Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Takanori Ogata
2,198 views
180204 Attention-aware Deep Reinforcement Learning for Video Face Recognition
Attention-aware Deep Reinforcement Learning for Video Face Recognition, ICCV 2017
Technology
◦
Related topics:
Computer Vision Insights
•
Read more
2
Save
Share
Embed
Embed presentation
1
/ 32
2
/ 32
3
/ 32
4
/ 32
5
/ 32
6
/ 32
7
/ 32
8
/ 32
9
/ 32
10
/ 32
11
/ 32
12
/ 32
13
/ 32
14
/ 32
15
/ 32
16
/ 32
17
/ 32
18
/ 32
19
/ 32
20
/ 32
21
/ 32
22
/ 32
23
/ 32
24
/ 32
25
/ 32
26
/ 32
27
/ 32
28
/ 32
29
/ 32
30
/ 32
31
/ 32
32
/ 32
More Related Content
PDF
Unsupervised learning of object landmarks by factorized spatial embeddings
by
Takanori Ogata
PDF
Annotating object instances with a polygon rnn
by
Takanori Ogata
PDF
Training object class detectors with click supervision
by
Takanori Ogata
PDF
pytech
by
Kanta Kato
PPTX
Invariant Information Clustering for Unsupervised Image Classification and Se...
by
harmonylab
PPTX
【Dll171201】深層学習利活用の紹介 掲載用
by
Hirono Jumpei
PDF
BERT の解剖学: interpret-text による自然言語処理 (NLP) モデル解釈
by
順也 山口
PPTX
G Suite勉強会資料(20200326)
by
Keiichi Hirose
Unsupervised learning of object landmarks by factorized spatial embeddings
by
Takanori Ogata
Annotating object instances with a polygon rnn
by
Takanori Ogata
Training object class detectors with click supervision
by
Takanori Ogata
pytech
by
Kanta Kato
Invariant Information Clustering for Unsupervised Image Classification and Se...
by
harmonylab
【Dll171201】深層学習利活用の紹介 掲載用
by
Hirono Jumpei
BERT の解剖学: interpret-text による自然言語処理 (NLP) モデル解釈
by
順也 山口
G Suite勉強会資料(20200326)
by
Keiichi Hirose
What's hot
PDF
【メタサーベイ】Face, Gesture, and Body Pose
by
cvpaper. challenge
PDF
NeurIPS2021読み会 Fairness in Ranking under Uncertainty
by
Tatsuya Shirakawa
PDF
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
PDF
いまさら聞けない機械学習の評価指標
by
圭輔 大曽根
PDF
CVPR 2020報告
by
日本ディープラーニング協会(JDLA)
PDF
2021 10-07 kdd2021読み会 uc phrase
by
Tatsuya Shirakawa
PDF
[クリエイティブハント2018]LT 道場破りしたらできちゃった/// #ゴーハント
by
Hiroyuki Ishikawa
PPTX
Microsoft AI Solution Update / DLL community Update
by
Hirono Jumpei
PDF
いまさら学ぶオブジェクト指向
by
Daisuke Hirayama
【メタサーベイ】Face, Gesture, and Body Pose
by
cvpaper. challenge
NeurIPS2021読み会 Fairness in Ranking under Uncertainty
by
Tatsuya Shirakawa
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
いまさら聞けない機械学習の評価指標
by
圭輔 大曽根
CVPR 2020報告
by
日本ディープラーニング協会(JDLA)
2021 10-07 kdd2021読み会 uc phrase
by
Tatsuya Shirakawa
[クリエイティブハント2018]LT 道場破りしたらできちゃった/// #ゴーハント
by
Hiroyuki Ishikawa
Microsoft AI Solution Update / DLL community Update
by
Hirono Jumpei
いまさら学ぶオブジェクト指向
by
Daisuke Hirayama
Similar to 180204 Attention-aware Deep Reinforcement Learning for Video Face Recognition
PDF
20190804_icml_kyoto
by
Takayoshi Yamashita
PPTX
CVPR2017 参加報告 速報版 本会議 2日目
by
Atsushi Hashimoto
PDF
夏のトップカンファレンス論文読み会 / Realtime Multi-Person 2D Pose Estimation using Part Affin...
