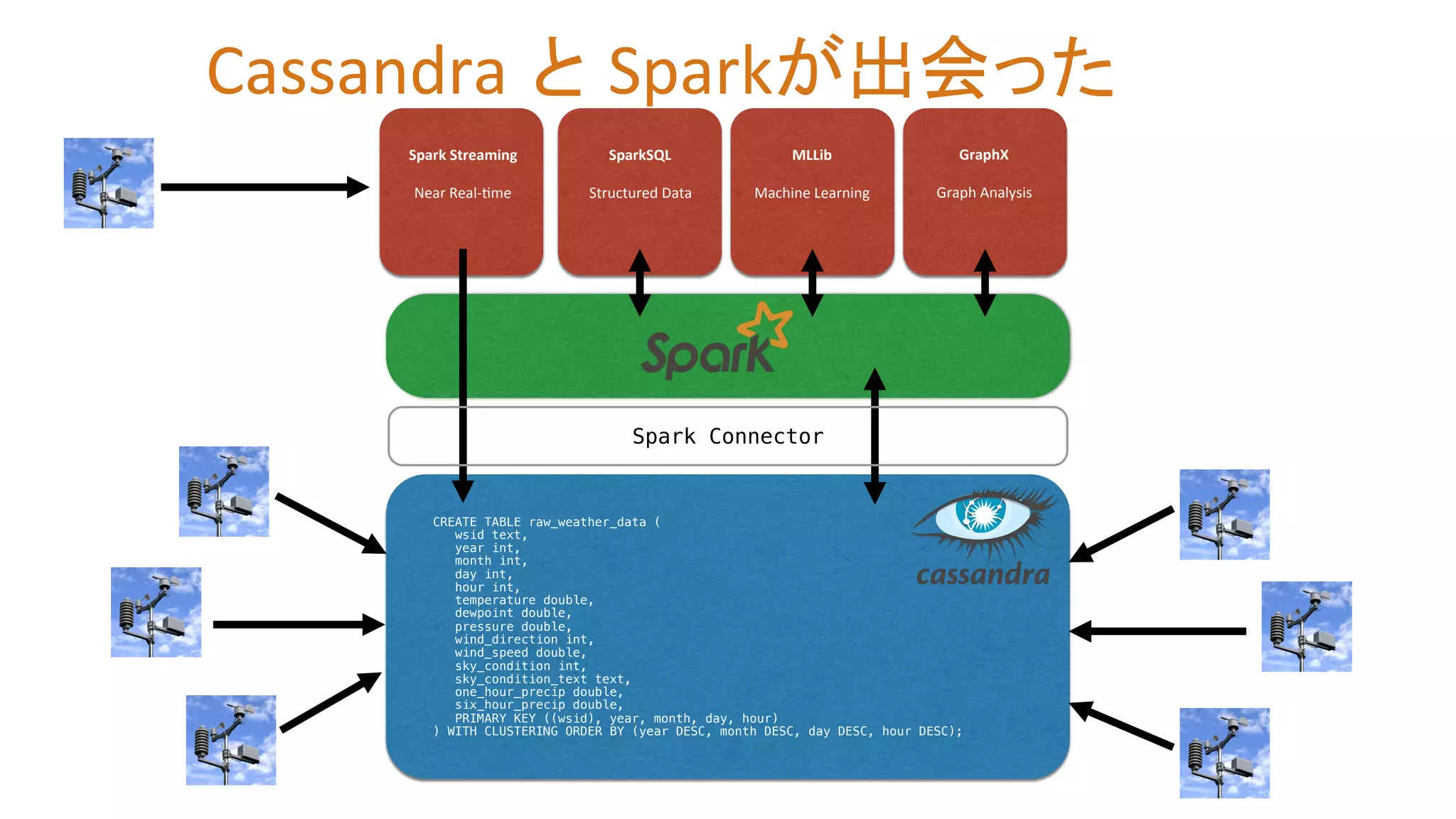
8.
