Recommended
PPTX
論文紹介: Fast R-CNN&Faster R-CNN
PDF
PDF
SSD: Single Shot MultiBox Detector (ECCV2016)
PDF
[DL輪読会] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
PDF
[DL輪読会]VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera
PDF
20130626 kawasaki.rb NKT77
ODP
PDF
20130626 kawasaki.rb NKT77
PDF
20180427 arXivtimes 勉強会: Cascade R-CNN: Delving into High Quality Object Det...
PDF
[DL輪読会]YOLO9000: Better, Faster, Stronger
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
PDF
物体検知(Meta Study Group 発表資料)
PDF
ArtTrack: Articulated Multi-Person Tracking in the Wild : CV勉強会関東
PDF
Variational Kalman Filter
PDF
PDF
Shusaku Taniguchi Bachelor Thesis
PPT
プログラム説明 kgPhotonMapping v0-1-0
PDF
輪読発表資料: Efficient Virtual Shadow Maps for Many Lights
PPTX
[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...
PDF
[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis
PPTX
PPTX
[DL輪読会]Differentiable Mapping Networks: Learning Structured Map Representatio...
PPTX
Rabbit challenge dnn_day3-4
PPTX
PDF
How to Schedule Machine Learning Workloads Nicely In Kubernetes #CNDT2020 / C...
PDF
PPTX
レトリバ勉強会資料:深層学習による自然言語処理2章
PPTX
PDF
【2015.07】(1/2)cvpaper.challenge@CVPR2015
PDF
【2015.05】cvpaper.challenge@CVPR2015
More Related Content
PPTX
論文紹介: Fast R-CNN&Faster R-CNN
PDF
PDF
SSD: Single Shot MultiBox Detector (ECCV2016)
PDF
[DL輪読会] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
PDF
[DL輪読会]VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera
PDF
20130626 kawasaki.rb NKT77
ODP
PDF
20130626 kawasaki.rb NKT77
What's hot
PDF
20180427 arXivtimes 勉強会: Cascade R-CNN: Delving into High Quality Object Det...
PDF
[DL輪読会]YOLO9000: Better, Faster, Stronger
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
PDF
物体検知(Meta Study Group 発表資料)
PDF
ArtTrack: Articulated Multi-Person Tracking in the Wild : CV勉強会関東
PDF
Variational Kalman Filter
PDF
PDF
Shusaku Taniguchi Bachelor Thesis
PPT
プログラム説明 kgPhotonMapping v0-1-0
PDF
輪読発表資料: Efficient Virtual Shadow Maps for Many Lights
PPTX
[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...
PDF
[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis
PPTX
PPTX
[DL輪読会]Differentiable Mapping Networks: Learning Structured Map Representatio...
PPTX
Rabbit challenge dnn_day3-4
PPTX
PDF
How to Schedule Machine Learning Workloads Nicely In Kubernetes #CNDT2020 / C...
PDF
PPTX
レトリバ勉強会資料:深層学習による自然言語処理2章
PPTX
Similar to AGA_CVPR2017
PDF
【2015.07】(1/2)cvpaper.challenge@CVPR2015
PDF
【2015.05】cvpaper.challenge@CVPR2015
PDF
Learning Spatial Common Sense with Geometry-Aware Recurrent Networks
PDF
cvpaper.challenge@CVPR2015(Attribute)
PDF
PDF
【DLゼミ】XFeat: Accelerated Features for Lightweight Image Matching
PDF
CVPR 2019 report (30 papers)
PDF
Fast, Accurate Detection of 100,000 Object Classes on a Single Machine
PDF
(文献紹介)深層学習による動被写体ロバストなカメラの動き推定
PDF
PDF
これからのコンピュータビジョン技術 - cvpaper.challenge in PRMU Grand Challenge 2016 (PRMU研究会 2...
PDF
PDF
PDF
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
PPTX
KantoCV/Selective Search for Object Recognition
PDF
点群SegmentationのためのTransformerサーベイ
PDF
PDF
PFI成果発表会2014発表資料 Where Do You Look?
PPTX
PPTX
CVPR2016読み会 "Inside-Outside Net: Detecting Objects in Context with Skip Pooli...
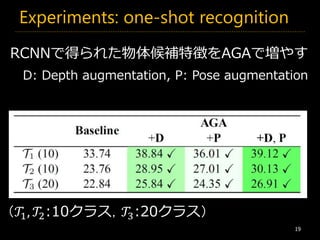
AGA_CVPR2017 1. 2. 3. Data Augmentation
3
Cifar-10, 9層のConvNet [1]
Method error
Without DA 9.08%
With DA 7.25%
With Large DA 4.41%
[1] JT Springenberg, Striving for Simplicity: The All Convolutional Net
学習データを人工的に増やす
flipping random cropping
4. 5. 6. Tables with depth
in the range of 1-2[m]
6
𝐱 = 𝜙 𝐱, 𝑡
目的:𝜙の学習
𝑠. 𝑡. 𝛾 𝐱 = 𝑡
Input: 画像特徴𝐱
output: 画像特徴 𝐱
s.t. アトリビュート𝛾 𝐱 = 𝑡
7. 8. 9. 10. 11. 12. 13. 14. 15. 15
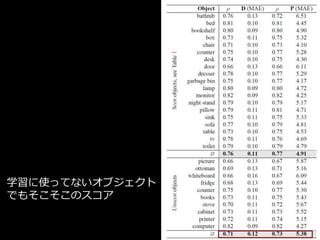
Depth [m] Pose [deg]Median
absolute error
同一クラスで学習 vs クラスを無視して学習
Depth
0.2m, 7.5m
Pose
0°, 180°
データが少ない
(lamp, door)と厳
しい
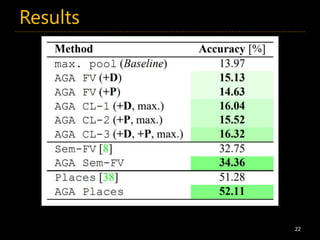
16. 17. 18. 19. 20. Object-based one-shot scene recognition
20
物体検出ネットワークの特徴ベクトルから
シーン認識を行う
AggregateFast RCNN
0.2
−0.8
⋮
0.4
Images from A. Gupta, From 3D Scene Geometry to Human Workspace
SVM
21. 22. 23.



