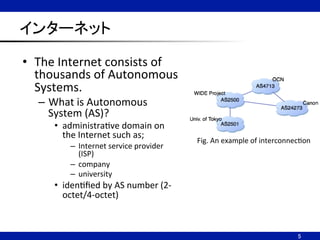
インターネット
• The
Internet
consists
of
thousands
of
Autonomous
Systems.
– What
is
Autonomous
System
(AS)?
• administraNve
domain
on
the
Internet
such
as;
– Internet
service
provider
(ISP)
– company
– university
• idenNfied
by
AS
number
(2-‐
octet/4-‐octet)
5
Fig.
An
example
of
interconnecNon
Ref.
Linux
New
API
“A
straigh+orward
method
of
implemen5ng
a
network
driver
is
to
interrupt
the
kernel
by
issuing
an
interrupt
request
(IRQ)
for
each
and
every
incoming
packet.
However,
servicing
IRQs
is
costly
in
terms
of
processor
resources
and
5me.
Therefore
the
straigh+orward
implementa5on
can
be
very
inefficient
in
high-‐
speed
networks,
constantly
interrup5ng
the
kernel
with
the
thousands
of
packets
per
second.
Overall
performance
of
the
system
as
well
as
network
throughput
can
suffer
as
a
result.”
2014-05-25
ネットワークOS開発録
14
Quoted
from
hBp://en.wikipedia.org/wiki/New_API
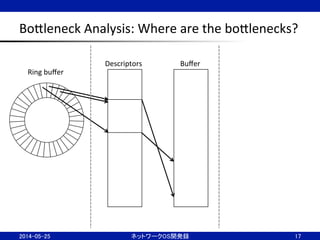
15.
BoBleneck
Analysis:
Where
are
the
boBlenecks?
15
PCIe
CPU
I/O Hub
Integrated
Memory
Controller
CPU
Memory Memory
Integrated
Memory
Controller
(a) (a)
(c)
(b)
I/O
Controller
Hub
On-board NIC
Direct Media Interface
(a) CPU-‐Memory
bus
(N.B.,
64
bit
wide
access)
• DDR3-‐1333
Dual
Channel:
21.333GB/s
(170.667Gbps)
• DDR3-‐1600
Dual
Channel:
25.600GB/s
(204.800Gbps)
• DDR3-‐1866
Dual
Channel:
29.867GB/s
(238.933Gbps)
(b) PCIe
bus
• Gen2:
500MB/s
(x1)
=
4Gbps
• usually
x8
for
a
two-‐port
10GbE
NIC
• x16
is
not
enough
for
a
two-‐port
40GbE
NIC
• Gen3:
985MB/s
(x1)
=
7.88Gbps
(c) DMI
bus
• v1.0:
2GB/s
(1GB/s
per
direcNon
=
8Gbps)
• v2.0:
4GB/s
(2GB/s
per
direcNon
=
16Gbps)
2014-05-25
ネットワークOS開発録
16.
BoBleneck
Analysis:
Where
are
the
boBlenecks?
16
PCIe
CPU
I/O Hub
Integrated
Memory
Controller
CPU
Memory Memory
Integrated
Memory
Controller
(a) (a)
(c)
(b)
I/O
Controller
Hub
On-board NIC
Direct Media Interface
(a) CPU-‐Memory
bus
(N.B.,
64
bit
wide
access)
• DDR3-‐1333
Dual
Channel:
21.333GB/s
(170.667Gbps)
• DDR3-‐1600
Dual
Channel:
25.600GB/s
(204.800Gbps)
• DDR3-‐1866
Dual
Channel:
29.867GB/s
(238.933Gbps)
(b) PCIe
bus
• Gen2:
500MB/s
(x1)
=
4Gbps
• usually
x8
for
a
two-‐port
10GbE
NIC
• x16
is
not
enough
for
a
two-‐port
40GbE
NIC
• Gen3:
985MB/s
(x1)
=
7.88Gbps
(c) DMI
bus
• v1.0:
2GB/s
(1GB/s
per
direcNon
=
8Gbps)
• v2.0:
4GB/s
(2GB/s
per
direcNon
=
16Gbps)
BoBleneck?
2014-05-25
ネットワークOS開発録
BoBleneck?
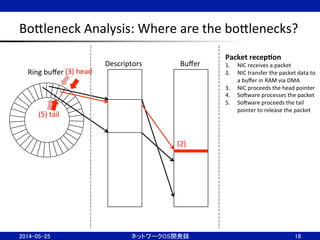
BoBleneck
Analysis:
Where
are
the
boBlenecks?
