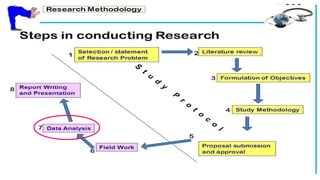
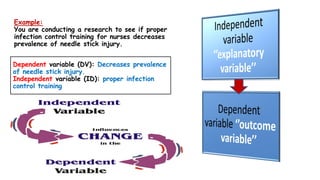
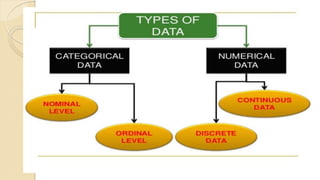
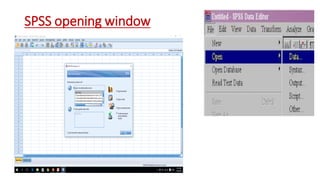
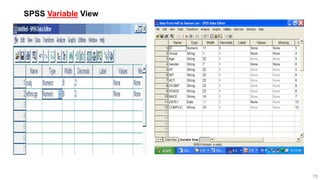
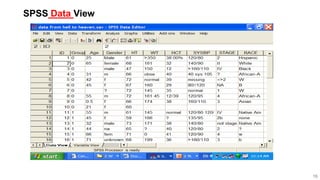
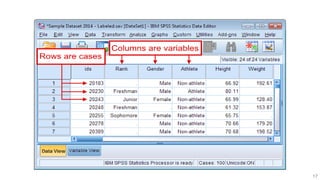
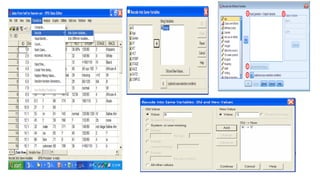
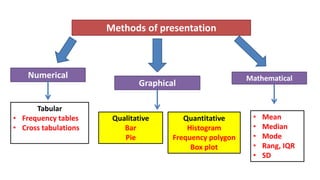
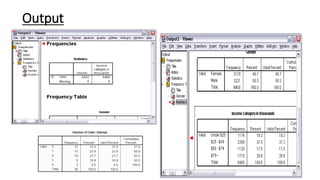
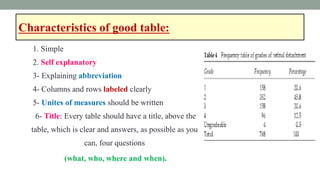
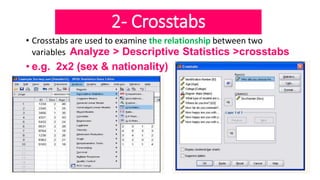
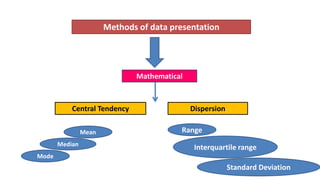
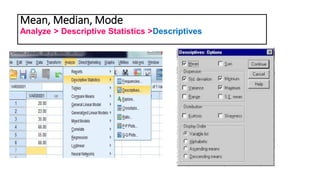
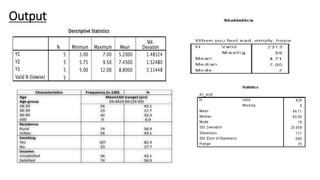
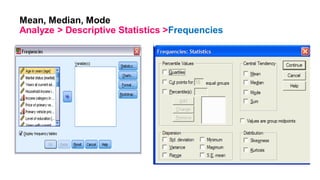
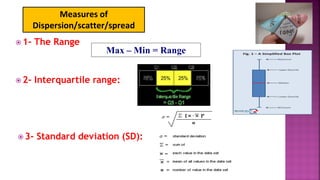
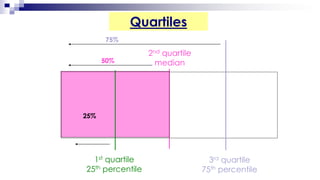
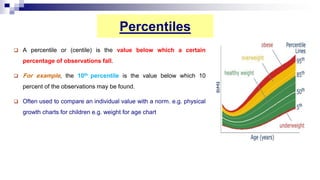
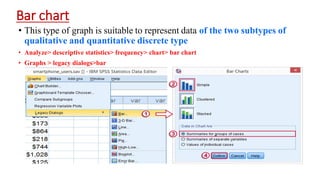
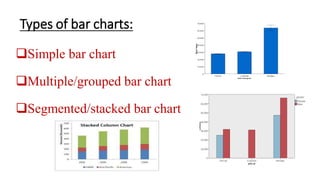
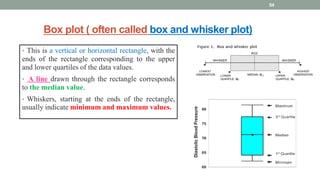
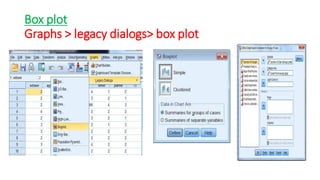
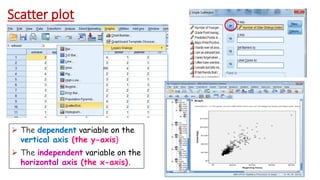
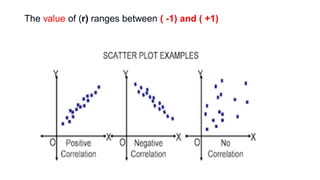
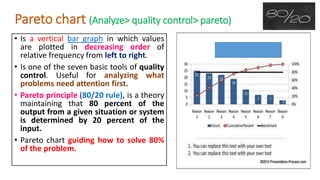
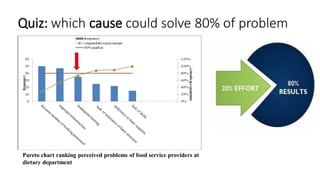
This document provides an overview of how to use SPSS to conduct basic statistical analysis and present results. It outlines expectations for the workshop, including learning how to prepare an SPSS file, display and summarize data, and create graphical presentations. The document then covers key SPSS concepts like variables, data types, and examples. It also demonstrates how to perform descriptive statistics, frequency tables, crosstabs, measures of central tendency and dispersion. Finally, it discusses different methods of graphical presentation in SPSS like bar charts, histograms, box plots and more.