Spark Streaming
Near Real-‐Zme SparkSQL Structured Data MLLib Machine Learning GraphX Graph Analysis CREATE TABLE raw_weather_data (! wsid text, ! year int, ! month int, ! day int, ! hour int, ! temperature double, ! dewpoint double, ! pressure double, ! wind_direction int, ! wind_speed double, ! sky_condition int, ! sky_condition_text text, ! one_hour_precip double, ! six_hour_precip double, ! PRIMARY KEY ((wsid), year, month, day, hour)! ) WITH CLUSTERING ORDER BY (year DESC, month DESC, day DESC, hour DESC);! Spark Connector! Cassandra と Sparkが出会った
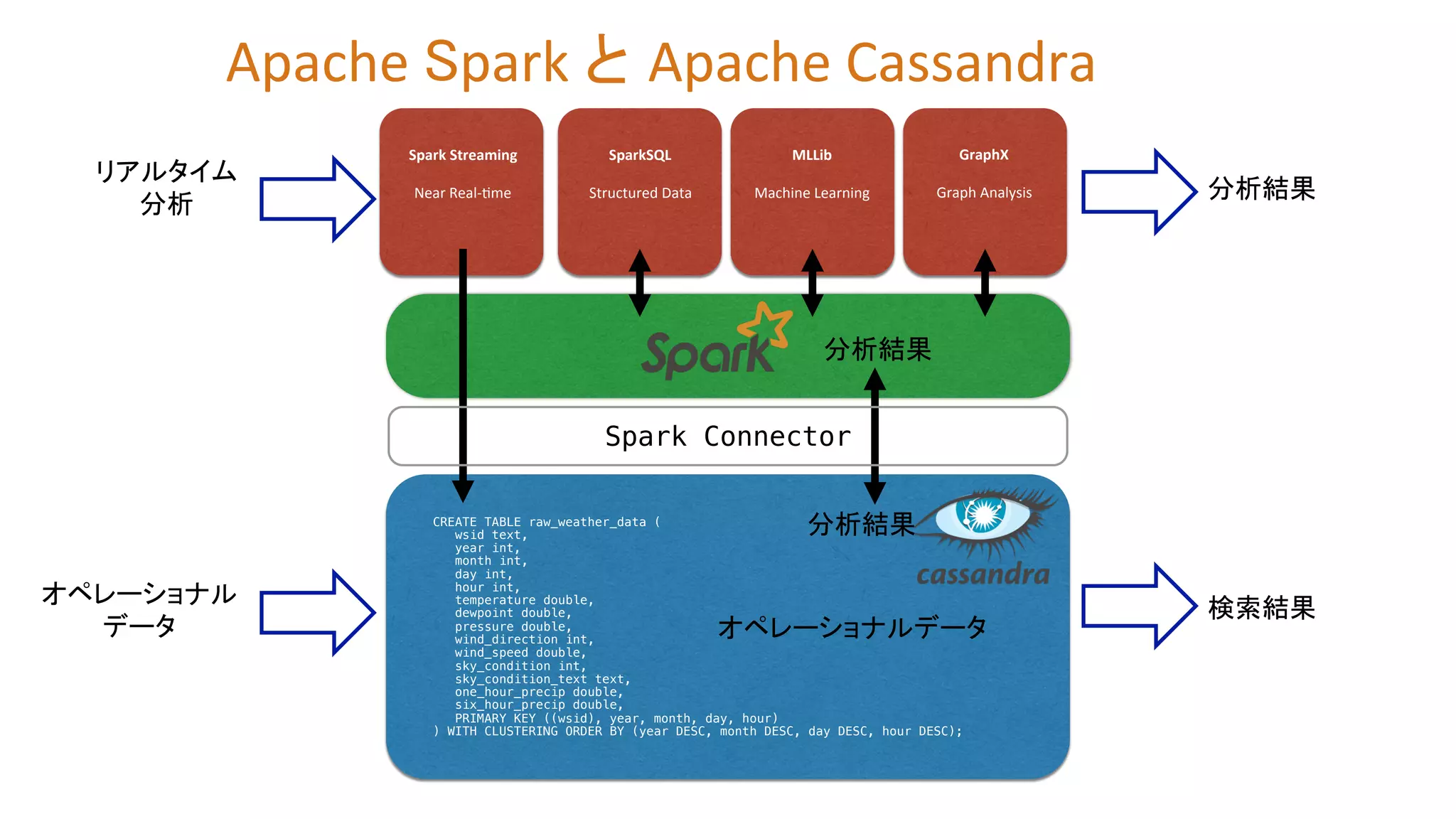
9.