by
Shunsuke Ono
PDF
輪講用資料「Deep Convolutional Network Cascade for Facial Point Detection」
by
Saya Katafuchi
PPTX
SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習
by
SSII
PDF
CVPR2016読み会 Sparsifying Neural Network Connections for Face Recognition
by
Koichi Takahashi
PDF
20201010 personreid
by
Takuya Minagawa
PDF
論文輪読資料「FaceNet: A Unified Embedding for Face Recognition and Clustering」
by
Kaoru Nasuno
PDF
MIRU_Preview_JSAI2019
by
Takayoshi Yamashita
PPTX
CVPR2018 参加報告(速報版)初日
by
Atsushi Hashimoto
PPTX
Crowd Counting & Detection論文紹介
by
Plot Hong
PDF
論文紹介:Facial Action Unit Detection using Active Learning and an Efficient Non-...
by
Kazuki Adachi
PDF
顔認識の未来について語ろう! (CVPR 2018 完全読破チャレンジ報告会)
by
cvpaper. challenge
PPTX
【DL輪読会】ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Deep Learning JP
PPTX
「解説資料」ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Takumi Ohkuma
PDF
【2015.05】cvpaper.challenge@CVPR2015
by
cvpaper. challenge
PDF
Retail Face Analysis Inside-Out
by
Tatsuya Shirakawa
ODP
Introduction to "Facial Landmark Detection by Deep Multi-task Learning"
by
Yukiyoshi Sasao
PPTX
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
PDF
畳み込みニューラルネットワークによる画像分類について
by
Masato Miwada
20190804_icml_kyoto
by
Takayoshi Yamashita
CVPR2017 参加報告 速報版 本会議 2日目
by
Atsushi Hashimoto
夏のトップカンファレンス論文読み会 / Realtime Multi-Person 2D Pose Estimation using Part Affin...
by
Shunsuke Ono
輪講用資料「Deep Convolutional Network Cascade for Facial Point Detection」
by
Saya Katafuchi
SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習
by
SSII
CVPR2016読み会 Sparsifying Neural Network Connections for Face Recognition
by
Koichi Takahashi
20201010 personreid
by
Takuya Minagawa
論文輪読資料「FaceNet: A Unified Embedding for Face Recognition and Clustering」
by
Kaoru Nasuno
MIRU_Preview_JSAI2019
by
Takayoshi Yamashita
CVPR2018 参加報告(速報版)初日
by
Atsushi Hashimoto
Crowd Counting & Detection論文紹介
by
Plot Hong
論文紹介:Facial Action Unit Detection using Active Learning and an Efficient Non-...
by
Kazuki Adachi
顔認識の未来について語ろう! (CVPR 2018 完全読破チャレンジ報告会)
by
cvpaper. challenge
【DL輪読会】ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Deep Learning JP
「解説資料」ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Takumi Ohkuma
【2015.05】cvpaper.challenge@CVPR2015
by
cvpaper. challenge
Retail Face Analysis Inside-Out
by
Tatsuya Shirakawa
Introduction to "Facial Landmark Detection by Deep Multi-task Learning"
by
Yukiyoshi Sasao
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
畳み込みニューラルネットワークによる画像分類について
by
Masato Miwada
More from Takanori Ogata
PDF
20210108 Tread: Circuits
by
Takanori Ogata
PDF
20200704 Deep Snake for Real-Time Instance Segmentation
by
Takanori Ogata
PDF
CVPR2019読み会@関東CV
by
Takanori Ogata
PDF
190412 Annotation Survey@関東CV勉強会
by
Takanori Ogata
PDF
190410 ML@LOFT
by
Takanori Ogata
PDF
SSD: Single Shot MultiBox Detector (ECCV2016)
by
Takanori Ogata
PDF
160924 Deep Learning Tuningathon
by
Takanori Ogata
PDF
Convolutional Pose Machines
by
Takanori Ogata
PDF
Deep Learningライブラリ 色々つかってみた感想まとめ
by
Takanori Ogata
PDF
Cv20160205
by
Takanori Ogata
PDF
10分でわかる主成分分析(PCA)
by
Takanori Ogata
PPTX
DeepAKB
by
Takanori Ogata
20210108 Tread: Circuits
by
Takanori Ogata
20200704 Deep Snake for Real-Time Instance Segmentation
by
Takanori Ogata
CVPR2019読み会@関東CV
by
Takanori Ogata
190412 Annotation Survey@関東CV勉強会
by
Takanori Ogata
190410 ML@LOFT
by
Takanori Ogata
SSD: Single Shot MultiBox Detector (ECCV2016)
by
Takanori Ogata
160924 Deep Learning Tuningathon
by
Takanori Ogata
Convolutional Pose Machines
by
Takanori Ogata
Deep Learningライブラリ 色々つかってみた感想まとめ
by
Takanori Ogata
Cv20160205
by
Takanori Ogata
10分でわかる主成分分析(PCA)
by
Takanori Ogata
DeepAKB
by
Takanori Ogata
180204 Attention-aware Deep Reinforcement Learning for Video Face Recognition
1.
