Downloaded 88 times

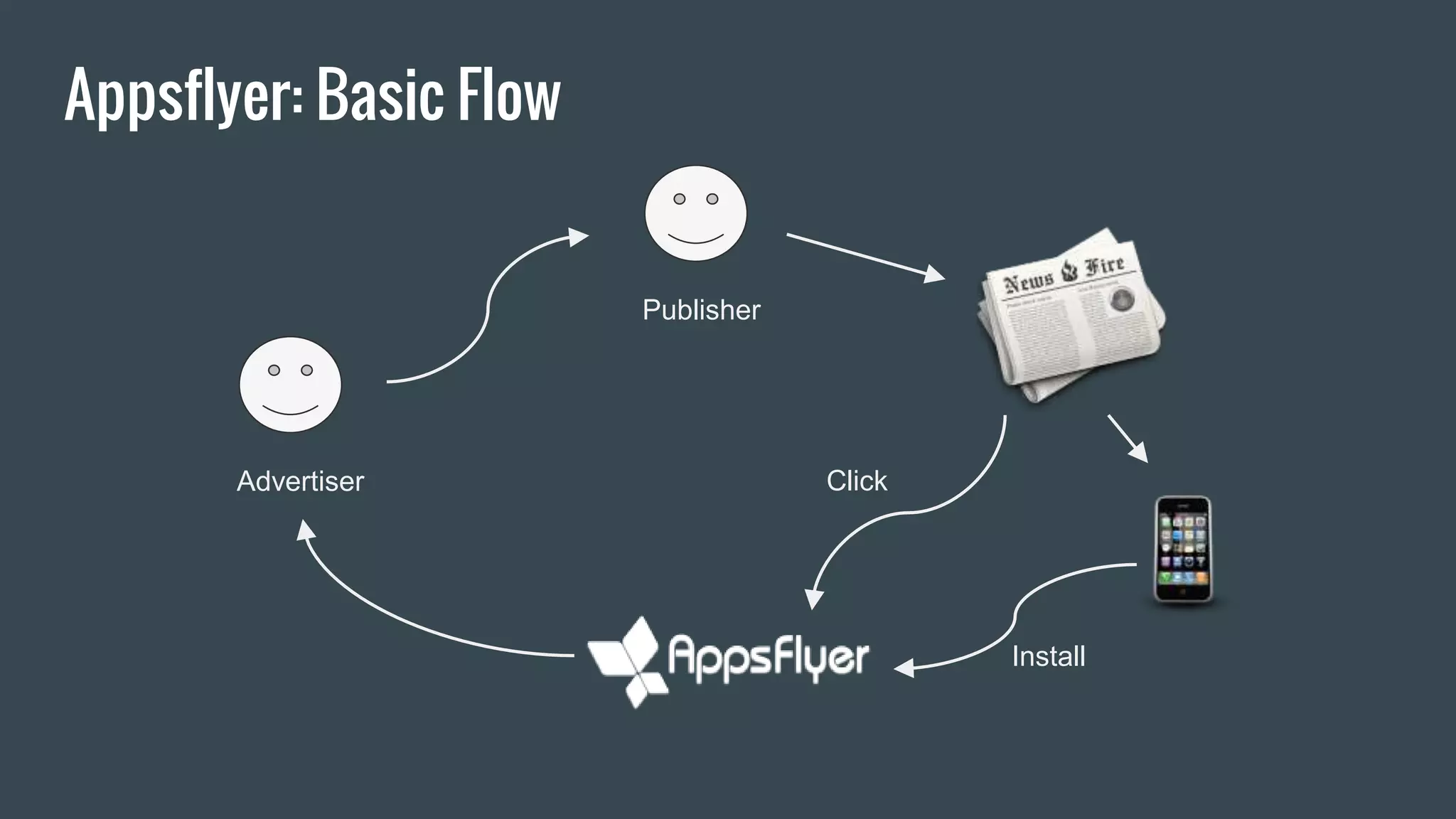

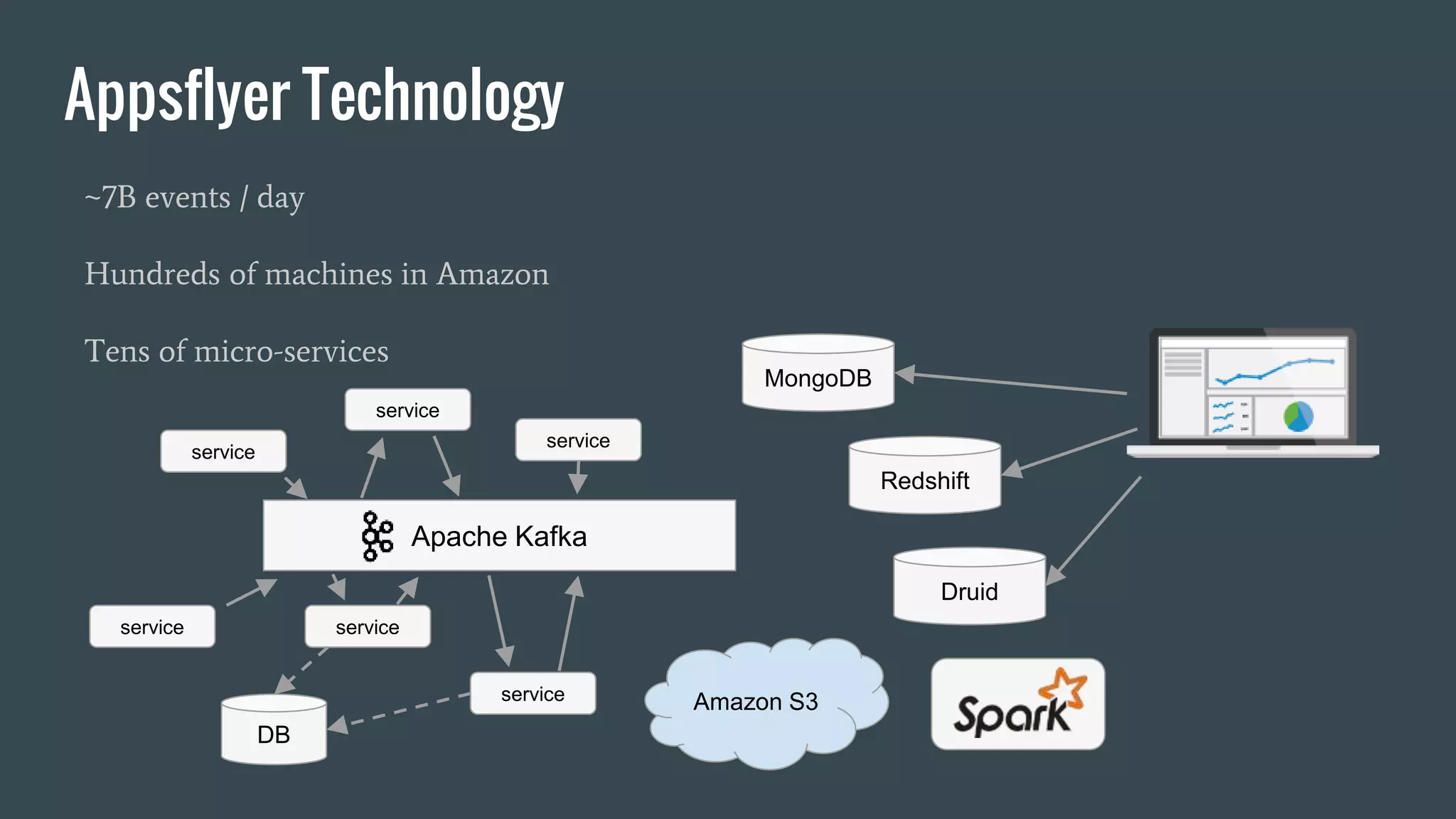

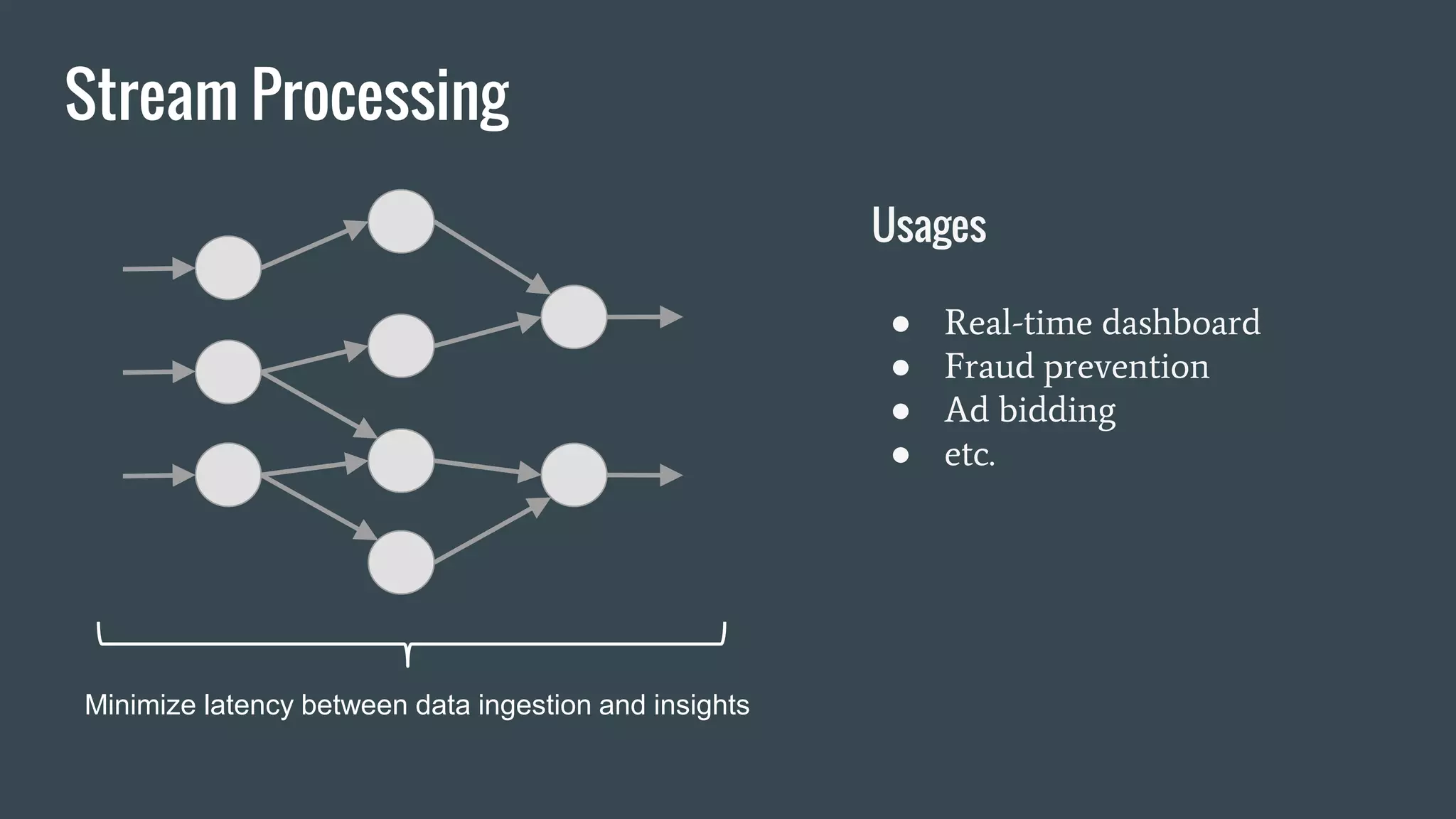
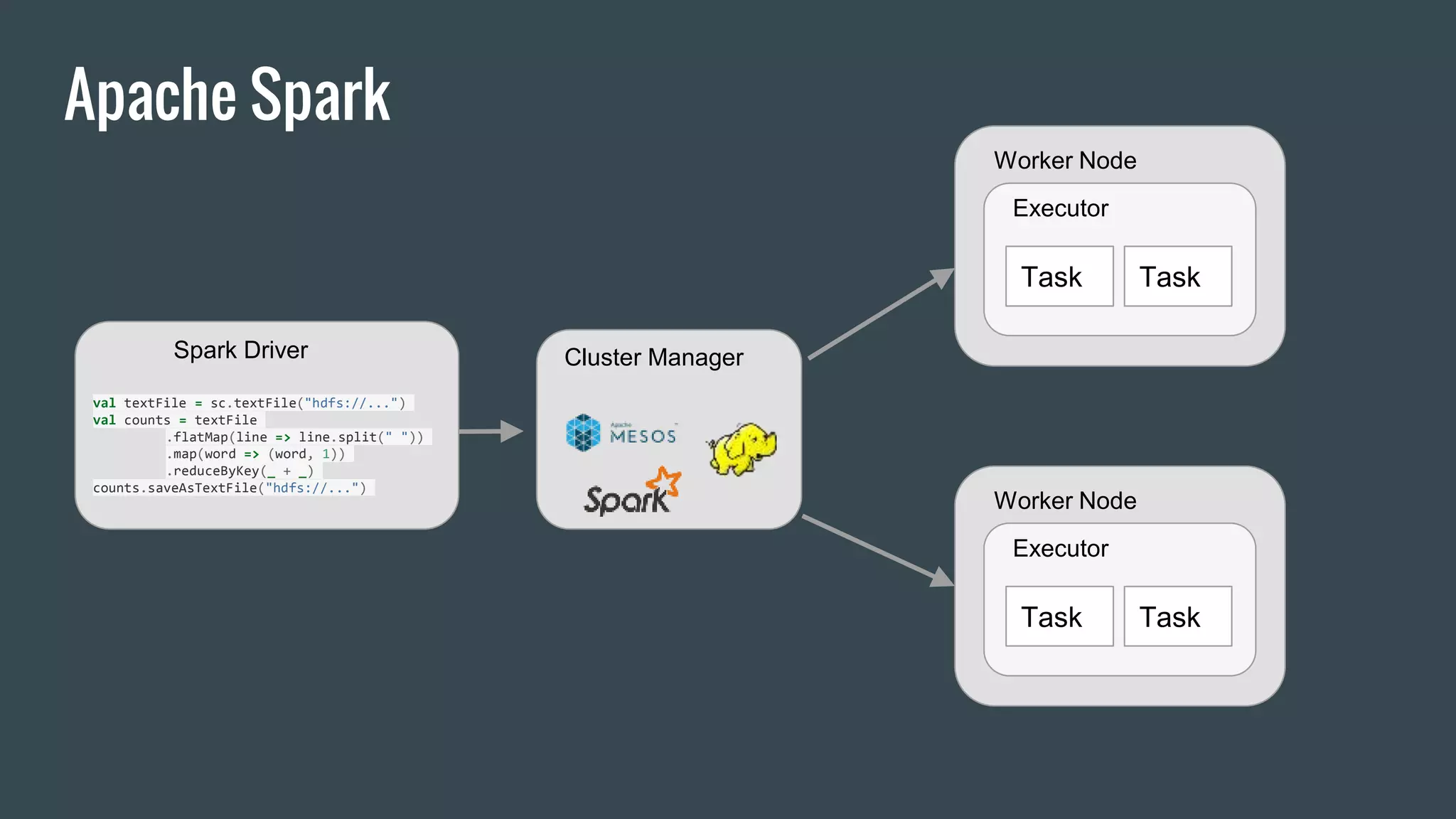
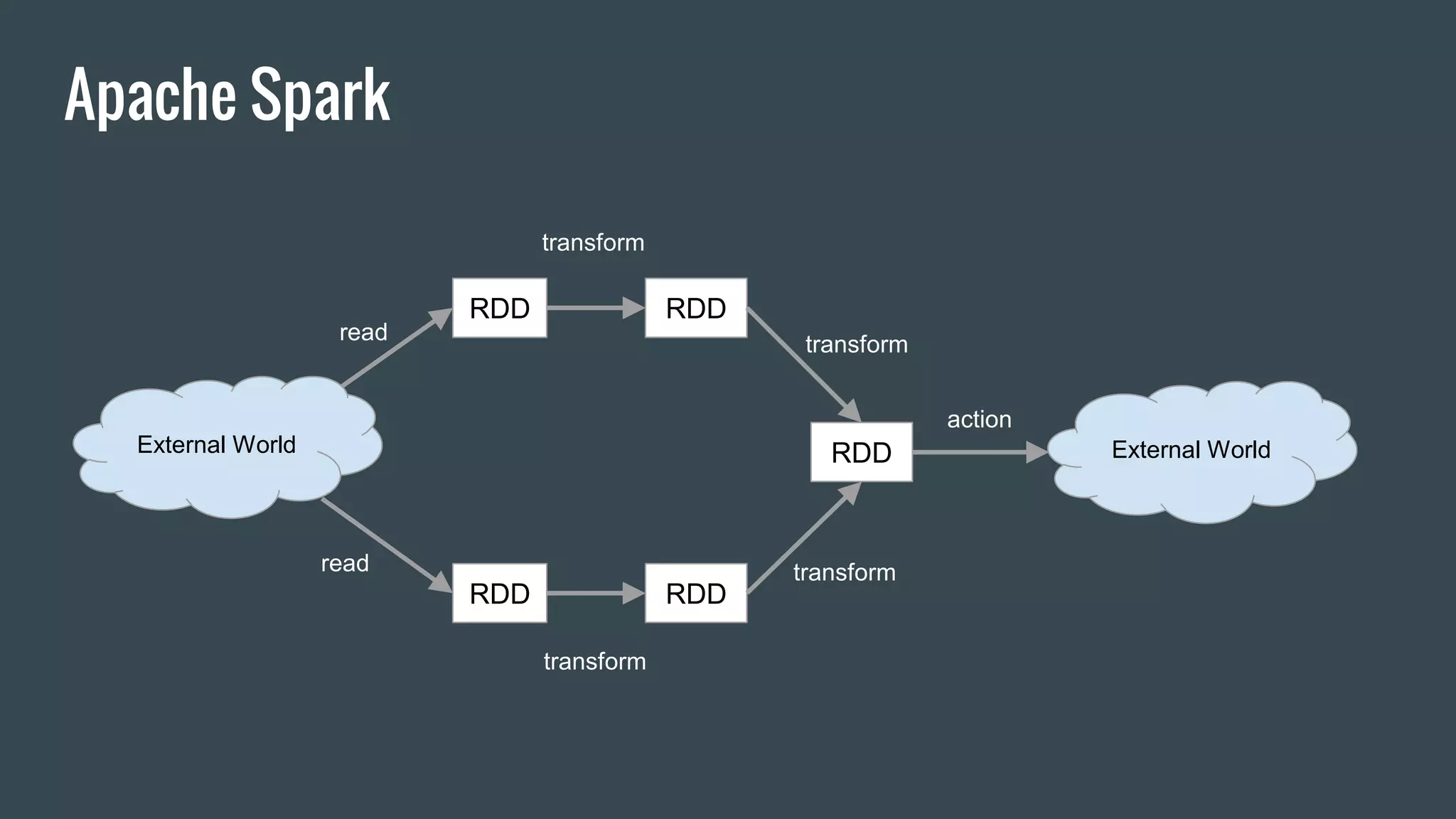
