Download to read offline








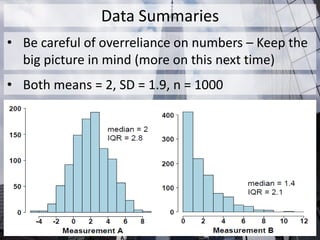



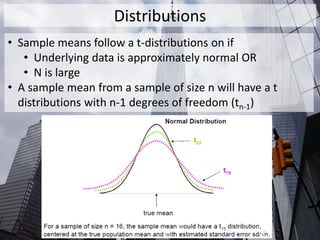





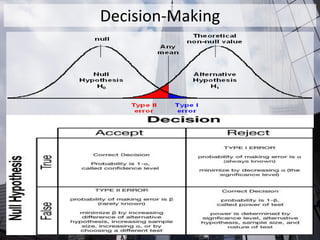












The document outlines the fundamentals of statistical analysis, emphasizing the importance of understanding different data types and methods to facilitate communication between researchers and biostatisticians. It covers key concepts such as data types (numerical and categorical), statistical inference, hypothesis testing, and the selection of appropriate tests based on the nature of the data. Additionally, it highlights the distinction between parametric and nonparametric methods, stressing the need for careful test selection to avoid incorrect conclusions.






















































































