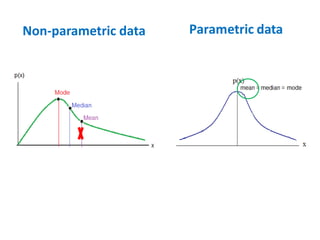
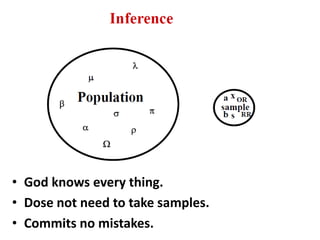
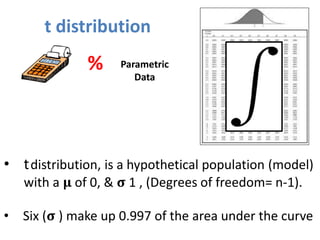
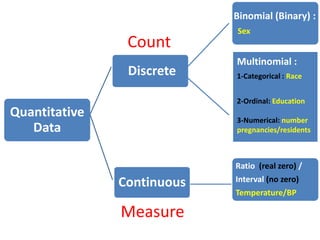
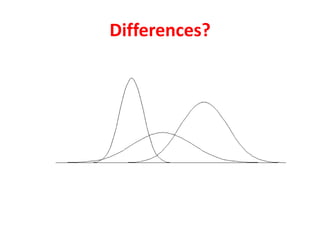
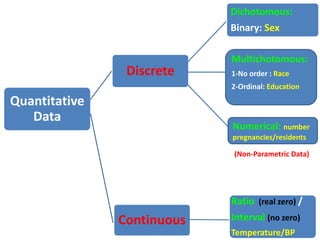
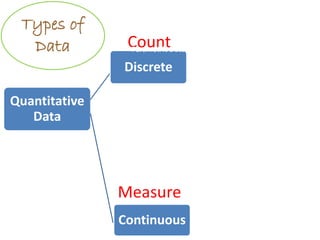
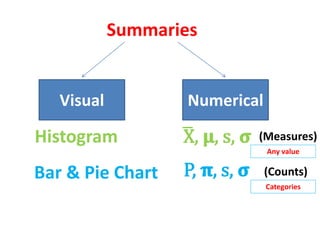
- The document discusses parametric and non-parametric data, describing key differences. Non-parametric data is for small samples and variables that are not normally distributed, requiring no assumptions. Descriptive statistics include range, rank, median, and interquartile range.
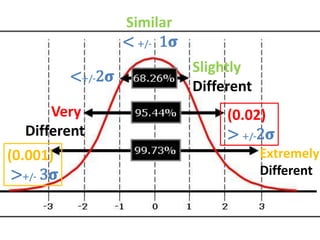
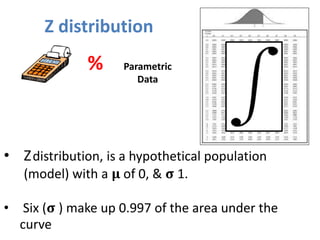
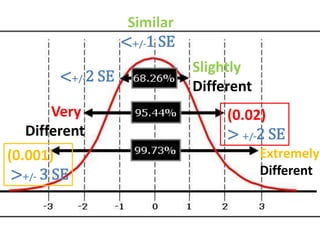
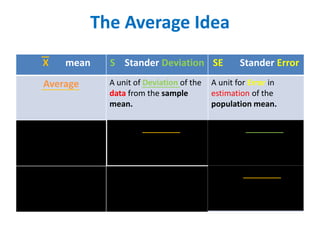
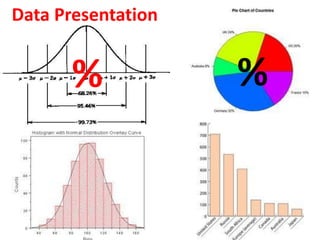
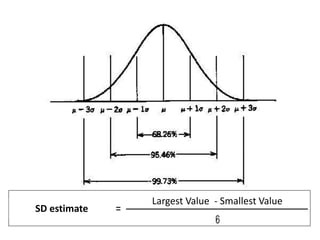
- It also covers topics like mean, standard deviation, standard error, confidence intervals, and the normal and t-distributions as they relate to parametric statistical analysis of sample and population data. The central limit theorem is also referenced.











































































































![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)










![PERI-PROSTHETIC FRACTURE NAIL-PLATE CONSTRUCT [NPC].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/drarunkumardrmohamedashrafperiprostheticfrasturenail-plateconstructnpc-260209164459-7e9d15a1-thumbnail.jpg?width=640&height=640&fit=bounds)