Spark Streaming
Near Real-‐Zme SparkSQL Structured Data MLLib Machine Learning GraphX Graph Analysis CREATE TABLE raw_weather_data (! wsid text, ! year int, ! month int, ! day int, ! hour int, ! temperature double, ! dewpoint double, ! pressure double, ! wind_direction int, ! wind_speed double, ! sky_condition int, ! sky_condition_text text, ! one_hour_precip double, ! six_hour_precip double, ! PRIMARY KEY ((wsid), year, month, day, hour)! ) WITH CLUSTERING ORDER BY (year DESC, month DESC, day DESC, hour DESC);! Spark Connector! リアルタイム 分析 オペレーショナル データ 分析結果 検索結果 分析結果 分析結果 オペレーショナルデータ Apache Spark と Apache Cassandra
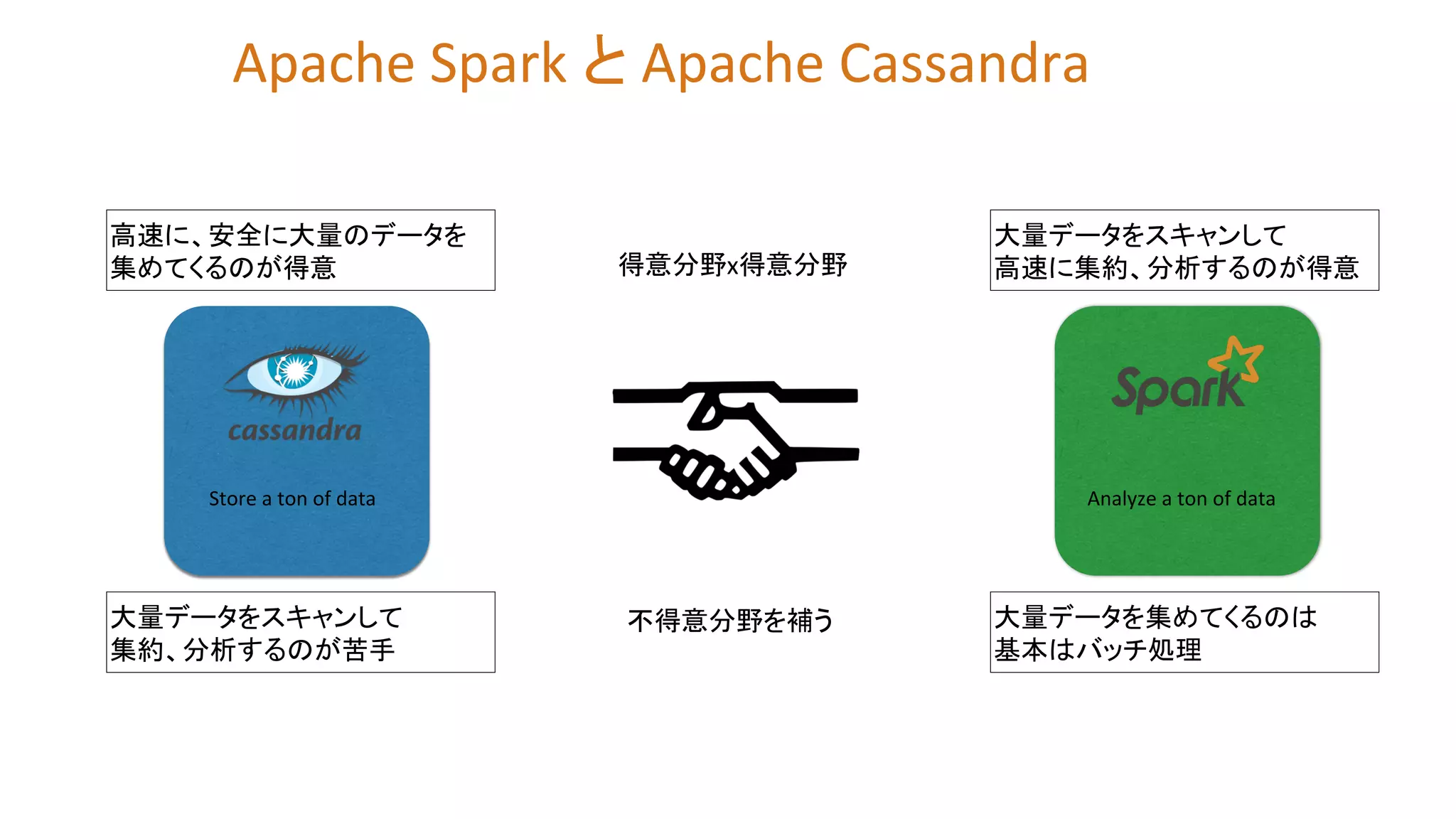
10.
Store a ton
of data Analyze a ton of data Apache Spark と Apache Cassandra 大量データをスキャンして 高速に集約、分析するのが得意 大量データをスキャンして 集約、分析するのが苦手 高速に、安全に大量のデータを 集めてくるのが得意 大量データを集めてくるのは 基本はバッチ処理 得意分野x得意分野 不得意分野を補う
11.