Attention-aware Deep Reinforcement Learning for
Video Face Recognition Takanori Ogata
2.
Self Introduction 緒方 貴紀
(@conta_) Co-Founder / Chief Research Officer @ABEJA, Inc. 基礎研究から、プロダクト開発、クラウドからGPUマシンの組み立てまで なんでもやります。
3.
Videoに写った人の顔認証の精度を上げる論文 同一人物の1連の顔画像シーケンスから、顔認証 に使うと良さそうな画像をピックアップして異な る動画に写った同一人物の認証精度を上げる Attentionを見つける過程をMarkov decision processでモデリングすることで、 強化学習(Q- learning)の枠組みに入れ学習できる 提案手法では、人物ID以外の追加の教師データ なしに学習させることが可能 概要
4.
■静止画の顔認証 1枚の画像に写った1人の顔画像を比較して、同じかどうかを判定 ■動画の顔認証 1本の動画に写った1人の顔のシーケンス画像を、同じかどうかを判定 動画像の顔認証 Same or not Same
or not
5.
• 人の移動によりブラーがおこる • 画像の輝度が時系列で変わる •
顔の向きが変わる Þ1人の顔画像でも特徴に分散が出てしまう 見分けやすい顔だけ使っていきたい! クオリティーの低そうな顔画像だけを取り除けないか? 動画像の顔認証の難しさ
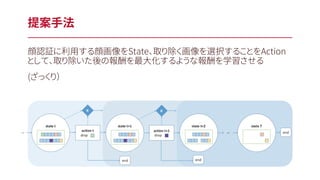
6.
顔認証に利用する顔画像をState、取り除く画像を選択することをAction として、取り除いた後の報酬を最大化するような報酬を学習させる (ざっくり) 提案手法
7.
前準備が多いです わかりにくいプレゼンになると思いますので適時質問 してください
8.
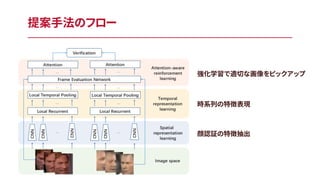
提案手法のフロー 顔認証の特徴抽出 時系列の特徴表現 強化学習で適切な画像をピックアップ
9.
フレーム間の特徴の関係は顔認証する上で重要なヒントになりうる =>動画フレームから取り出した特徴をbi-directional LSTMを利用して時 系列に計算しtemporal-poolingを行う Temporal Representation
Learning 動画AがN^Aフレームの顔画像 C_1: CNN(顔認証の特徴抽出機) bi-directional LSTM Temporal Representation (隣接するr個のみの特徴を計算)
10.
(前置き) 2つの動画の顔を比較するときの距離の定義は下記の通り Attention-aware Deep
Reinforcement Learning 𝑋" , 𝑋$ : シーケンス顔画像 a_i のことをこの論文ではAttention(hard attention)と呼んでいる
11.
多くの先行研究では、Attentionのweightを計算す る際にfeature vectorの関係を利用している しかしながら、一般的に顔認証の特徴抽出アルゴリ ズムはpose /
illumination / expressionなどに不 変な特徴として学習させている => 顔の特徴空間だけでなく、顔画像から直接 Attentionを計算するようなアルゴリズムが良いの ではないか? Attention-aware Deep Reinforcement Learning [Yang+, CVPR2017]
12.
今回の提案手法として、特徴空間からだけでなく、画像から直接 Attentionを計算出来るようにしたいので、強化学習させる際に、報酬を出 力するネットワークC_2を考えたい Attention-aware Deep Reinforcement
Learning I_i: 画像空間からくる情報 M_i: 特徴空間からくる情報 C_2(I, M)を追加の教師データ無しに学習させるために、 エキスパートとして顔認証CNNである、C_1(x)の認識精度を活用する
13.
画像シーケンスから適切な画像をピックアップするには、2つの戦略が考えら れる (1) frame情報からダイレクトにクオリティーを計測し、高いものを持ってくる (2) クオリティーの低いものをStep
by Stepで取り除いていく Þ(1)の戦略は教師データがないと厳しい、、、 (2)では、認証精度の増減を見るだけで良いので、ラベルなしでも出来る! 今回の手法では(2)の方法を取る 顔認証にベストな画像を探すには?