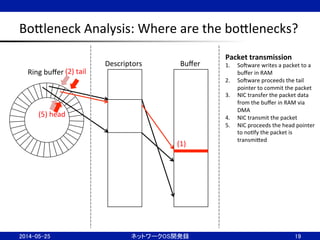
18
Ring
buffer
Descriptors
Buffer
Packet
recep;on
1. NIC
receives
a
packet
2. NIC
transfer
the
packet
data
to
a
buffer
in
RAM
via
DMA
3. NIC
proceeds
the
head
pointer
4. SoJware
processes
the
packet
5. SoJware
proceeds
the
tail
pointer
to
release
the
packet
(3)
head
(2)
(5)
tail
2014-05-25
ネットワークOS開発録
19.
BoBleneck
Analysis:
Where
are
the
boBlenecks?
19
Ring
buffer
Descriptors
Buffer
Packet
transmission
1. SoJware
writes
a
packet
to
a
buffer
in
RAM
2. SoJware
proceeds
the
tail
pointer
to
commit
the
packet
3. NIC
transfer
the
packet
data
from
the
buffer
in
RAM
via
DMA
4. NIC
transmit
the
packet
5. NIC
proceeds
the
head
pointer
to
noNfy
the
packet
is
transmiBed
(2)
tail
(1)
(5)
head
2014-05-25
ネットワークOS開発録
20.
Is
CPU
the
boBleneck?
• 3.3GHz
clock
CPU
– 0.3ns
per
cycle
• 10GbE
NIC
– Max
packet
rate:
14.88Mpps
(64
byte
frame)
• 67ns
per
packet
• Data
access
latency
(*)
– L1
cache:
4-‐5
cycles
~
1.2-‐1.5ns
– L2
cache:
12
cycles
~
3.6ns
– L3
cache:
27.85
cycles
~
8.4ns
– RAM:
28
cycles
+
49-‐56
ns
~
65ns
• Out-‐of-‐order実行/完了やコンパイラの最適化でパイプライ
ン処理されるのでスループットはそこまで悪くない
20
(*)
hBp://www.7-‐cpu.com/cpu/SandyBridge.html
2014-05-25
ネットワークOS開発録
21.
PCIe
Memory
Mapped
I/O
(MMIO)
• Memory
Mapped
I/O
– Address:
BAR
(Base
Address
Register)
+
Offset
• Mapped
to
memory
space
• No
cache
• ~250ns/access
[Miller
et
al.
ACM
ANCS
’09]
21
2014-05-25
ネットワークOS開発録
/* %rdx : txq_head (managed by software) */
loop:
movq txq_tail(bar0),%rcx
/* Vacancy check of the TX queue */
leq %rcx,%rax
jmp loop
/* Write a packet to the TX queue */
...
inc %rcx
movq %rcx,txq_head(bar0)
jmp loop
※本当は
mod
N
が必要(簡略化のため省略)
データハザード:パイプライン化できない
キャッシュしない(+
MPの場合メモリバリア)
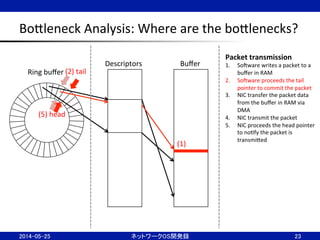
22.
BoBleneck
Analysis:
Where
are
the
boBlenecks?
22
Ring
buffer
Descriptors
Buffer
Packet
recep;on
1. NIC
receives
a
packet
2. NIC
transfer
the
packet
data
to
a
buffer
in
RAM
via
DMA
3. NIC
proceeds
the
head
pointer
4. SoJware
processes
the
packet
5. SoJware
proceeds
the
tail
pointer
to
release
the
packet
(3)
head
(2)
(5)
tail
2014-05-25
ネットワークOS開発録
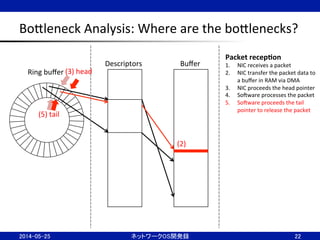
23.
BoBleneck
Analysis:
Where
are
the
boBlenecks?
23
Ring
buffer
Descriptors
Buffer
Packet
transmission
1. SoJware
writes
a
packet
to
a
buffer
in
RAM
2. SoJware
proceeds
the
tail
pointer
to
commit
the
packet
3. NIC
transfer
the
packet
data
from
the
buffer
in
RAM
via
DMA
4. NIC
transmit
the
packet
5. NIC
proceeds
the
head
pointer
to
noNfy
the
packet
is
transmiBed
(2)
tail
(1)
(5)
head
2014-05-25
ネットワークOS開発録
24.
BoBleneck
Analysis:
予備実験
• Simple
soJware
(OS?)
