Downloaded 427 times









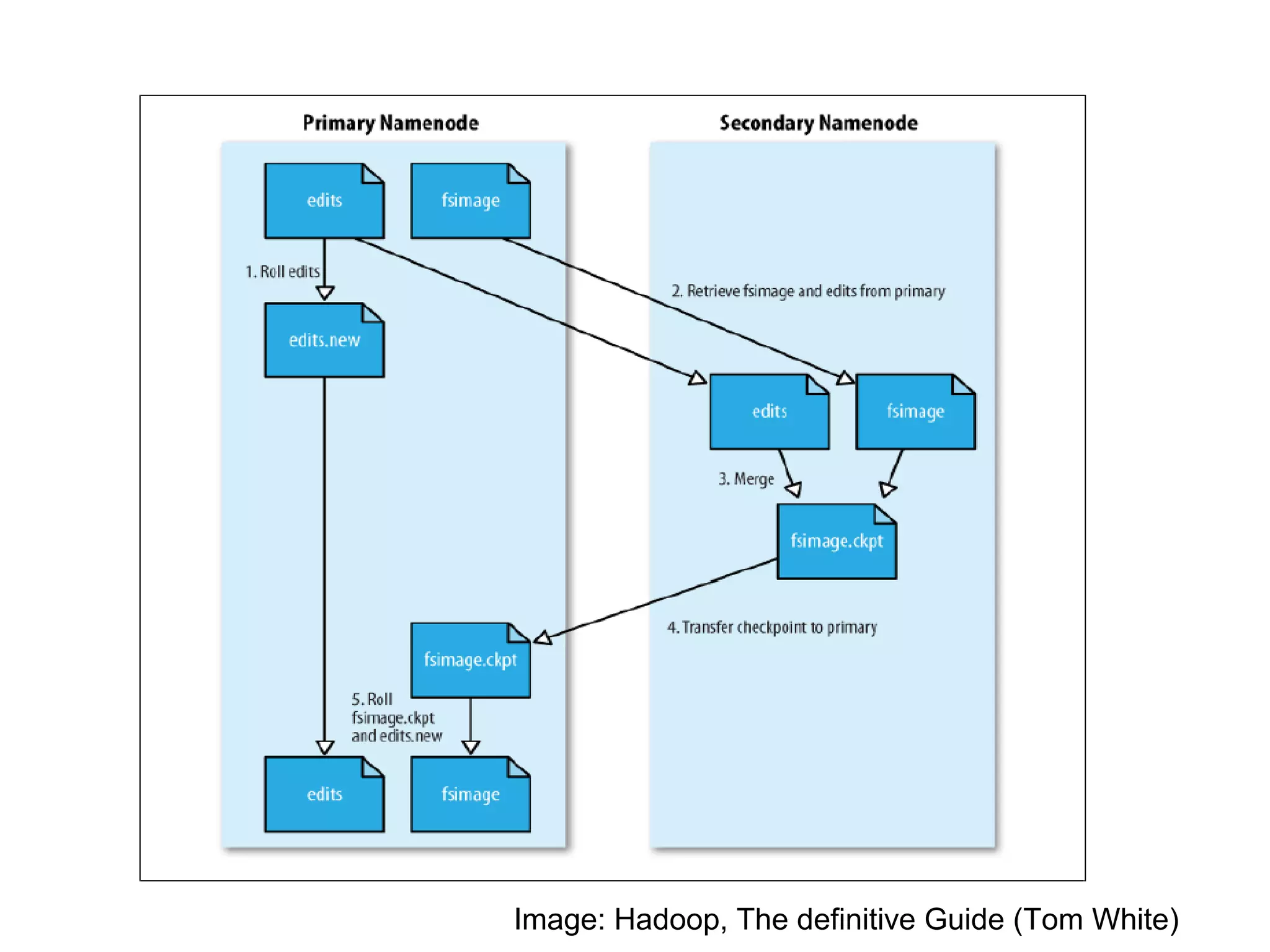

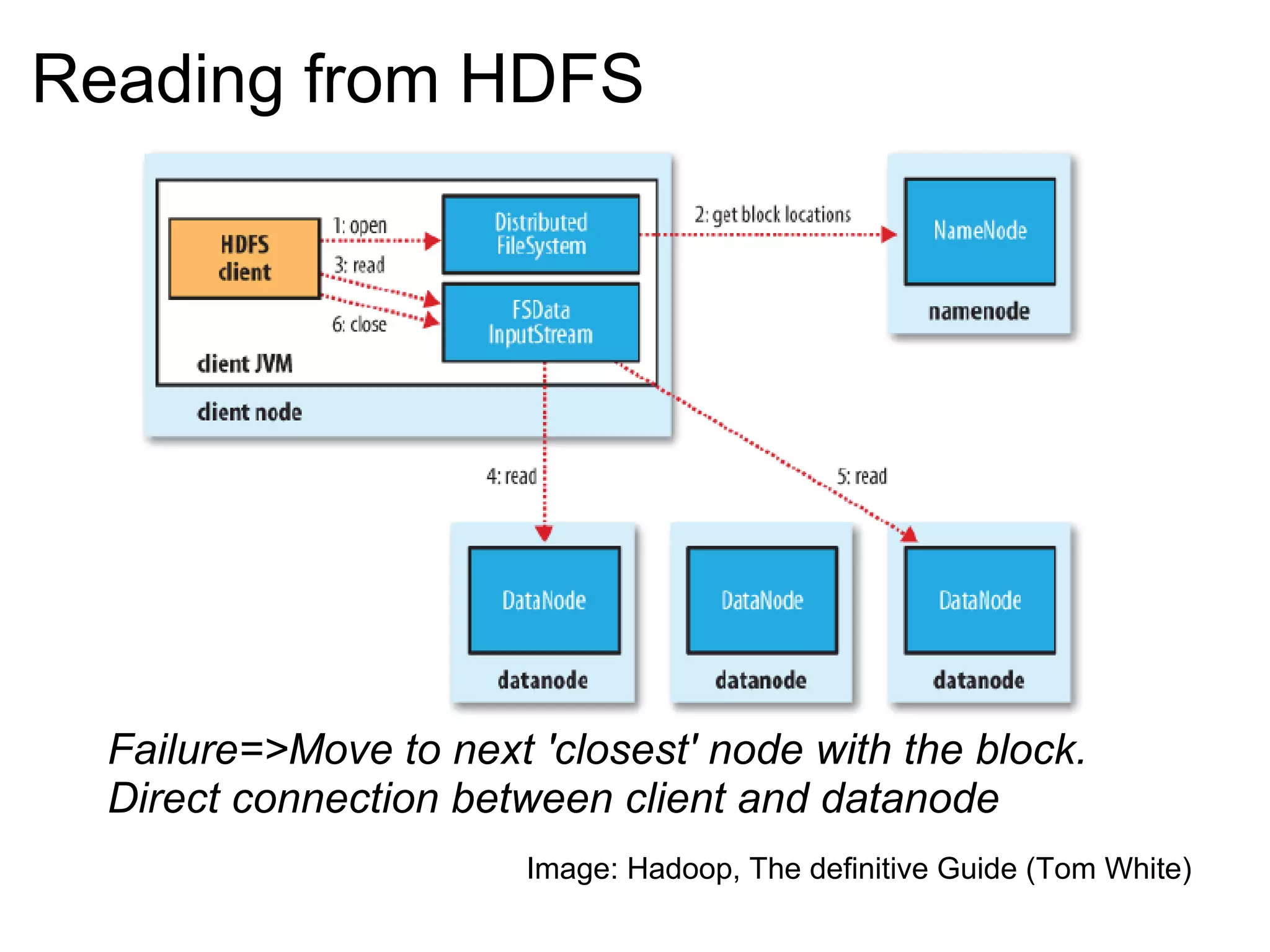
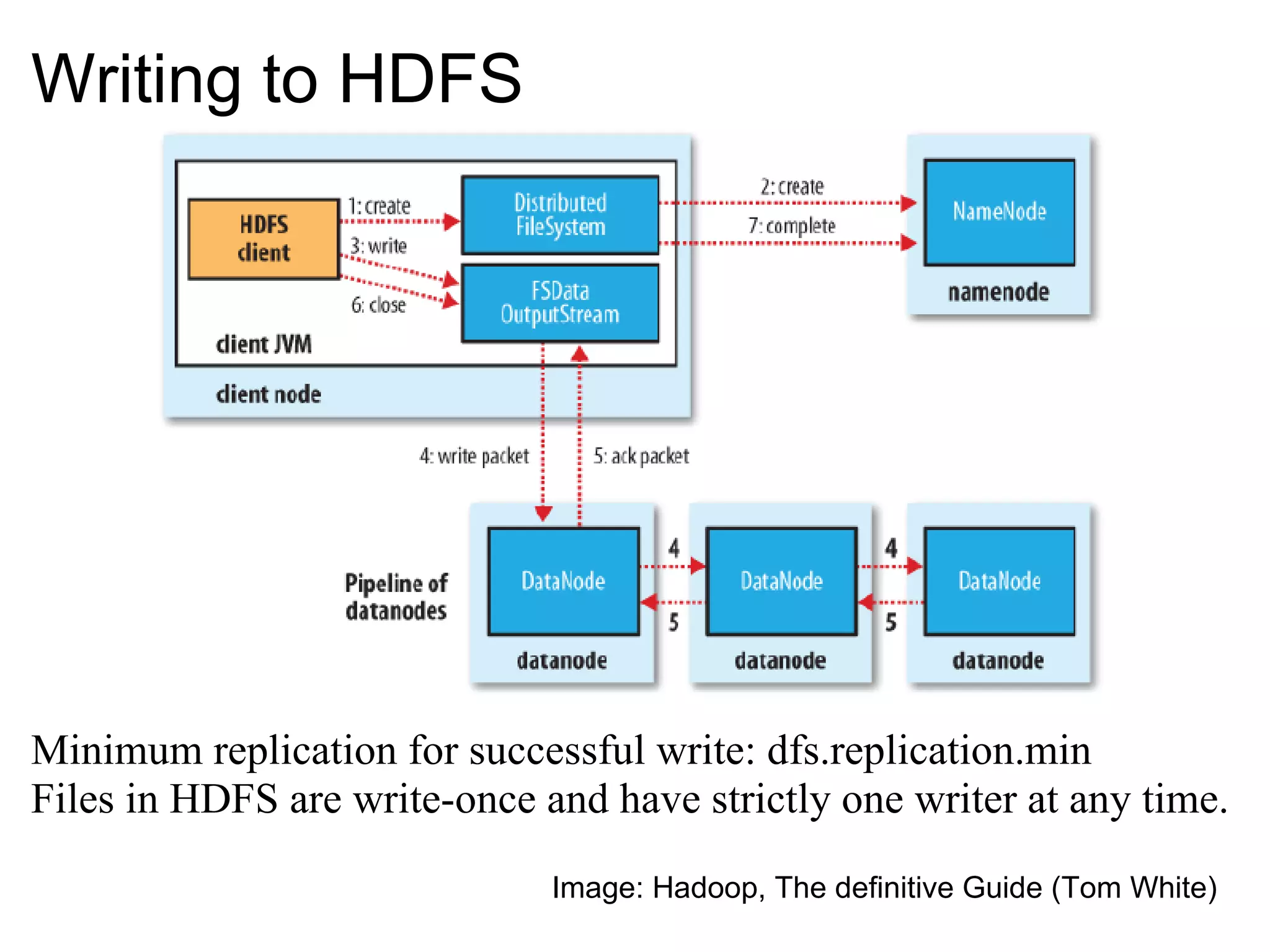


