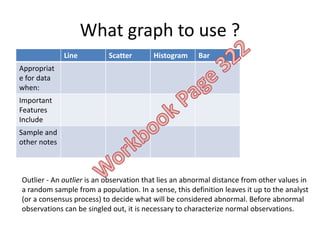
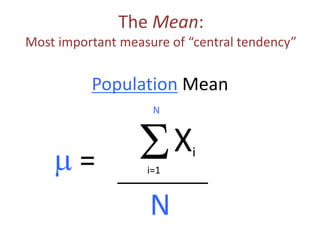
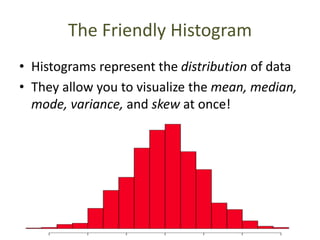
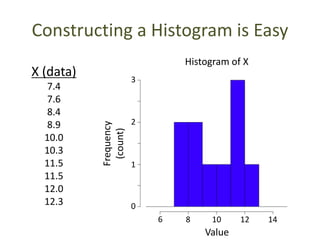
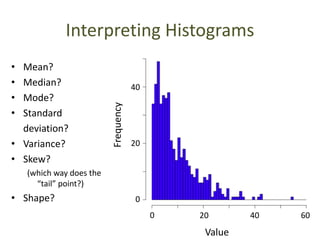
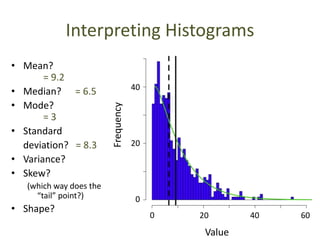
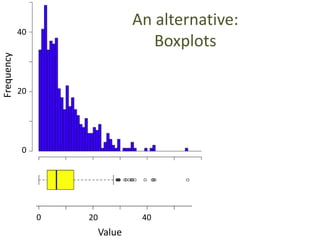
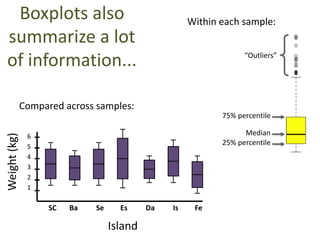
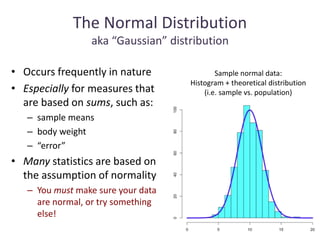
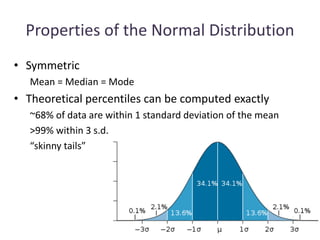
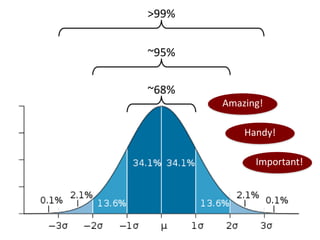
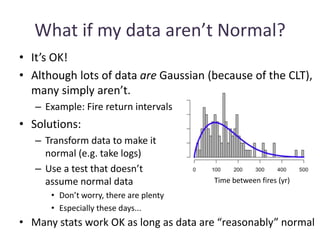
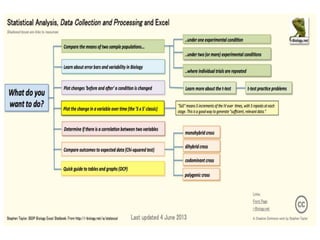
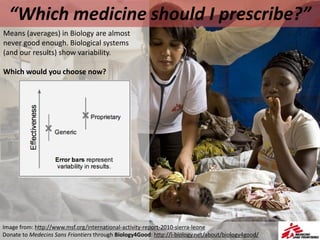
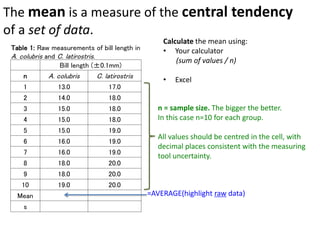
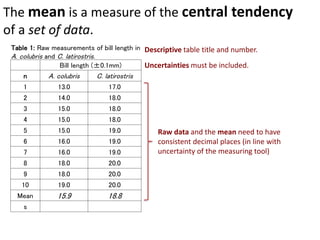
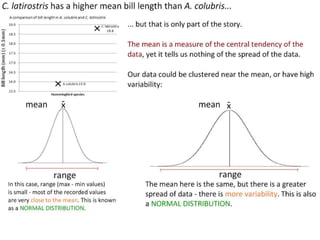
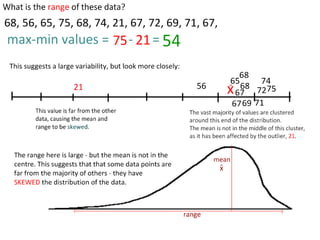