– running
on
1
core
– using
single
Tx/Rx
queue
– ignoring
all
interrupts
– w/o
context-‐switch
(single
task)
– w/o
sleep
(busy
wait)
24
2014-05-25
ネットワークOS開発録
25.
BoBleneck
Analysis:
予備実験
• Procedure
– Prepare
a
UDP
packet
– Send
packets
while
Tx
ring
buffer
is
available
• Set
it
to
a
descriptor
• Commit
(proceed
Tx
tail)
per
n
packets
25
2014-05-25
ネットワークOS開発録
経路探索も実装中
2014-05-25
ネットワークOS開発録
33
Intel®
Core
i7
3770K
w/
Linux
(Ubuntu
12.04)
506194経路
è ~7.5
ns/lookup
(/core)
è (来月実験予定)
具体的なアルゴリズムの話は今回は省略
uint32_t
xor128(void)
{
static uint32_t x = 123456789;
static uint32_t y = 362436069;
static uint32_t z = 521288629;
static uint32_t w = 88675123;
uint32_t t;
t = x ^ (x<<11);
x = y;
y = z;
z = w;
return w = (w ^ (w>>19)) ^ (t ^ (t >> 8));
}
int
main(int argc, char *argv[])
{
...
t0 = getmicrotime();
for ( x = 0; x < 0x10000000LL; x++ ) {
tmp = xor128();
next_hop_ ^= lookup(tcam, 32);
}
t1 = getmicrotime();
...
}
34.
まとめ
• ~67ns
per
packet
(10GbE
line-‐rate)
– No
Nme
to
waste
• BoBlenecks
– Myth
• CPU
• Memory
– Truth
• MMIO
delay
• Other
consideraNons
– Direct
Cache
Access,
Receive
Side
Coalescing/Scaling,
mulN-‐***
etc…
• ToDo
– LinuxのixgbeのTXも賢くできそうなのでやってみる
34
2014-05-25
ネットワークOS開発録









![世の中の技術
• ポーリング・zero-‐copyで高速化
– netmap
– Intel®
DPDK
• ルーティングの高速化
– PacketShader
[Han
et
al.
2011]
– ルーティングテーブルの高速ルックアップ
• DIR24-‐8-‐BASIC
[Gupta
et
al.
1998]
• DXR
[Zec
et
al.
2012]
• Luleå
algorithm
• HAT-‐trie
[AskiNs
et
al.
2007]
• Fast
Address
Lookups
Using
Controlled
Prefix
Expansion
[SRINIVASAN
et
al.
1999]
ネットワークOS開発録
11
2014-05-25](https://image.slidesharecdn.com/kernel-vm-2014-05-25-140526070605-phpapp02/85/Kernel-vm-2014-05-25-11-320.jpg)






![PCIe
Memory
Mapped
I/O
(MMIO)
• Memory
Mapped
I/O
– Address:
BAR
(Base
Address
Register)
+
Offset
• Mapped
to
memory
space
• No
cache
• ~250ns/access
[Miller
et
al.
ACM
ANCS
’09]
21
2014-05-25
ネットワークOS開発録
/* %rdx : txq_head (managed by software) */
loop:
movq txq_tail(bar0),%rcx
/* Vacancy check of the TX queue */
leq %rcx,%rax
jmp loop
/* Write a packet to the TX queue */
...