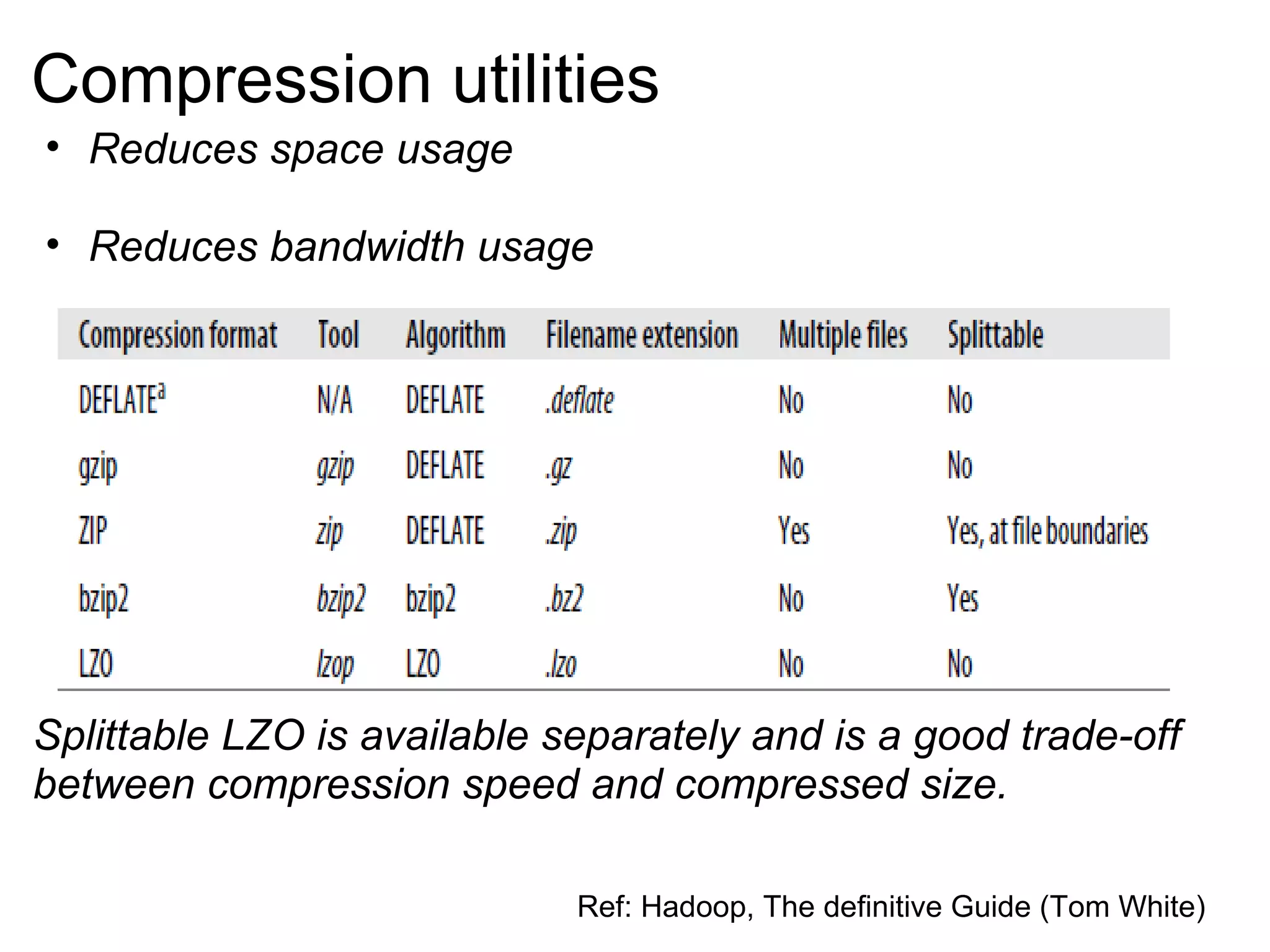


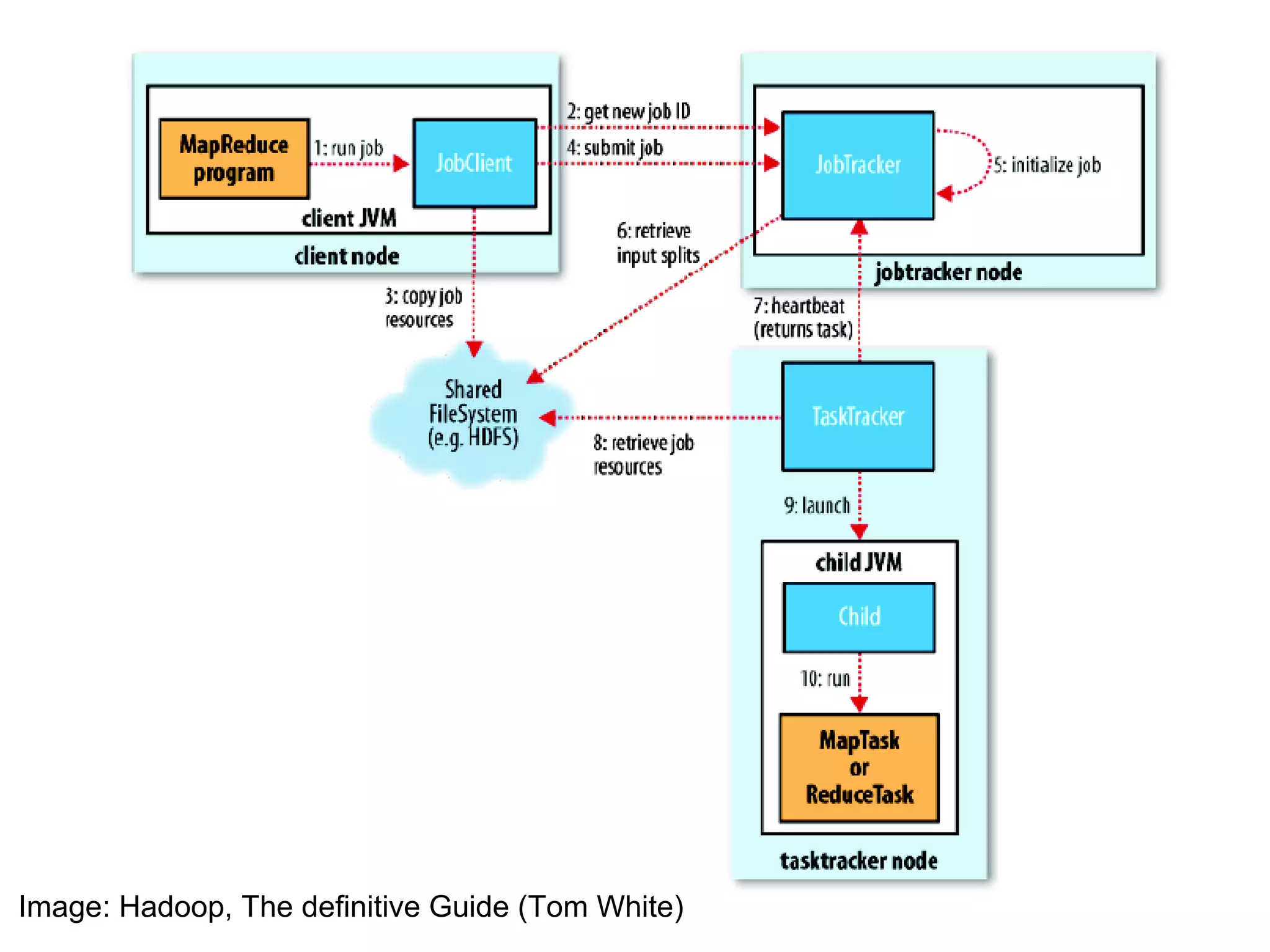


The document provides an overview of the Hadoop architecture including its core components like HDFS for distributed storage, MapReduce for distributed processing, and an explanation of how data is stored in blocks and replicated across nodes in the cluster. Key aspects of HDFS such as the namenode, datanodes, and secondary namenode functions are described as well as how Hadoop implementations like Pig and Hive provide interfaces for data processing.



































