![Data Augmentation
3
Cifar-10, 9層のConvNet [1]
Method error
Without DA 9.08%
With DA 7.25%
With Large DA 4.41%
[1] JT Springenberg, Striving for Simplicity: The All Convolutional Net
学習データを人工的に増やす
flipping random cropping](https://image.slidesharecdn.com/cvpr2017agaupload-170618015918/85/AGA_CVPR2017-3-320.jpg)


![Tables with depth
in the range of 1-2[m]
6
𝐱 = 𝜙 𝐱, 𝑡
目的:𝜙の学習
𝑠. 𝑡. 𝛾 𝐱 = 𝑡
Input: 画像特徴𝐱
output: 画像特徴 𝐱
s.t. アトリビュート𝛾 𝐱 = 𝑡](https://image.slidesharecdn.com/cvpr2017agaupload-170618015918/85/AGA_CVPR2017-6-320.jpg)








![15
Depth [m] Pose [deg]Median
absolute error
同一クラスで学習 vs クラスを無視して学習
Depth
0.2m, 7.5m
Pose
0°, 180°
データが少ない
(lamp, door)と厳
しい](https://image.slidesharecdn.com/cvpr2017agaupload-170618015918/85/AGA_CVPR2017-15-320.jpg)








![[DL輪読会] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields](https://cdn.slidesharecdn.com/ss_thumbnails/realtimemultipersonposeestimation1-170907054459-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera](https://cdn.slidesharecdn.com/ss_thumbnails/dl2018216vnect1-180323034835-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...](https://cdn.slidesharecdn.com/ss_thumbnails/deeplabv3-180309001425-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Parallel WaveNet: Fast High-Fidelity Speech Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/0105-180105000252-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Differentiable Mapping Networks: Learning Structured Map Representatio...](https://cdn.slidesharecdn.com/ss_thumbnails/differentiablemappingnetworks-200707033539-thumbnail.jpg?width=640&height=640&fit=bounds)

