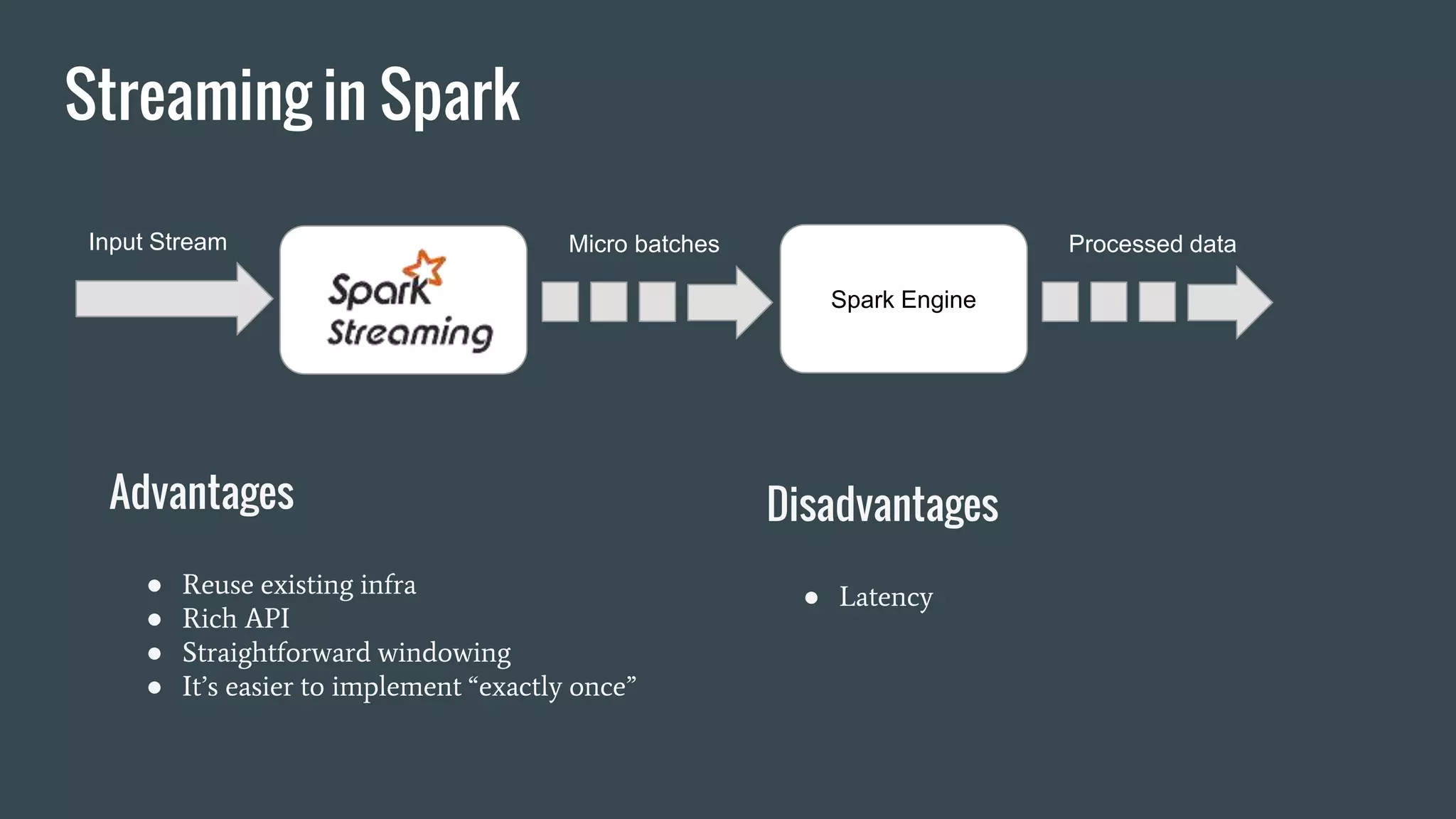
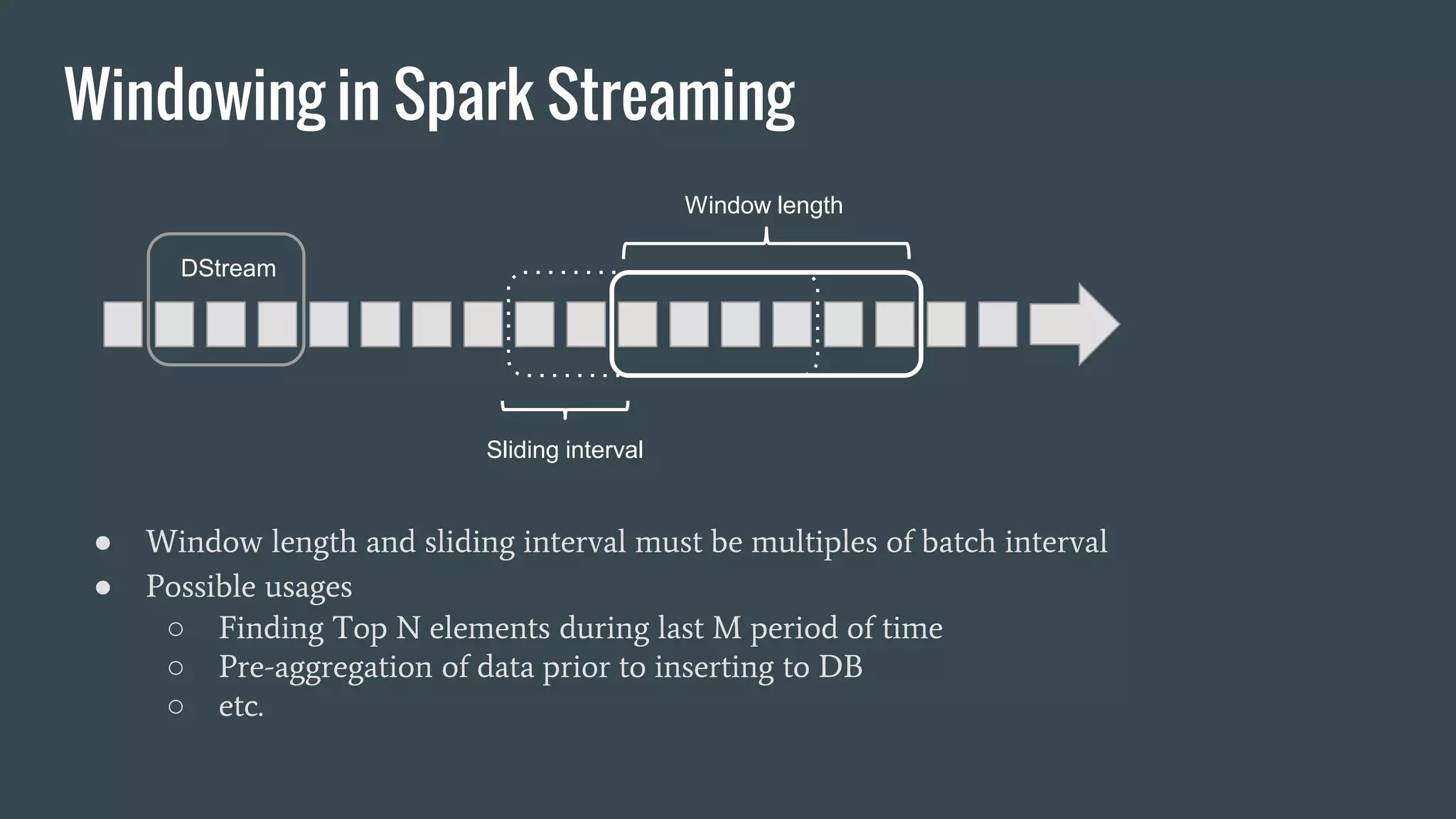

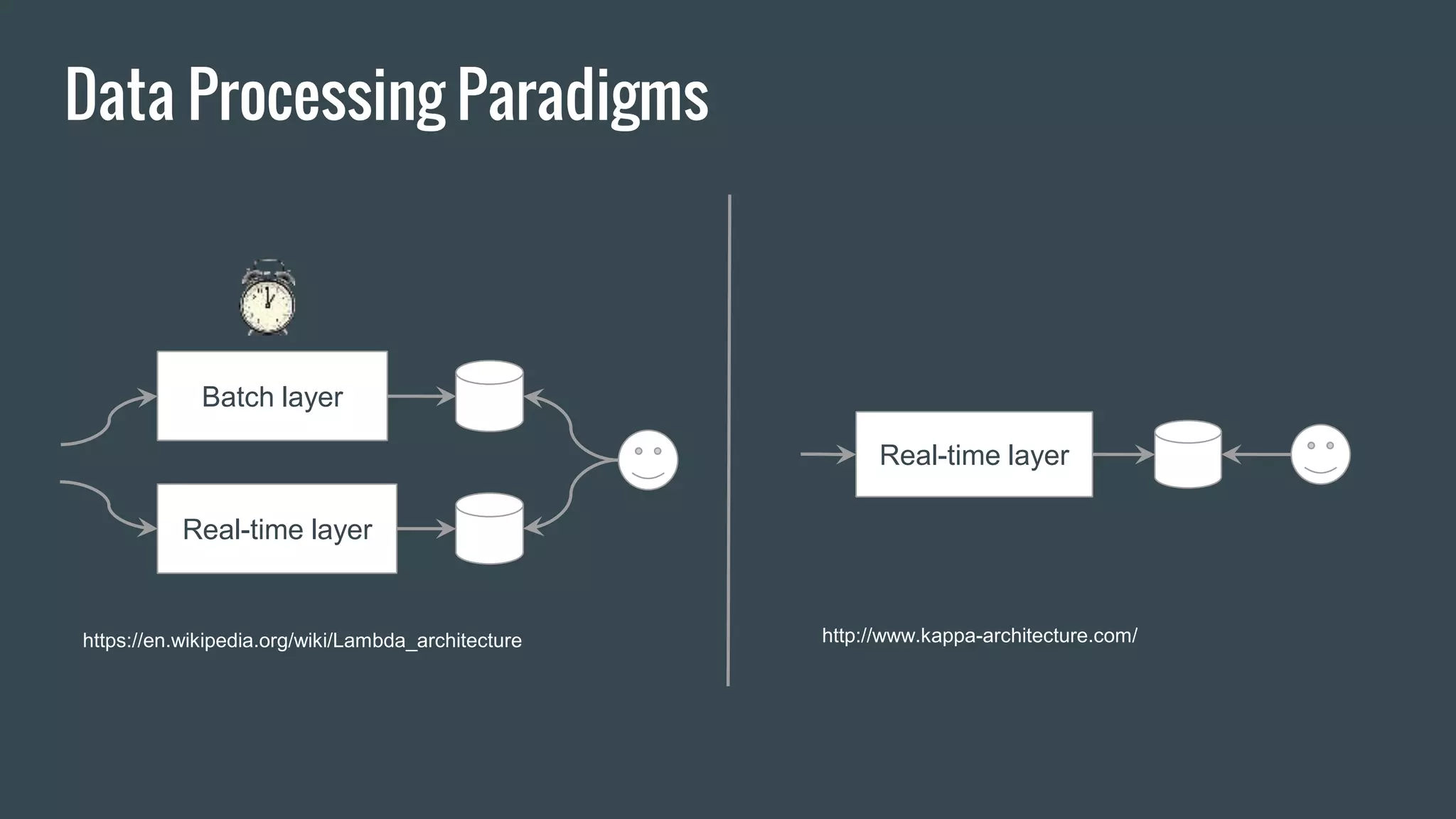


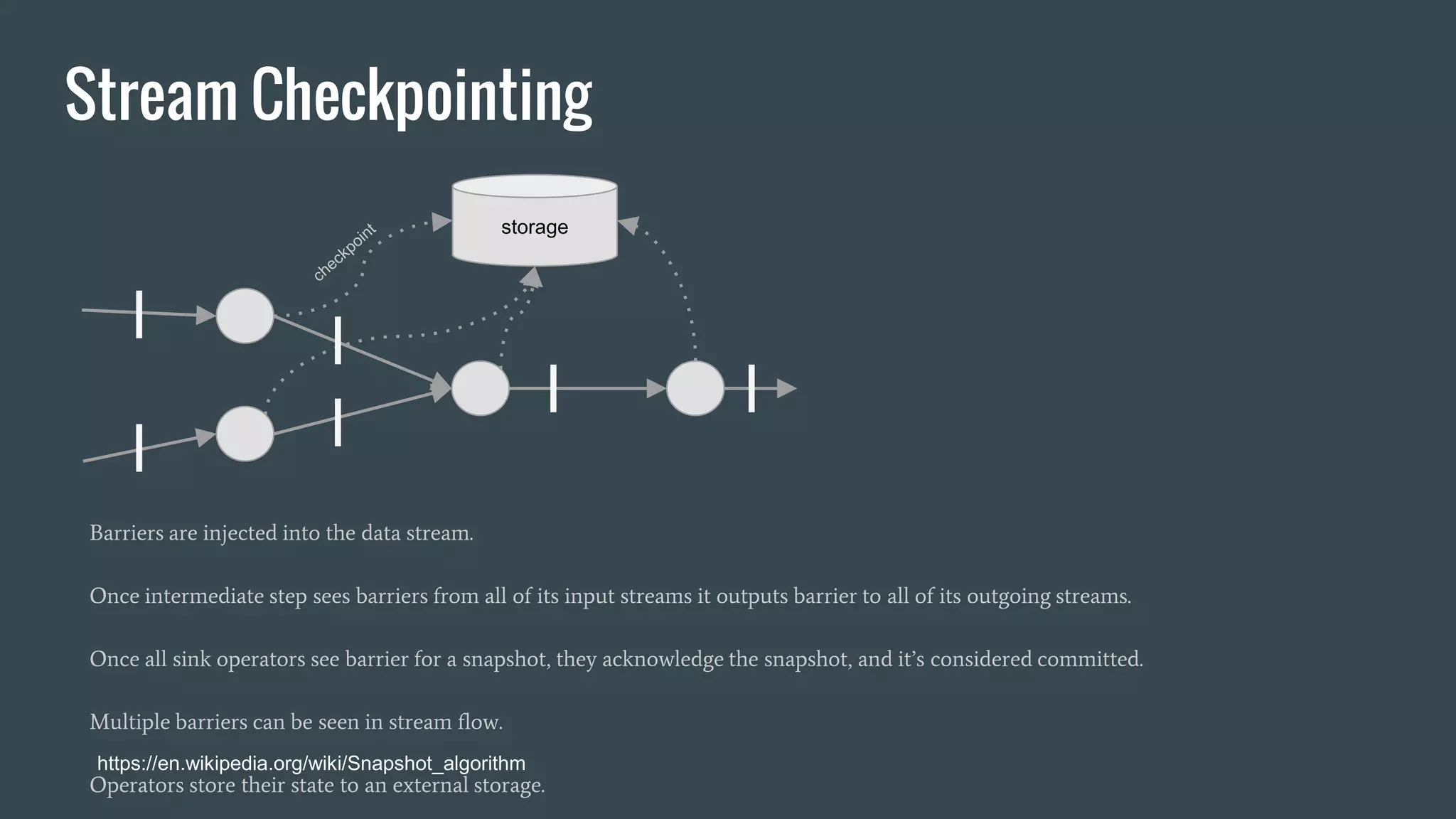
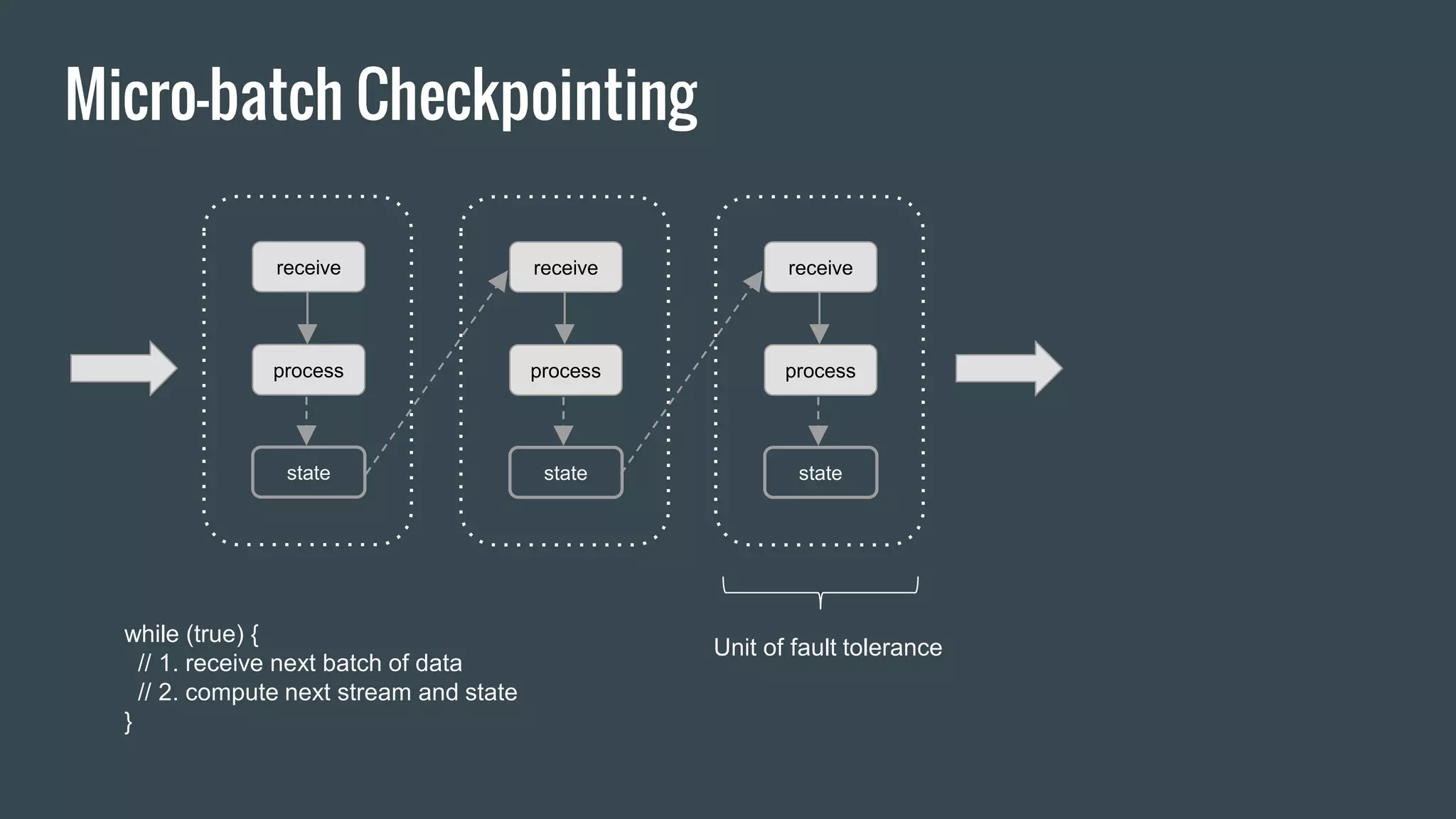