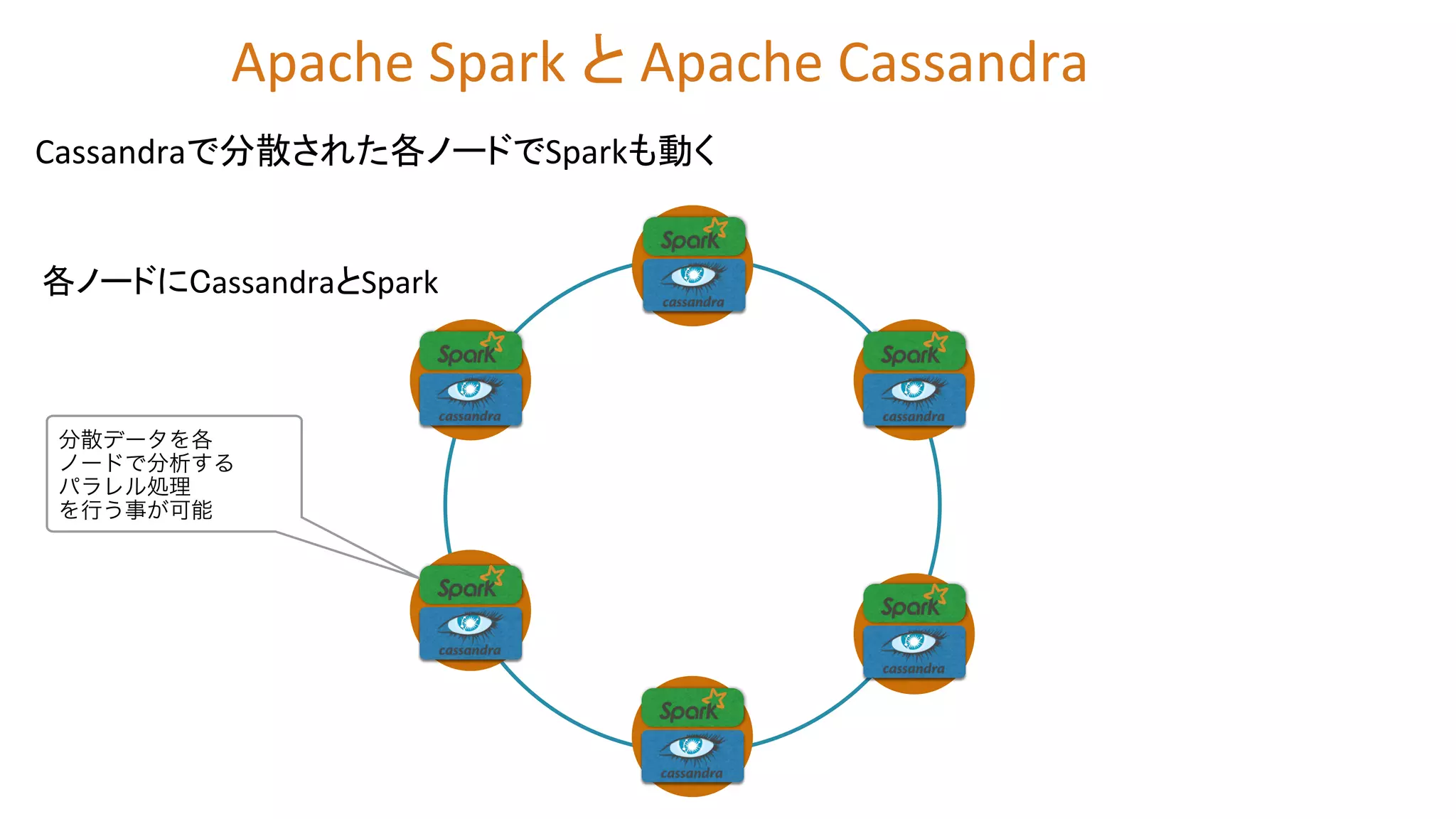
Cassandraで分散された各ノードでSparkも動く 分散データを各 ノードで分析する パラレル処理 を行う事が可能 各ノードにCassandraとSpark Apache
Spark と Apache Cassandra
12.
