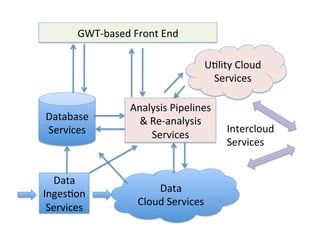
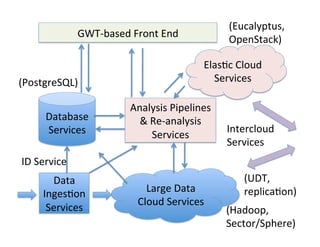
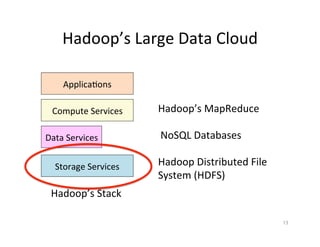
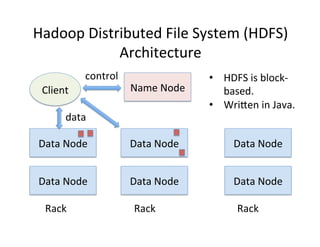
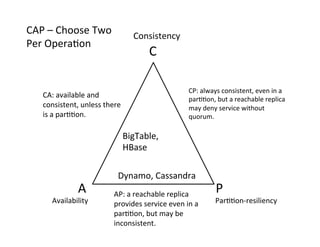
Chapter 2 of the document focuses on data management in data-intensive computing, covering data clouds, big data management, and different types of databases such as NoSQL and distributed file systems. It discusses the importance of scale-out solutions, the architecture of distributed systems (like Hadoop and Sector), and the trade-offs in data consistency and availability as outlined by the CAP theorem. Additionally, various case studies demonstrate real-world applications of these concepts in handling large datasets and enhancing data analysis efficiency.





































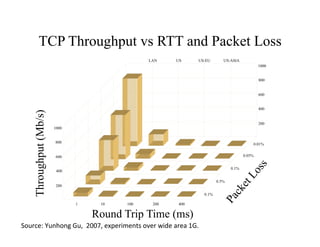

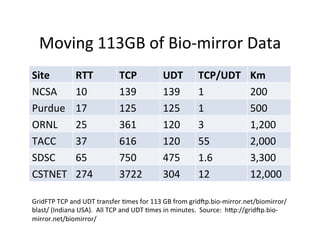
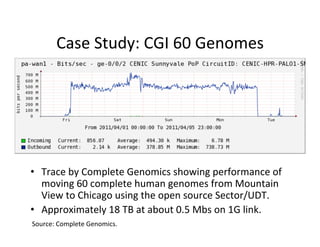
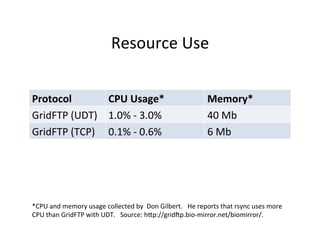
![Case
Study:
Bio-‐mirror
[The
open
source
GridFTP]
from
the
Globus
project
has
recently
been
improved
to
offer
UDP-‐based
file
transport,
with
long-‐distance
speed
improvements
of
3x
to
10x
over
the
usual
TCP-‐based
file
transport.
-‐-‐
Don
Gilbert,
August
2010,
bio-‐mirror.net](https://image.slidesharecdn.com/02-managing-big-data-11-v5-170904212737/85/Managing-Big-Data-An-Introduction-to-Data-Intensive-Computing-52-320.jpg)