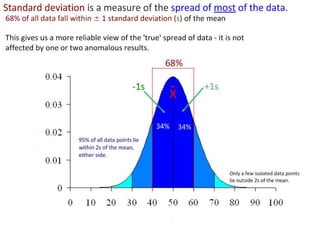
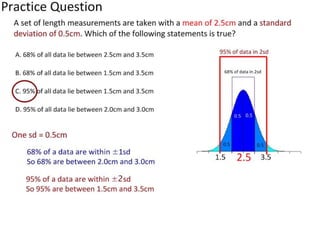
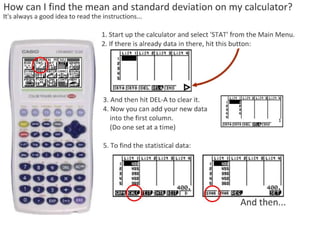
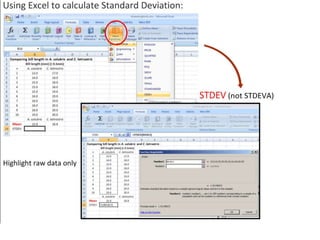
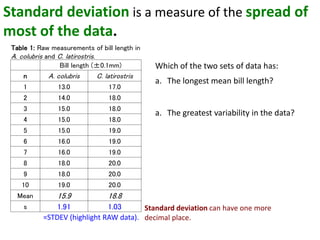
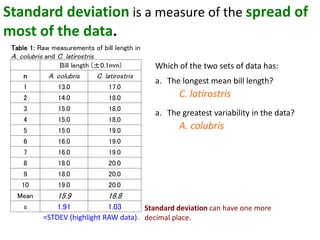
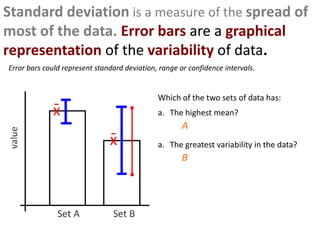
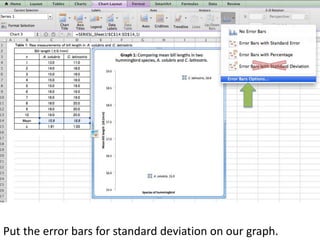
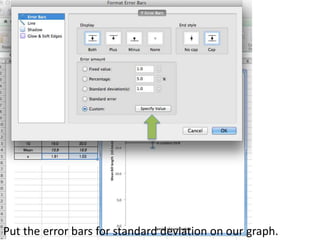
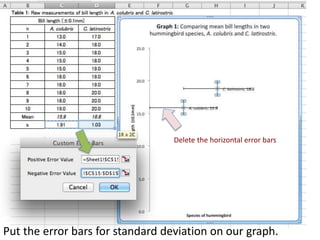
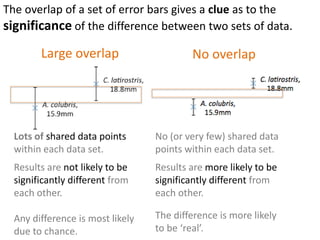
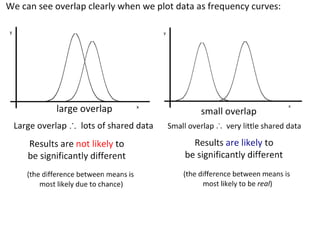
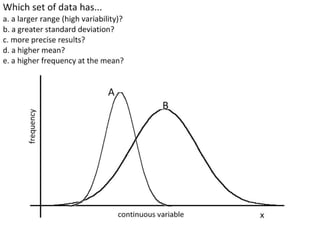
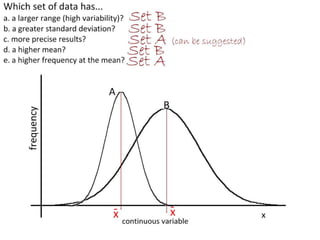
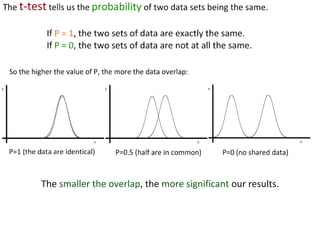
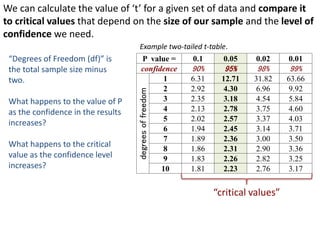
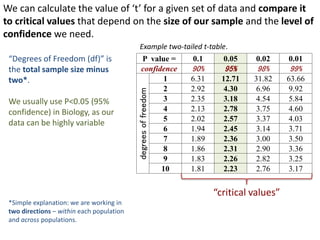
