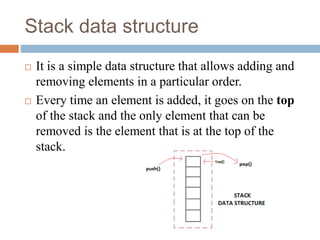
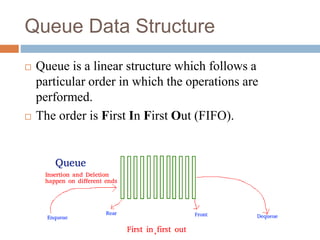
The document details the analysis of time complexity concerning queue and stack data structures, explaining their operations and performance. Queue operations like enqueue and dequeue are compared based on implementations using arrays and linked lists, while stack operations push and pop are examined similarly. The analysis highlights that both data structures offer efficient O(1) operations under certain conditions, contrasting with O(n) complexities for specific scenarios.







![Queue implemented as array
Array elements are stored contiguously in memory,
so the time required to compute the memory
address of an array element arr[k] is independent of
the array’s size.
So, storing and retrieving array elements are O(1)
operations.](https://image.slidesharecdn.com/06gauravkumar-200413102918/85/Study-Analysis-of-Complexities-of-Stack-Queue-Operations-in-Data-Structure-8-320.jpg)