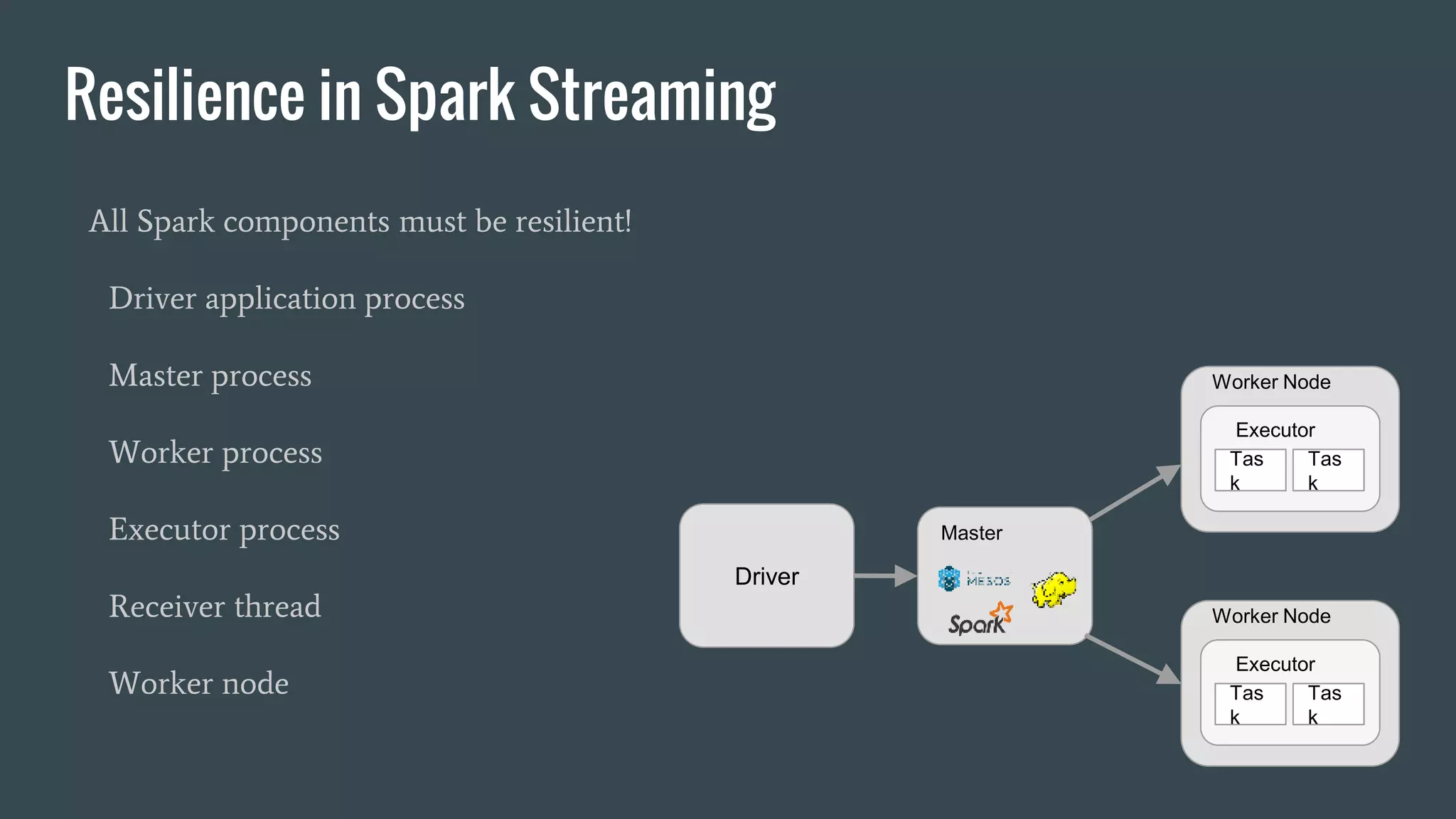
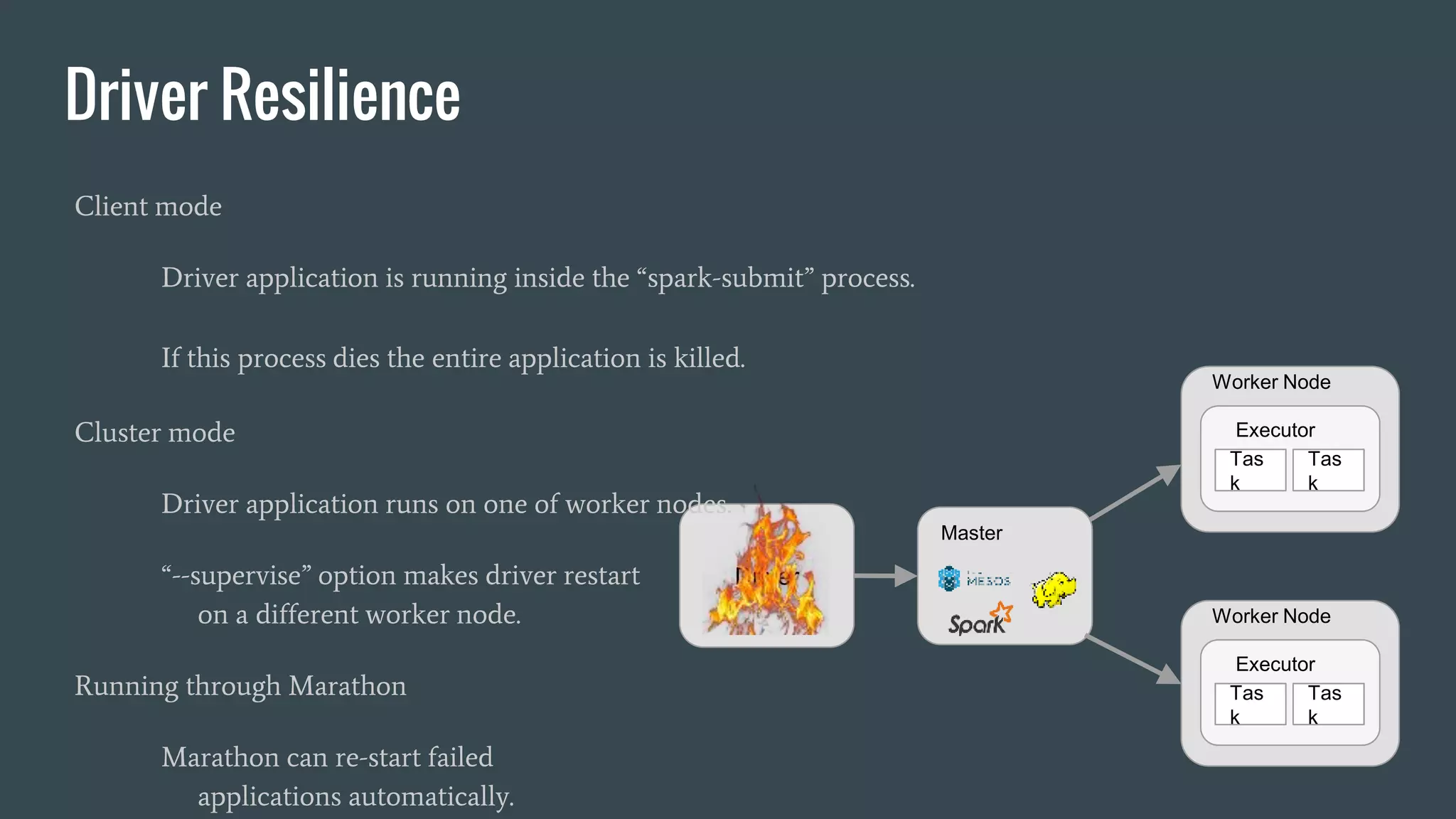

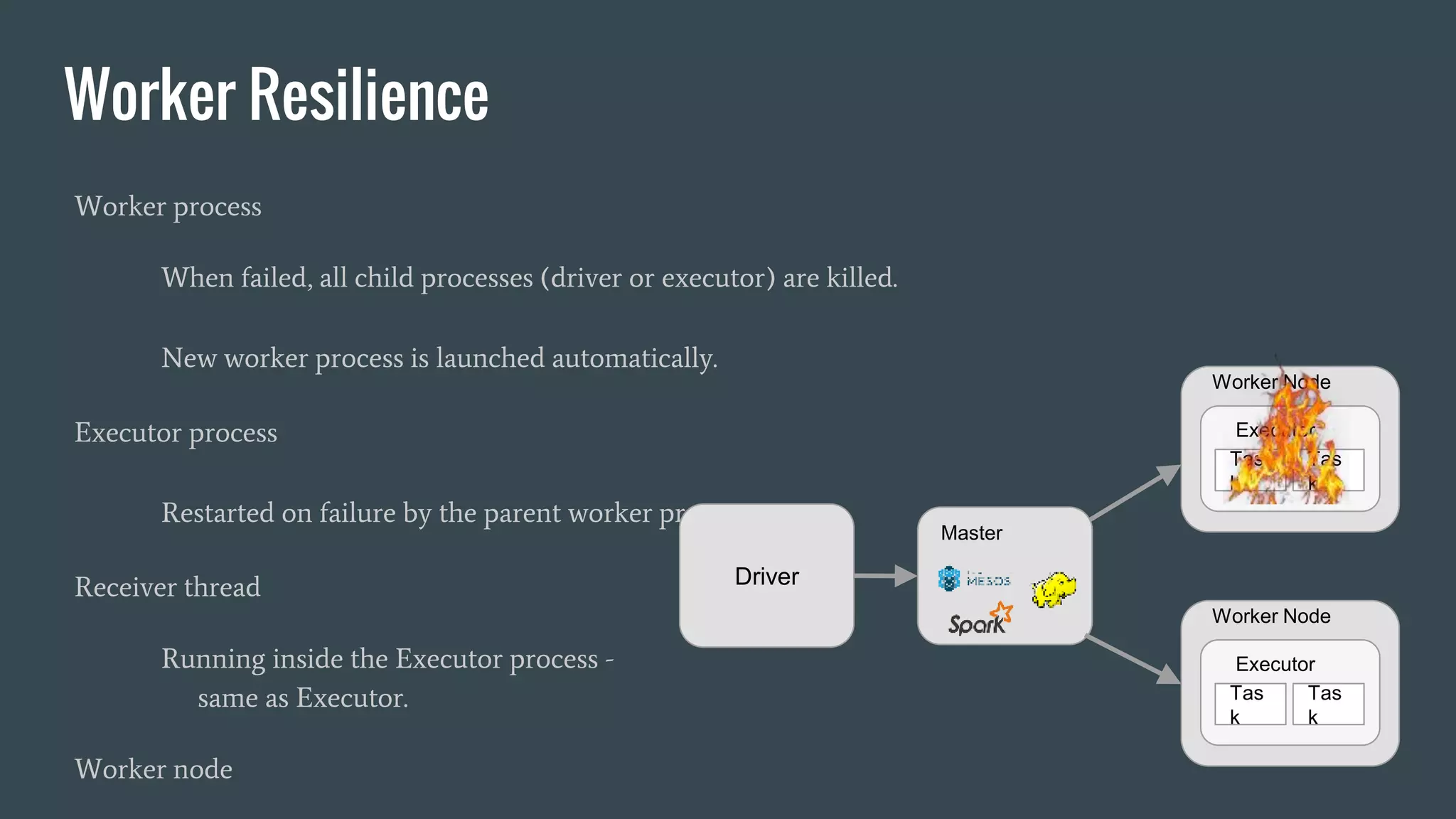


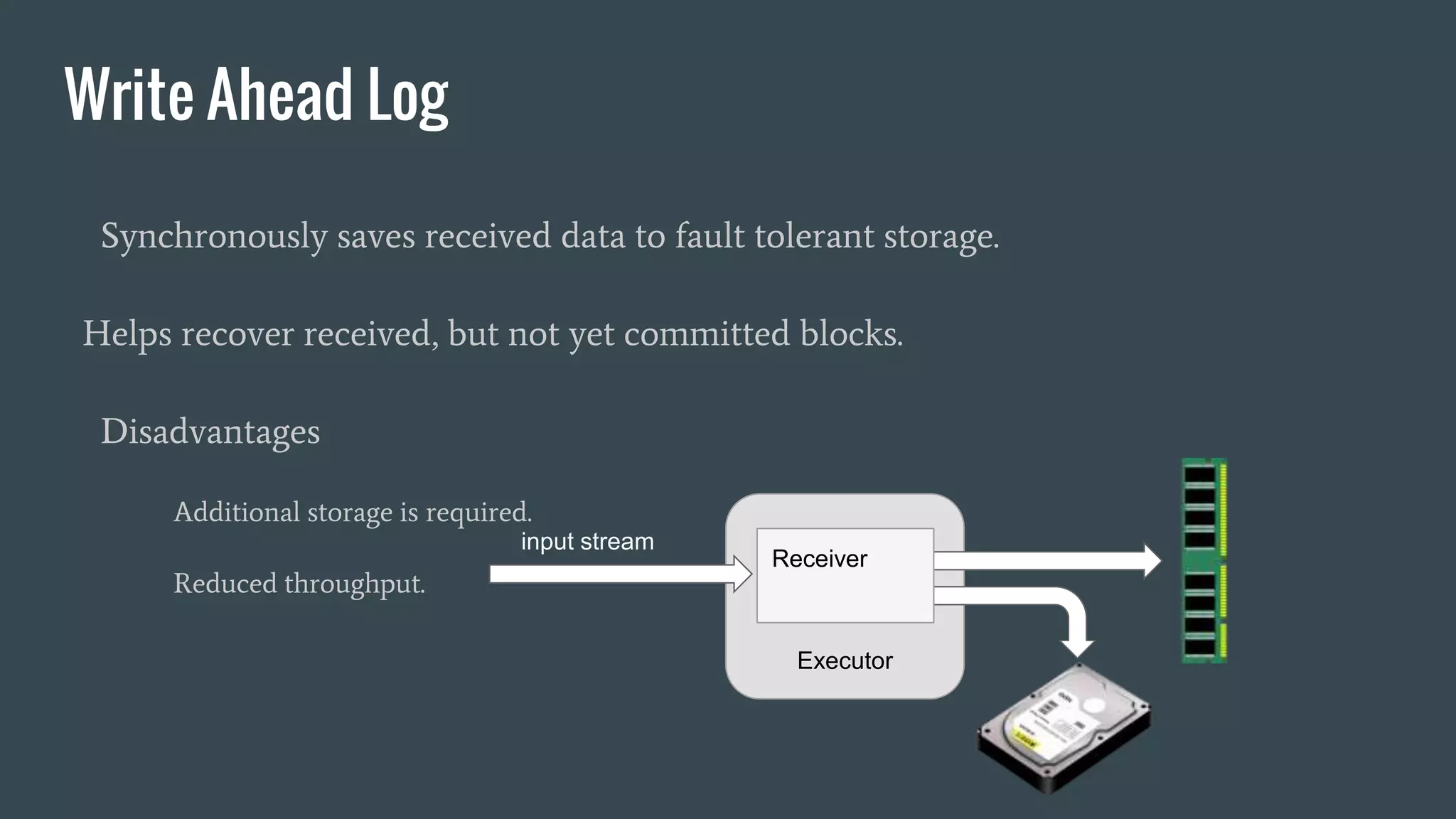

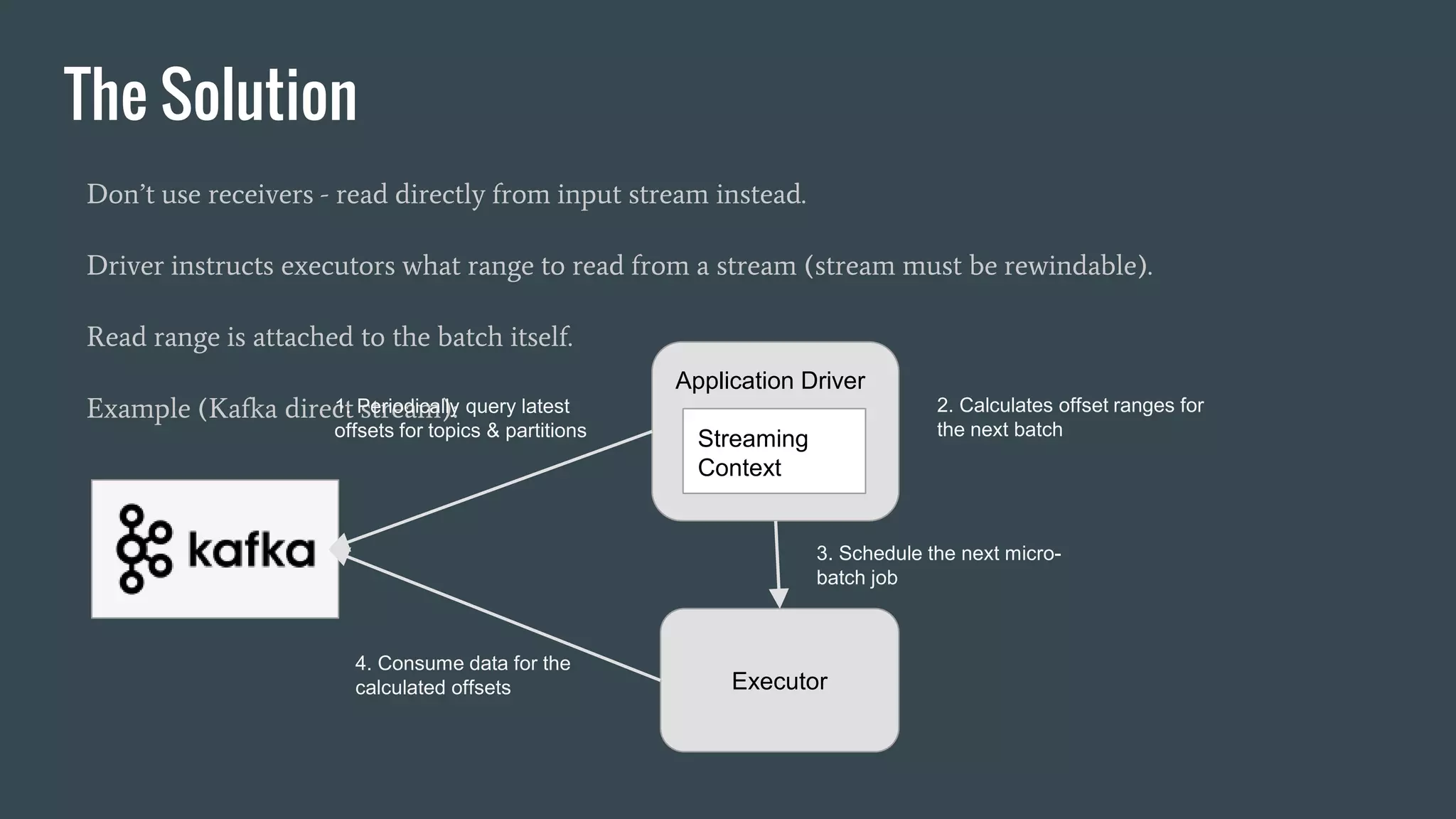