inc %rcx
movq %rcx,txq_head(bar0)
jmp loop
※本当は
mod
N
が必要(簡略化のため省略)
データハザード:パイプライン化できない
キャッシュしない(+
MPの場合メモリバリア)](https://image.slidesharecdn.com/kernel-vm-2014-05-25-140526070605-phpapp02/85/Kernel-vm-2014-05-25-21-320.jpg)



![BoBleneck
Analysis:
Transmission
Performance
28
0
100
200
300
400
500
600
700
800
900
1000
0 200 400 600 800 1000 1200 1400 1600
Throughput[Mbps]
Frame size [byte]
(1) w/o MULR
(2) w/ MULR
(3) w/ MULR + 16 pkt bulk
Linux
Line rate
0
1
2
3
4
5
6
7
8
9
10
0 200 400 600 800 1000 1200 1400 1600
Throughput[Gbps] Frame size [byte]
Bulk transfer size b=1
b=2
b=4
b=8
b=16
b=32
b=64
b=128
Linux
Line rate
e1000e
ixgbe
CPU:
Intel(R)
Core(TM)
i3
330M
(2.13GHz,
dual
core)
Memory:
4GiB,
DDR3-‐1333
NIC:
Intel(R)
82577LM
(1
port)
CPU:
Intel(R)
Core(TM)
i7
4770K
(3.90GHz,
quad
core)
Memory:
32GiB,
DDR3-‐1866
NIC:
Intel(R)
X520-‐DA2
(2
ports)
2014-05-25
ネットワークOS開発録](https://image.slidesharecdn.com/kernel-vm-2014-05-25-140526070605-phpapp02/85/Kernel-vm-2014-05-25-28-320.jpg)
![BoBleneck
Analysis:
Transmission
Performance
29
0
2
4
6
8
10
12
14
1 10 100 1000
Packetrate[Mpps]
Bulk transfer size [packets]
Frame size = 64B
96B
128B
192B
256B
384B
512B
768B
1024B
1536B
X
Y
Z
CPU:
Intel(R)
Core(TM)
i7
4770K
(3.90GHz,
quad
core)
Memory:
32GiB,
DDR3-‐1866
NIC:
Intel(R)
X520-‐DA2
(2
ports)
2014-05-25
ネットワークOS開発録](https://image.slidesharecdn.com/kernel-vm-2014-05-25-140526070605-phpapp02/85/Kernel-vm-2014-05-25-29-320.jpg)

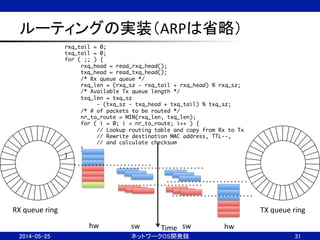
![ルーティング性能は?
32
0
100
200
300
400
500
600
700
800
900
1000
0 200 400 600 800 1000 1200 1400 1600
Throughput[Mbps]
Frame size [byte]
My implementation
Linux
Line rate
0
1
2
3
4
5
6
7
8
9
10
0 200 400 600 800 1000 1200 1400 1600Throughput[Gbps]
Frame size [byte]
My implementation
Linux
Line rate
※
IPv4
1
route
Transmitter Router
RX TX
RX
untag
tag
tag
Transmitter Router
RX TX
RX
untag
untag
untag
CPU:
Intel(R)
Core(TM)
i7
M620
(2.67GHz,
dual
core)
Memory:
8GiB,
DDR3-‐1333
NIC:
Intel(R)
82577LM
(1
port)
CPU:
Intel(R)
Core(TM)
i7
4770K
(3.90GHz,
quad
core)
Memory:
32GiB,
DDR3-‐1866
NIC:
Intel(R)
X520-‐DA2
(2
ports)
2014-05-25
ネットワークOS開発録](https://image.slidesharecdn.com/kernel-vm-2014-05-25-140526070605-phpapp02/85/Kernel-vm-2014-05-25-32-320.jpg)
![経路探索も実装中
2014-05-25
ネットワークOS開発録
33
Intel®
Core
i7
3770K
w/
Linux
(Ubuntu
12.04)
506194経路
è ~7.5
ns/lookup
(/core)
è (来月実験予定)
具体的なアルゴリズムの話は今回は省略
uint32_t
xor128(void)
{
static uint32_t x = 123456789;
static uint32_t y = 362436069;
static uint32_t z = 521288629;
static uint32_t w = 88675123;
uint32_t t;
t = x ^ (x<<11);
x = y;
y = z;
z = w;
return w = (w ^ (w>>19)) ^ (t ^ (t >> 8));
}
int
main(int argc, char *argv[])
{
...
t0 = getmicrotime();
for ( x = 0; x < 0x10000000LL; x++ ) {
tmp = xor128();
next_hop_ ^= lookup(tcam, 32);
}
t1 = getmicrotime();
...
}](https://image.slidesharecdn.com/kernel-vm-2014-05-25-140526070605-phpapp02/85/Kernel-vm-2014-05-25-33-320.jpg)

















![[D20] 高速Software Switch/Router 開発から得られた高性能ソフトウェアルータ・スイッチ活用の知見 (July Tech Fest...](https://cdn.slidesharecdn.com/ss_thumbnails/jtf20182-180803022253-thumbnail.jpg?width=640&height=640&fit=bounds)


























![[Basic 7] OS の基本 / 割り込み / システム コール / メモリ管理](https://cdn.slidesharecdn.com/ss_thumbnails/basic-07-180228134341-thumbnail.jpg?width=640&height=640&fit=bounds)
![[G-Tech2014講演資料] シスコのSDN最新動向とITインフラエンジニアに求められるスキル - シスコシステムズ合同会社](https://cdn.slidesharecdn.com/ss_thumbnails/d-2sdnit-141020222301-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