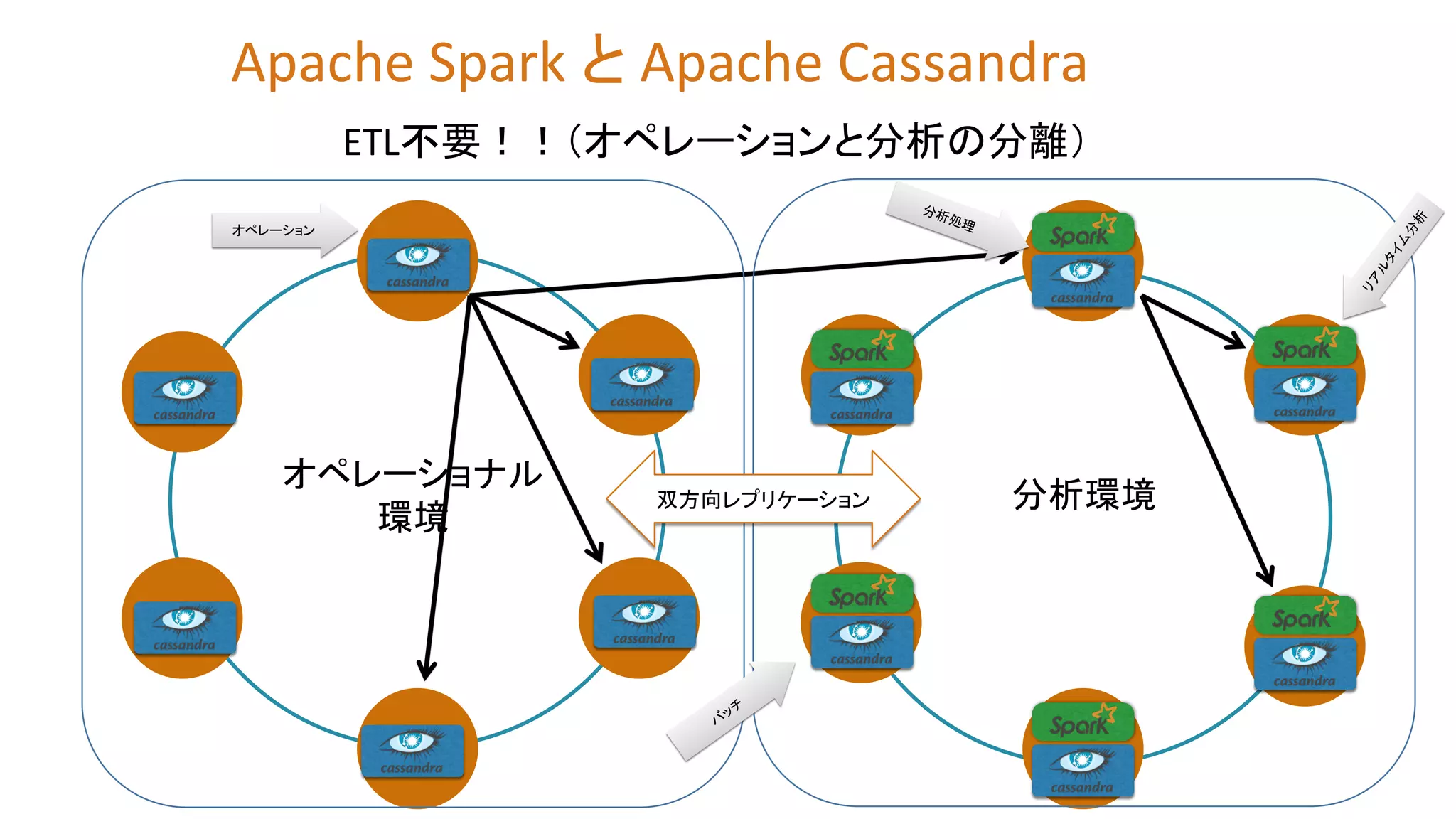
ETL不要!!(オペレーションと分析の分離) オペレーション オペレーショナル
環境 分析環境 双方向レプリケーション Apache Spark と Apache Cassandra
13.
SPARK Cassandra Connector h[ps://github.com/datastax/spark-‐cassandra-‐connector
14.
©2015 DataStax Confidential.
Do not distribute without consent. ありがとうございました! Twi[er account: @cassandrajapanで情報発信しています





















![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)









![[db tech showcase Tokyo 2017] E23: クラウド異種データベース(AWS)へのデータベース移行時の注意点 ~レプリケーション...](https://cdn.slidesharecdn.com/ss_thumbnails/e23-170912023826-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014l32datastaxapachecassandraiotbigdatanosql-141120022255-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[Cassandra summit Tokyo, 2015] Apache Cassandra日本人コミッターが伝える、"Apache Cassandra...](https://cdn.slidesharecdn.com/ss_thumbnails/cassandra-summit-tokyo-2015-yuki-150624053034-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう](https://cdn.slidesharecdn.com/ss_thumbnails/e35cassandra-150624022814-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A27: RDBエンジニアの為のNOSQL, 今どうしてNOSQLなのか?](https://cdn.slidesharecdn.com/ss_thumbnails/a27nosqlforrdbengineer-150624020431-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





