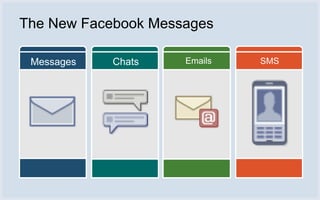
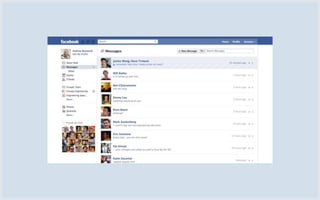
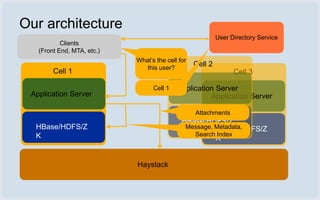
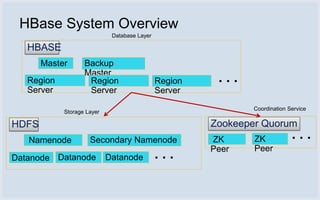
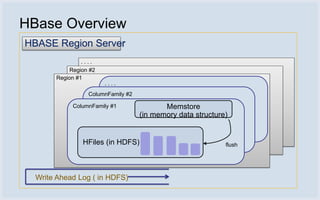
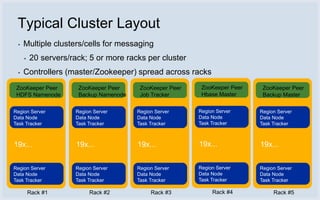
The document discusses Facebook's use of HBase as the database storage engine for its messaging platform. It provides an overview of HBase, including its data model, architecture, and benefits like scalability, fault tolerance, and simpler consistency model compared to relational databases. The document also describes Facebook's contributions to HBase to improve performance, availability, and achieve its goal of zero data loss. It shares Facebook's operational experiences running large HBase clusters and discusses its migration of messaging data from MySQL to a de-normalized schema in HBase.







































































![[Hi c2011]building mission critical messaging system(guoqiang jerry)](https://cdn.slidesharecdn.com/ss_thumbnails/hic2011buildingmissioncriticalmessagingsystemguoqiangjerry-111206111202-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

