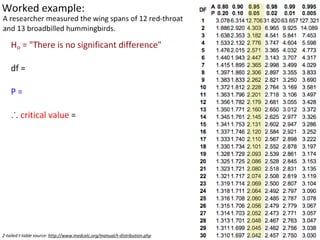
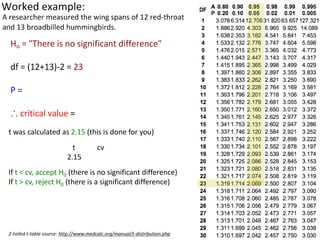
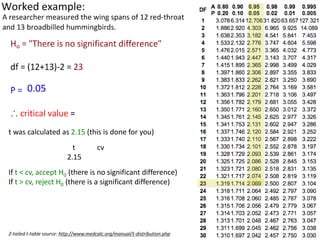
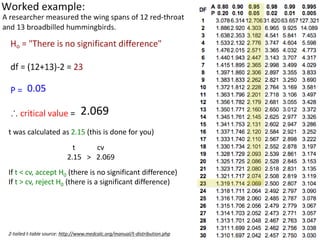
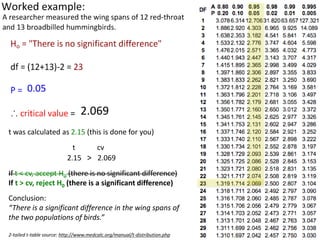
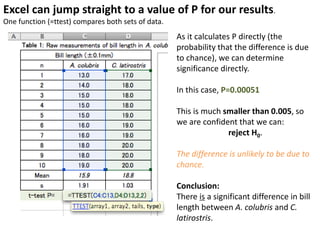
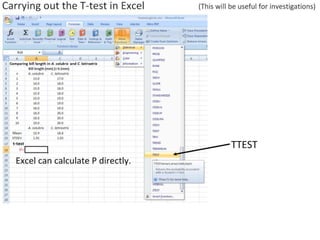
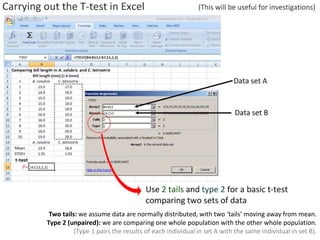
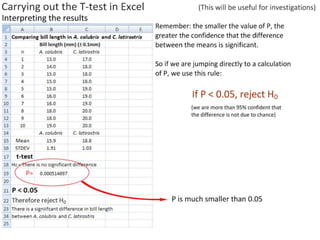
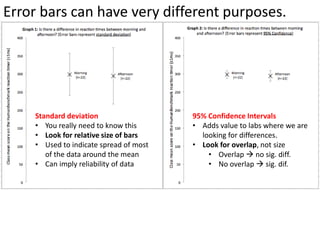
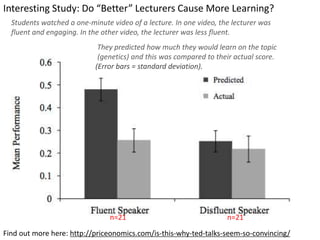
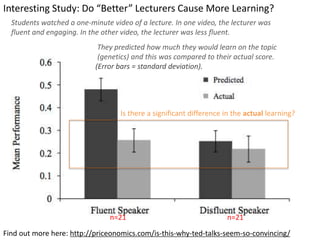
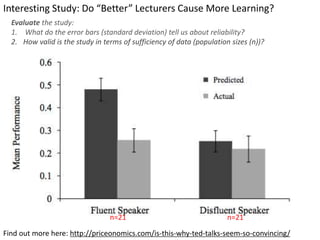
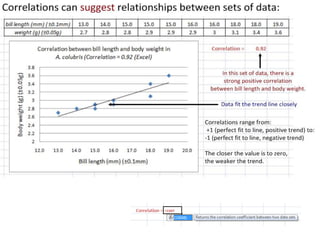
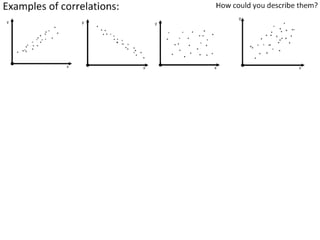
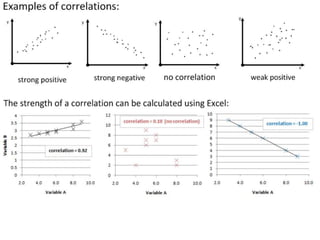
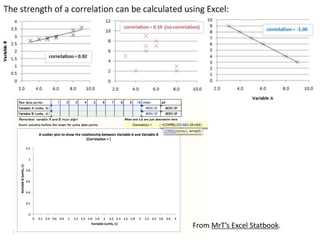
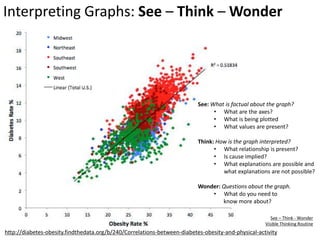
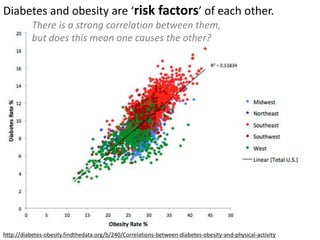
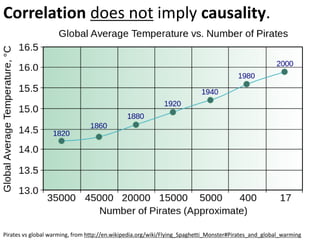
This document outlines objectives and concepts for a unit on statistical analysis in IB Diploma Biology. It discusses types of data, graphs, and statistics including mean, standard deviation, correlation, and significance testing. Key concepts covered are descriptive statistics like mean and standard deviation to summarize data, the importance of variability, and inferential statistics like hypothesis testing and p-values to draw conclusions about populations from samples. The goals are to calculate basic statistics, choose appropriate graphs, understand significance, and apply proper lab techniques and formats.