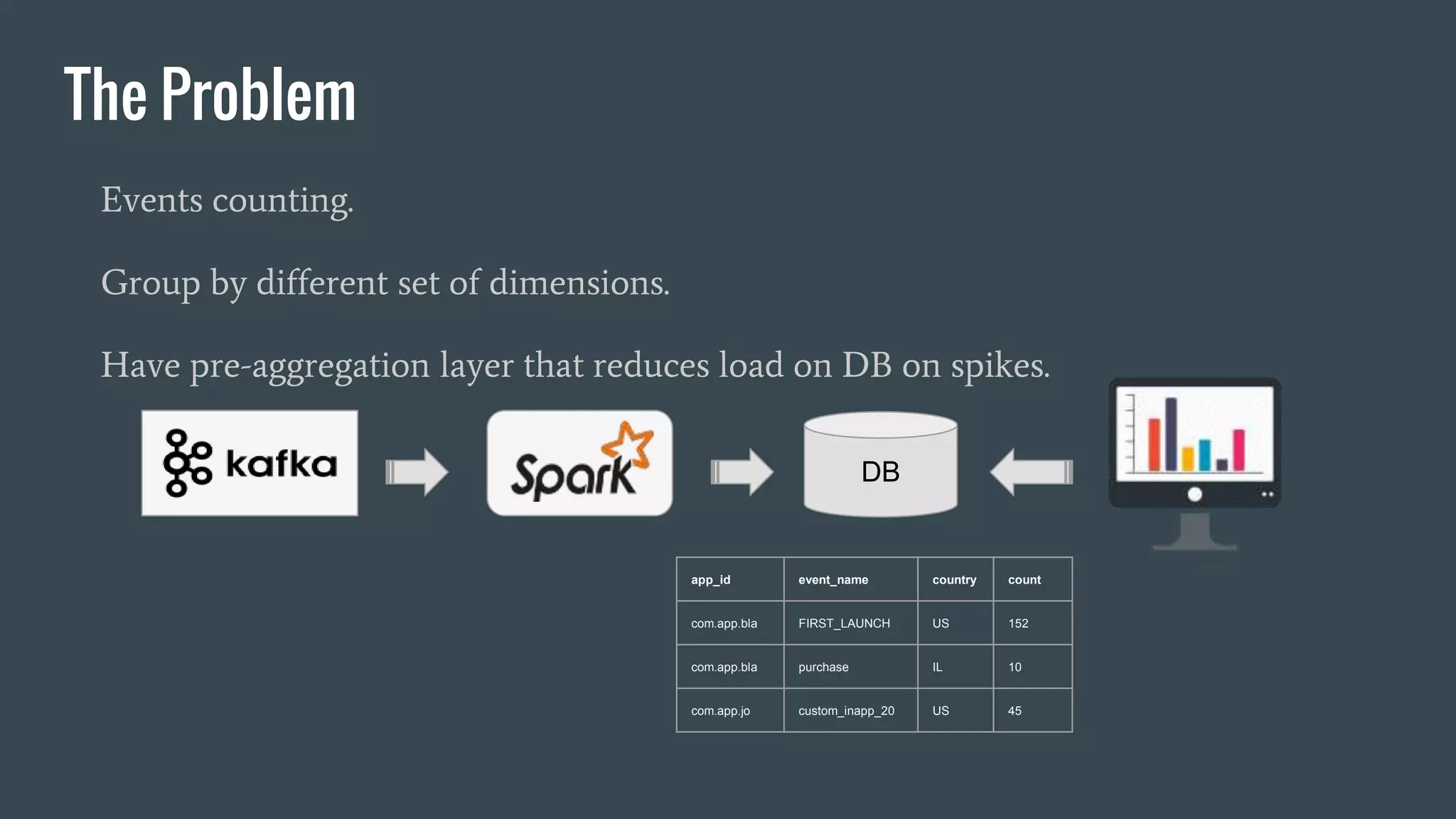
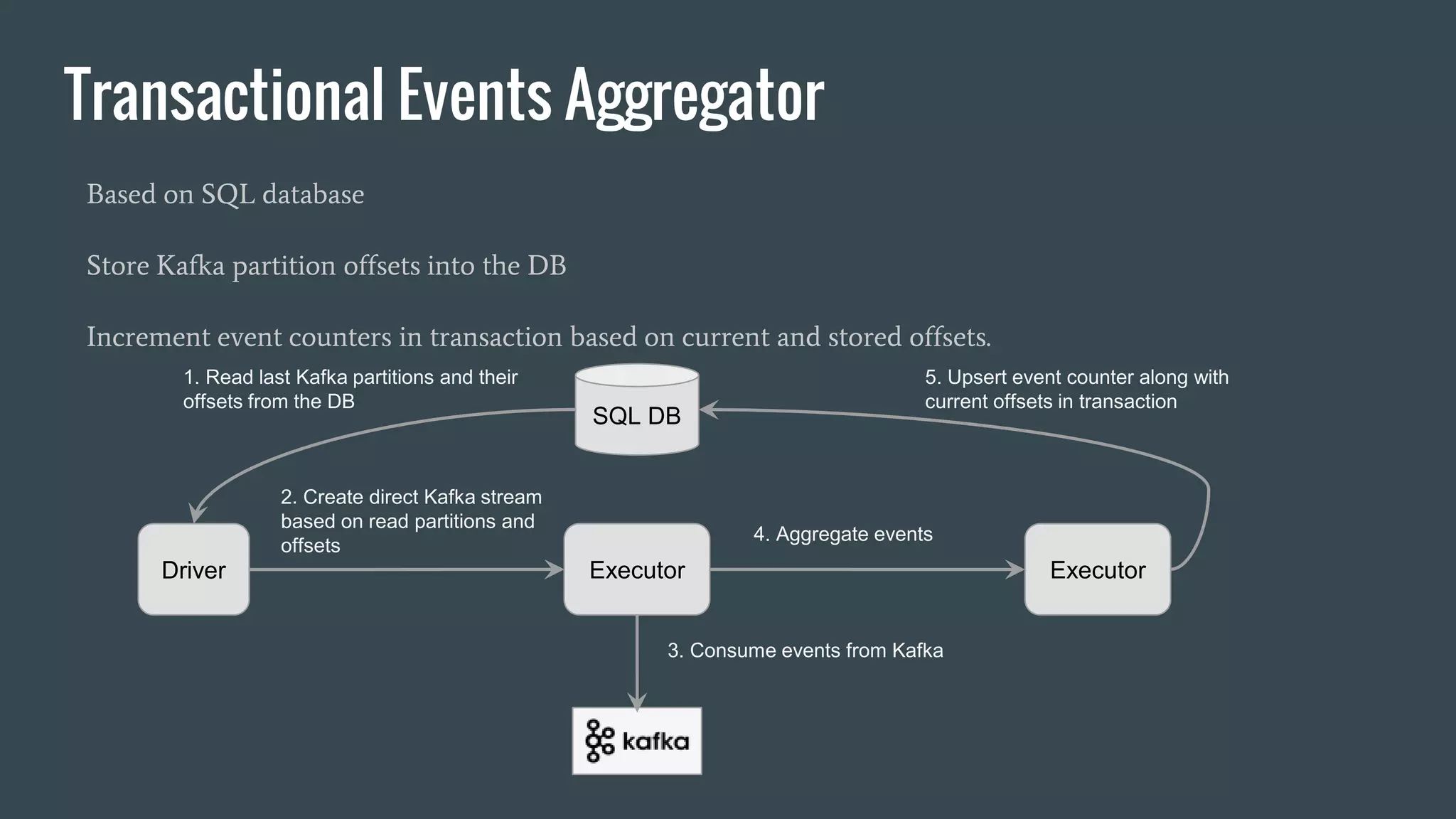
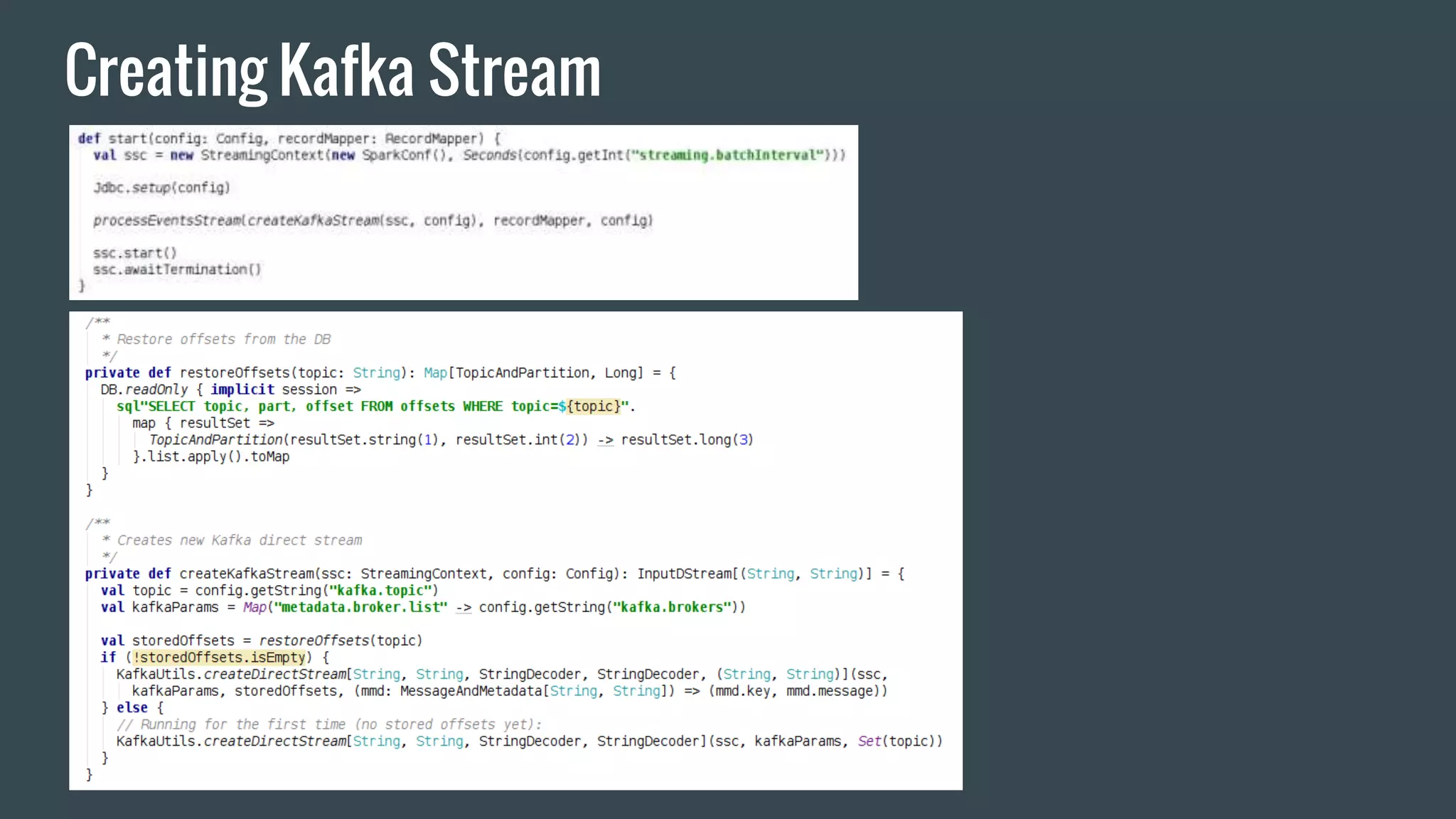
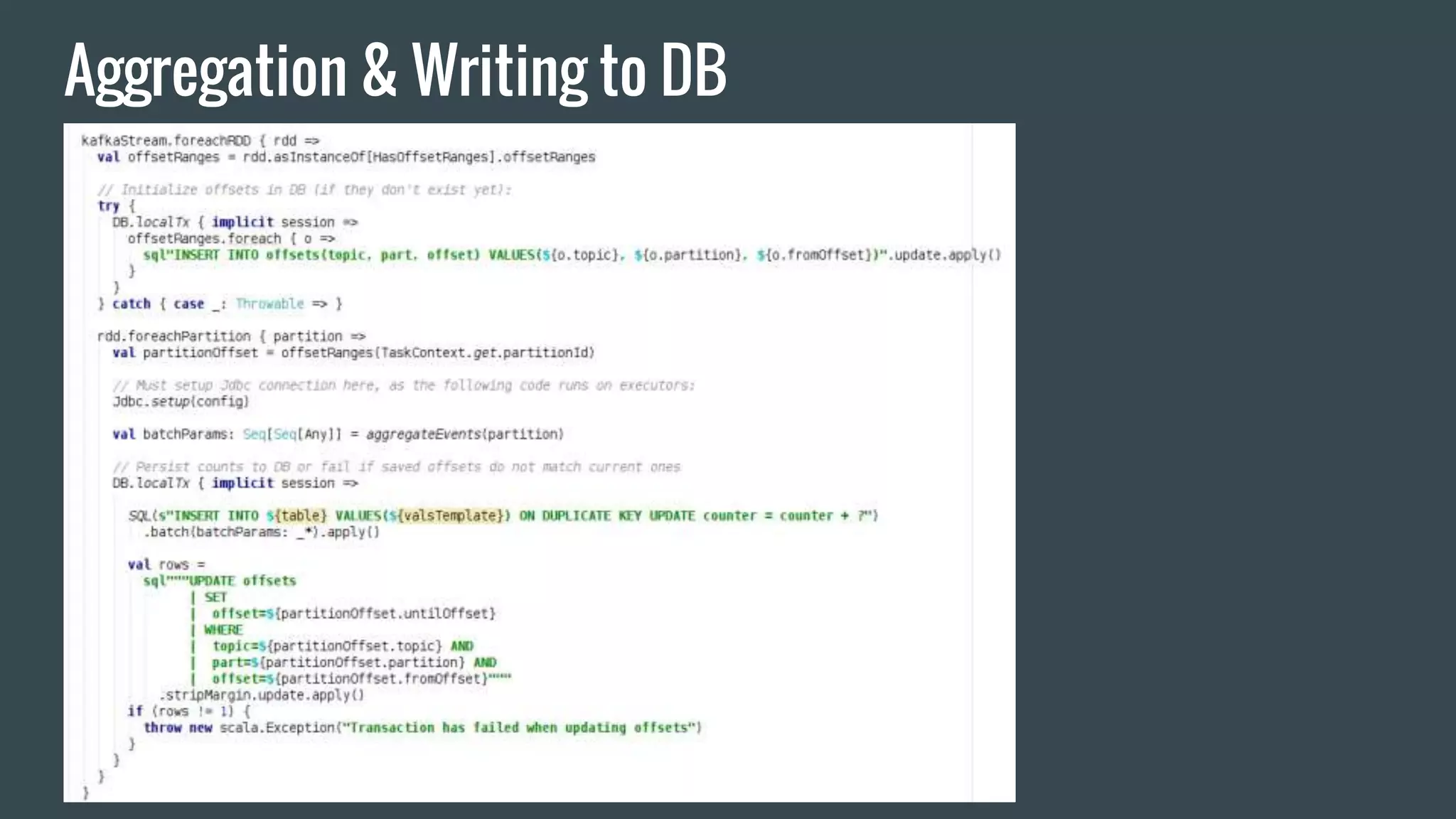

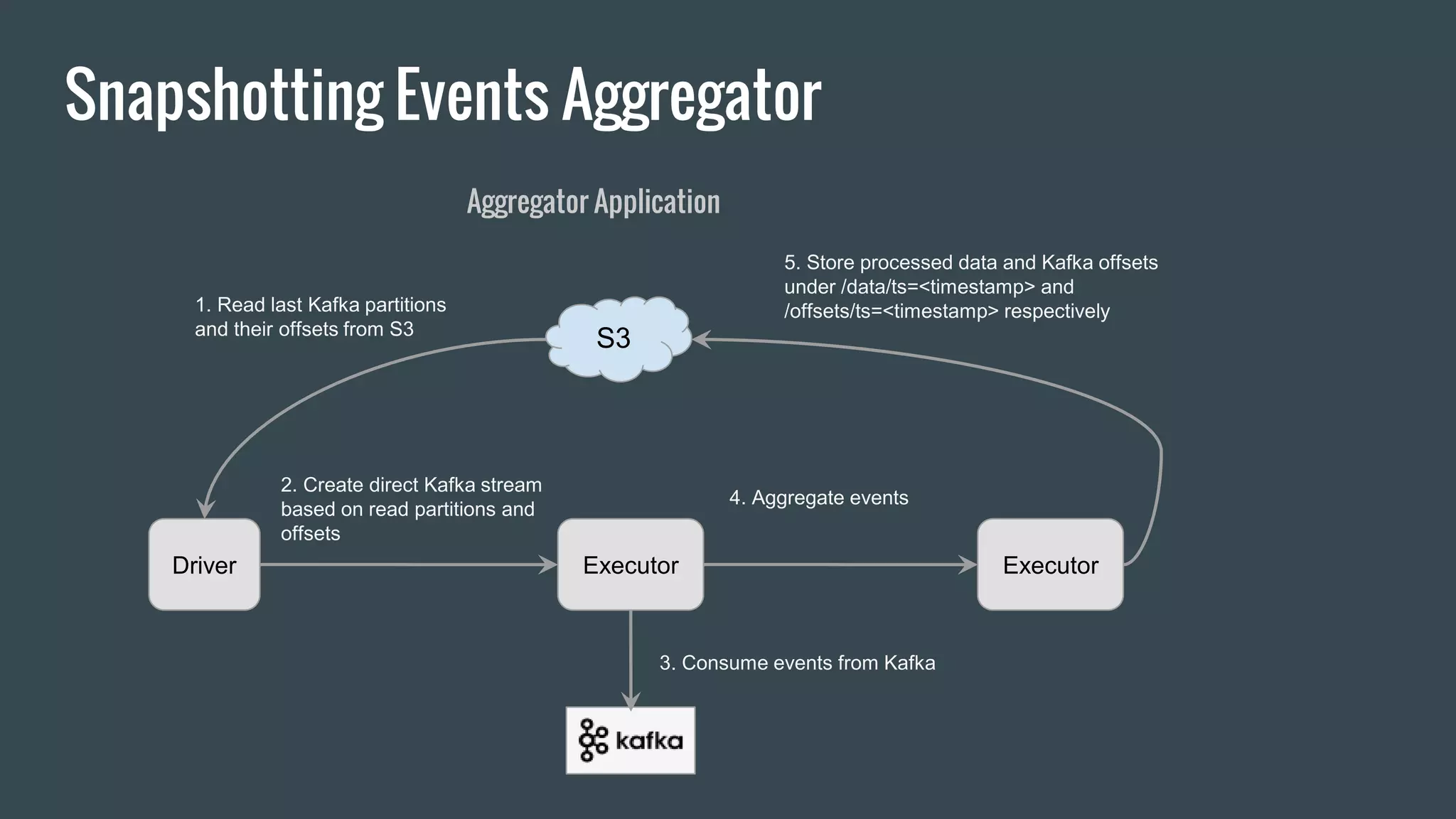
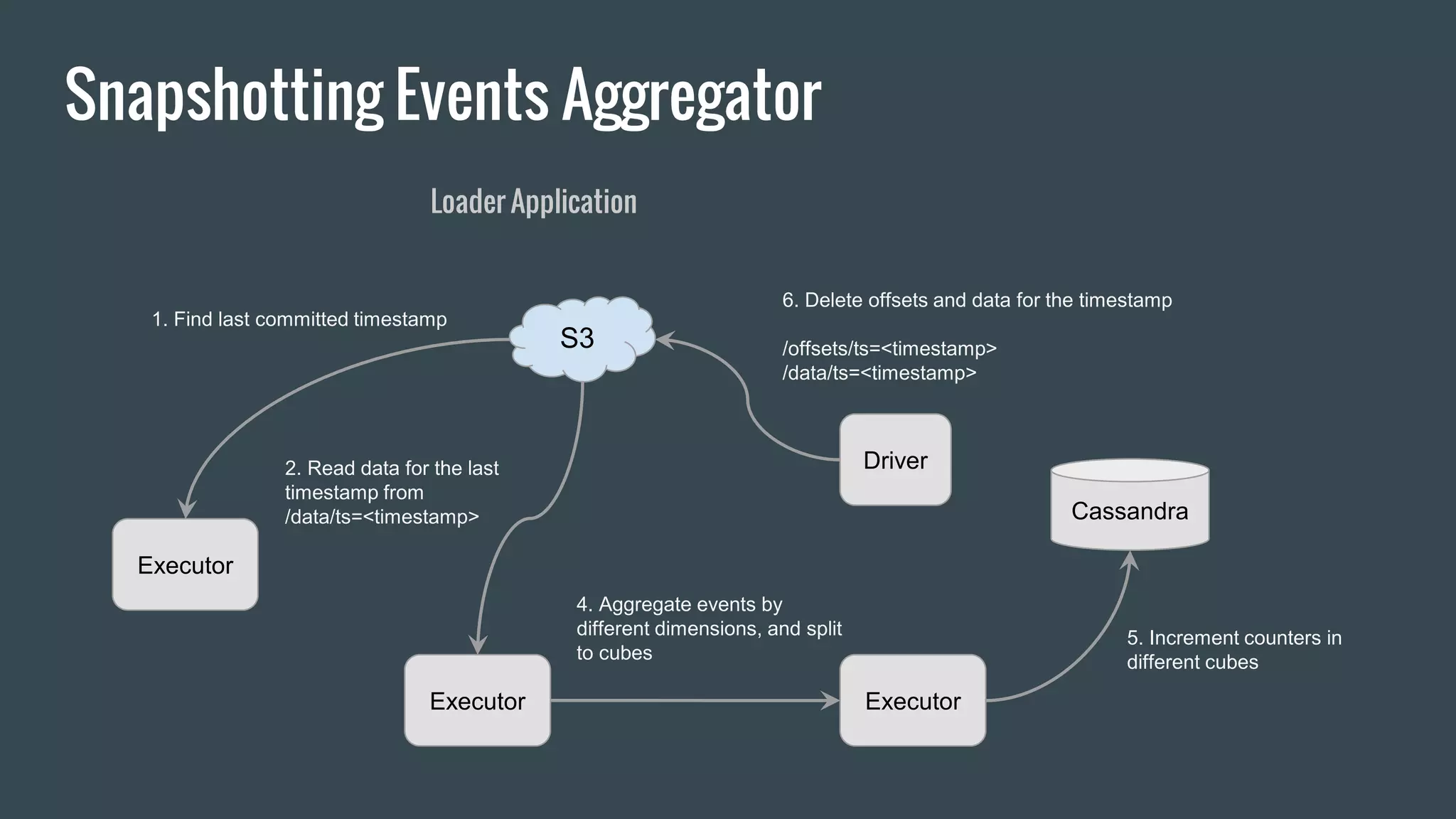
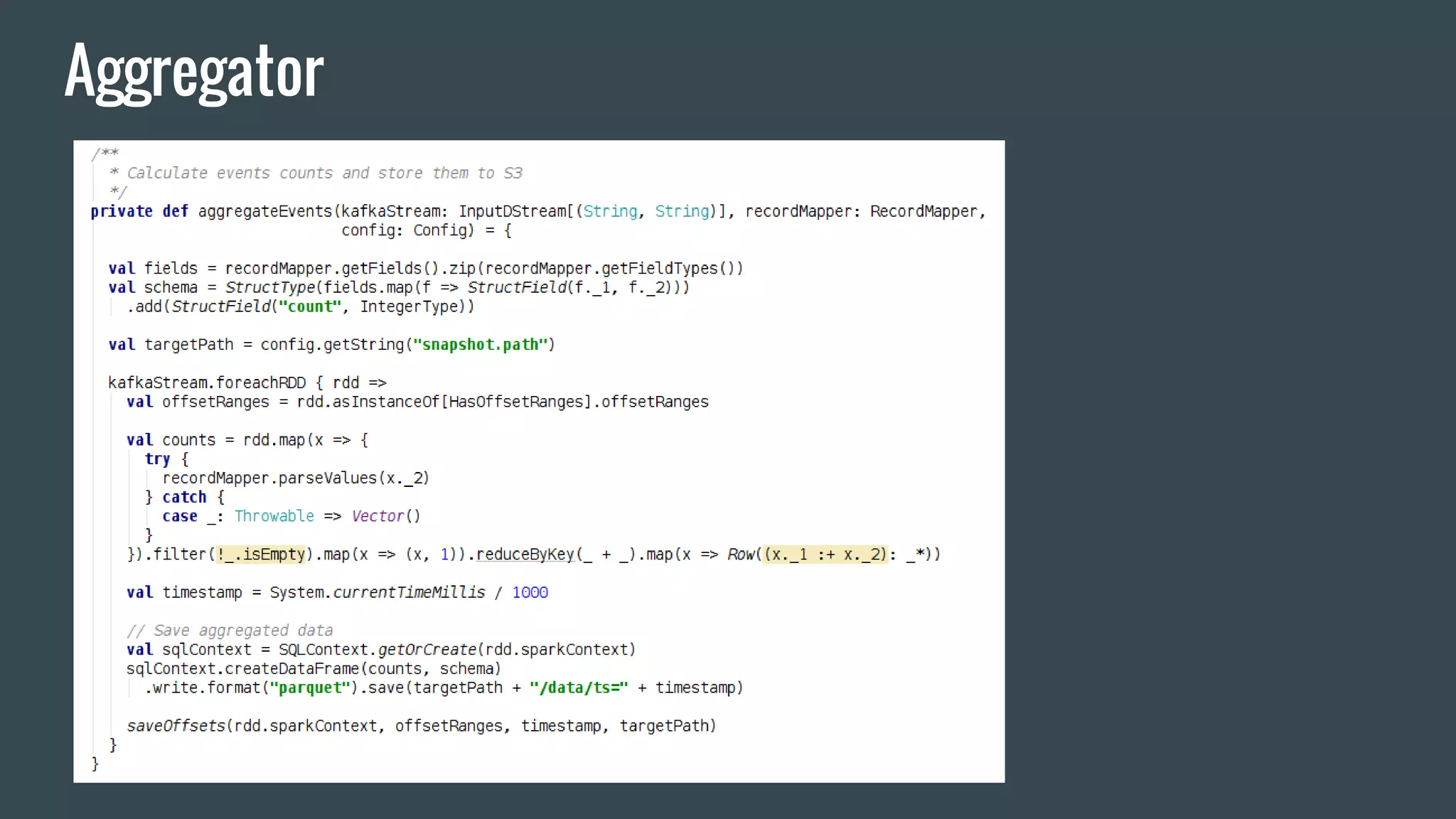
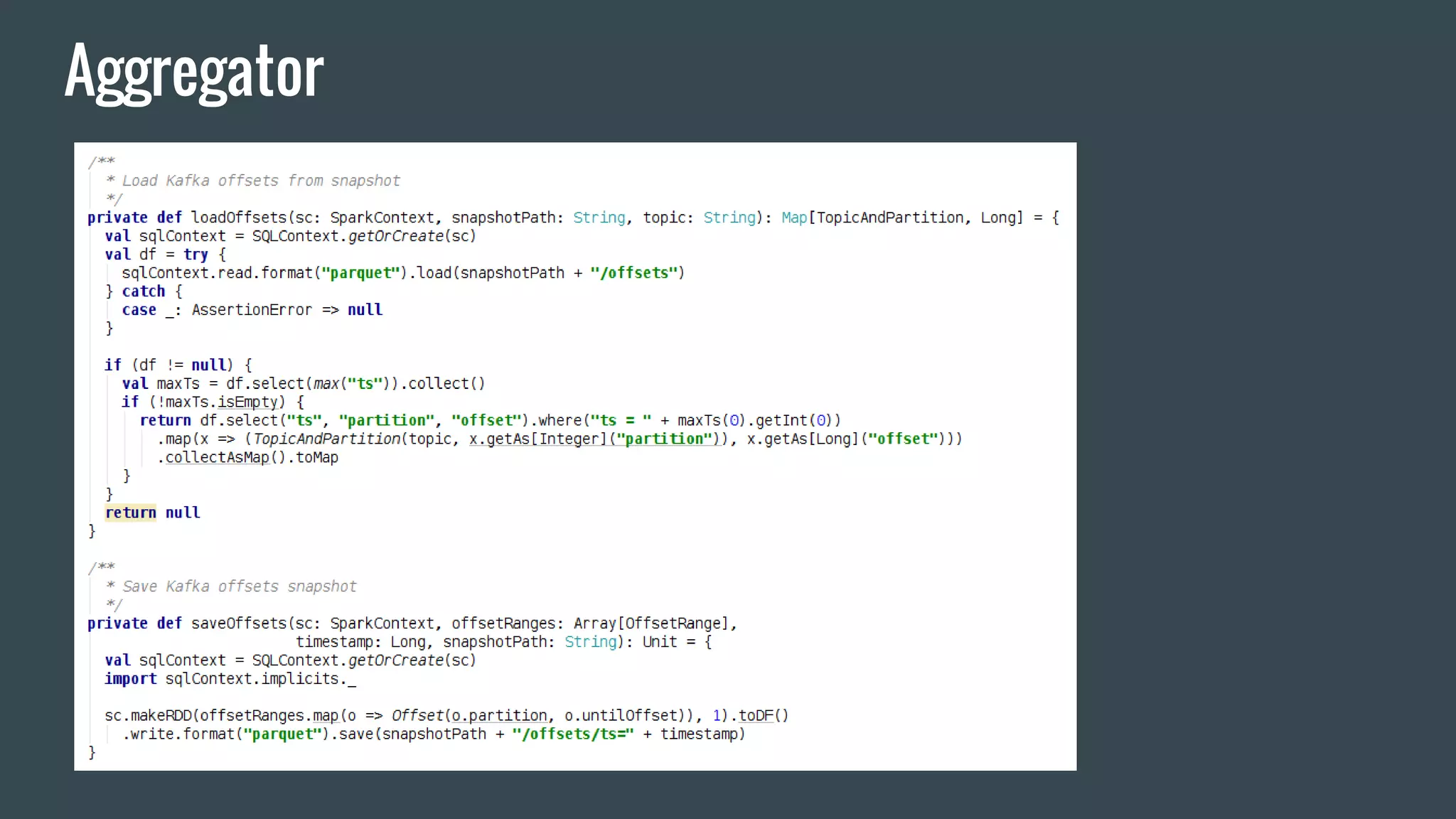
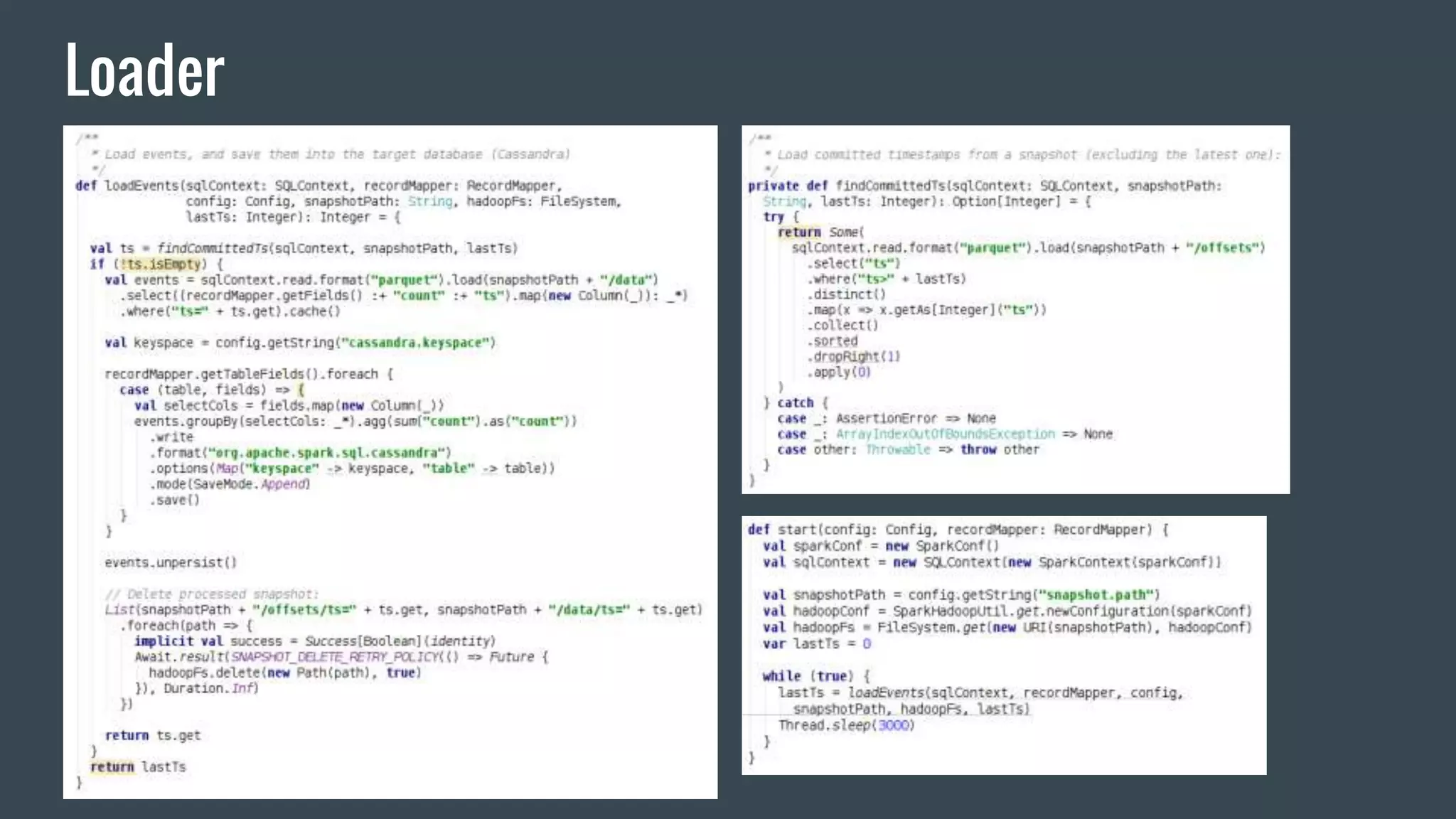


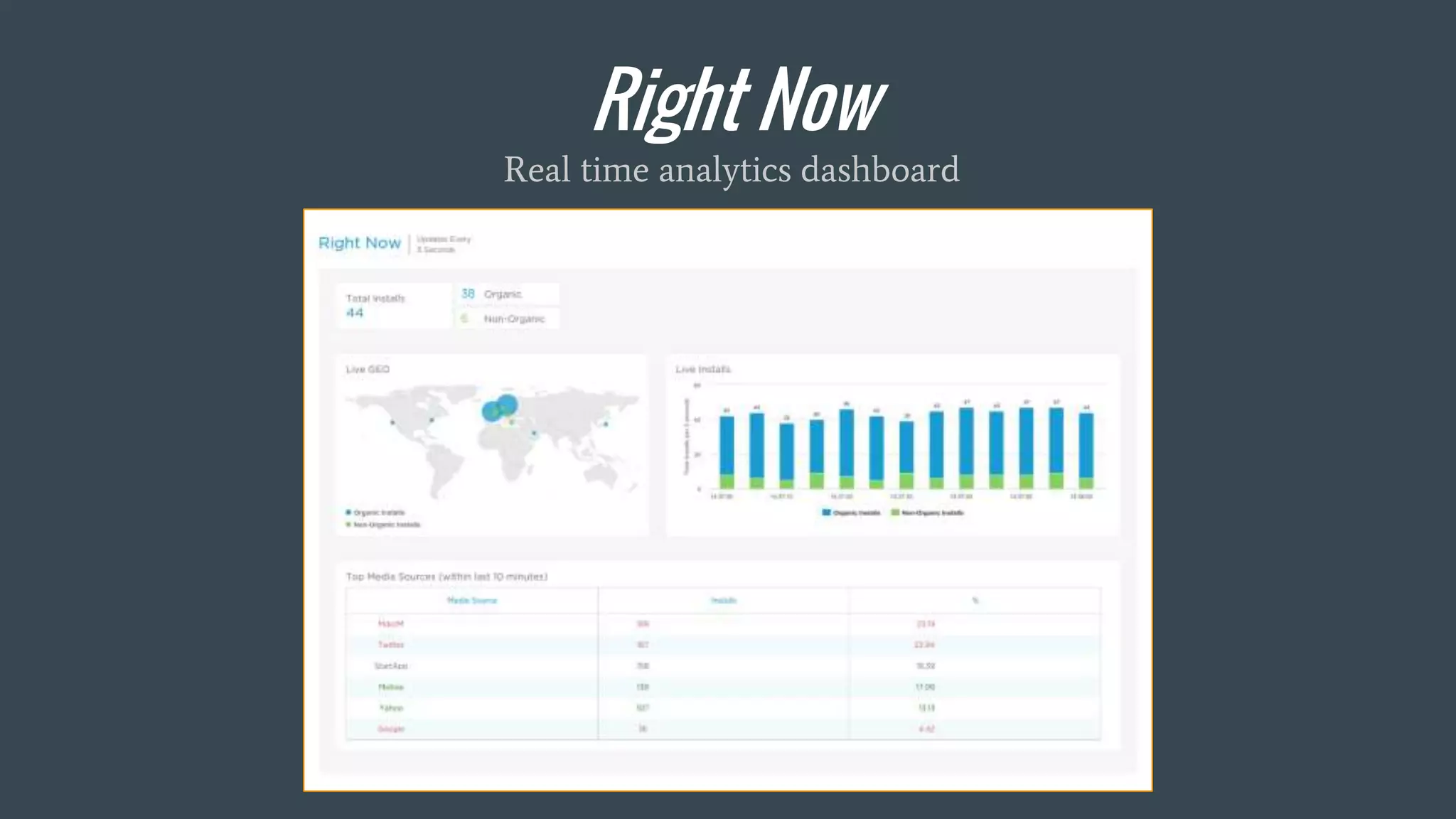

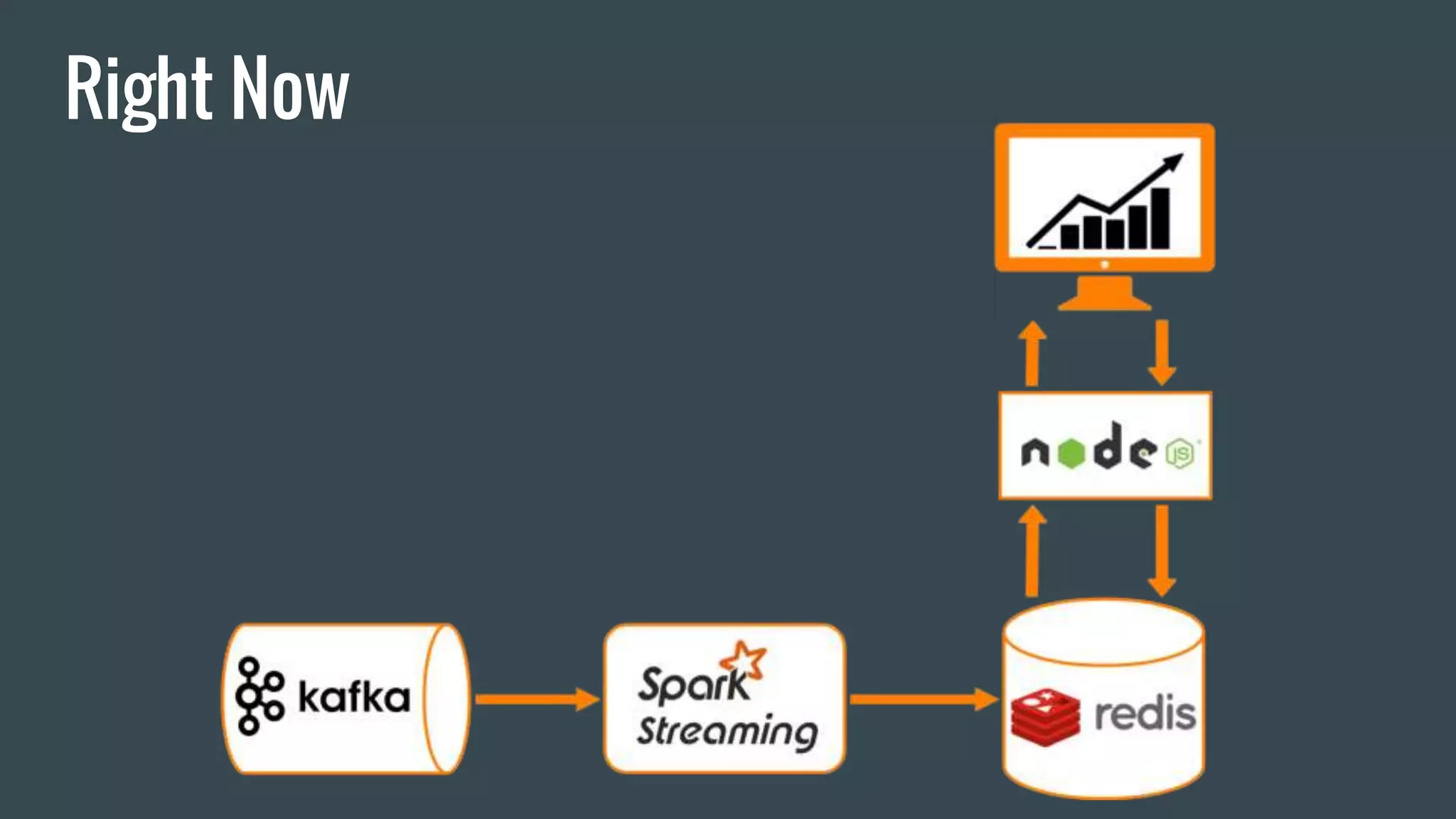




This document discusses stream processing with Apache Spark. It begins with an overview of Spark Streaming and its advantages over other frameworks like low latency and rich APIs. It then covers core Spark Streaming concepts like windowing and achieving "exactly once" semantics through checkpointing and write ahead logs. The document presents two examples of using Spark Streaming for analytics and aggregation with transactional and snapshotted approaches. It concludes with notes on deployment with Mesos/Marathon and performance tuning Spark Streaming jobs.






















































