14.
認証に利用する顔画像の組み合わせをStateとして、1枚ずつ画像を減ら していき、減らしたときの精度を計算 Þ精度が上がるような(落ちないような)組み合わせを求める 前の状態からの差分どうなったかの問題に落ちるので、Markov decision processに出来る ->
強化学習で解ける 基本的な戦略
15.
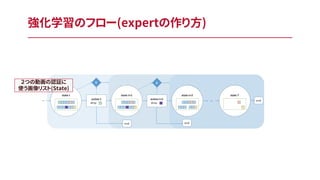
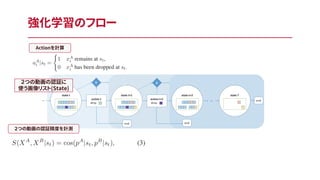
強化学習のフロー(expertの作り方) 2つの動画の認証に 使う画像リスト(State)
16.
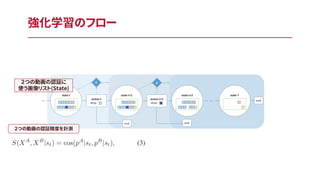
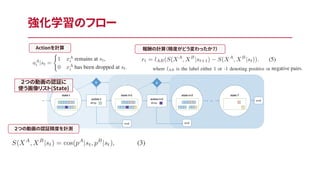
強化学習のフロー 2つの動画の認証精度を計測 2つの動画の認証に 使う画像リスト(State)
17.
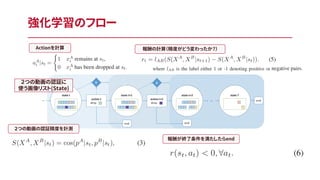
強化学習のフロー 2つの動画の認証に 使う画像リスト(State) 2つの動画の認証精度を計測 Actionを計算
18.
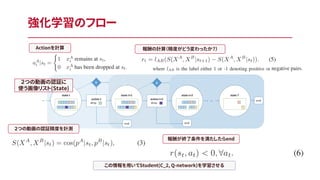
強化学習のフロー 2つの動画の認証に 使う画像リスト(State) 2つの動画の認証精度を計測 報酬の計算(精度がどう変わったか?)Actionを計算
19.
強化学習のフロー 2つの動画の認証に 使う画像リスト(State) 2つの動画の認証精度を計測 報酬の計算(精度がどう変わったか?)Actionを計算 報酬が終了条件を満たしたらend
20.
強化学習のフロー 2つの動画の認証に 使う画像リスト(State) 2つの動画の認証精度を計測 報酬の計算(精度がどう変わったか?)Actionを計算 報酬が終了条件を満たしたらend この情報を用いてStudent(C_2, Q-network)を学習させる
21.
Q関数はどう設計するのか 今回の手法ではQ関数の実装にNNを用いるが、その際2パターンの設計が考えられる • (1)Stateをinputにしてすべての取りうるactionに対するQ-valueを出力(DQN的なもの) • (2)Stateとactionを入れて、単一のQ-valueを出力 今回の場合、Stateが変わるたびにAction(Dropする場所)が変わってしまうので、(1)のパ ターンは難しい =>
よって今回は(2)のパターンを利用する
22.
画像xと特徴空間から計算されたvを入力として、Qを出力 するようなネットワーク v_iは4つのpartsからなる(2つの統計量をA,Bの動画から それぞれ出力、合計4つ) Q関数の実装 Drop前後での特徴の変化 State tのときに、aによってDropしたfeature h_aを引いたもの (これ合ってるの?
p^Aの定義と合わない気がするけど) そしてこれを最適化する Dropした後の特徴量の分散
23.
アルゴリズム(学習)
24.
学習させたQ関数を用いて、逐次的に Dropさせ、A, Bそれぞれ含まれるフ レーム数がthreshold以下になるまで 繰り返す。 アルゴリズム(識別)
25.
下記のデータセットで実験 • YouTube Face
dataset (YTF) • Point- and-Shoot Challenge (PaSC) • Youtube celebrities dataset (YTC) BaseとなるCNNは論文中[40](Center Loss)を利用 Experiments [Wen+, ECCV2016]
26.
■SOTAの比較 deep FR以外には勝ってる Results on
YouTube Face Dataset (deep FRは正面画像をきれいに 選んだりTriplet Lossの学習の際 にデータ選択を工夫しまくってる から負けてるだけなんだからね! こっちの実装のほうが簡単なんだ からねっ! By 著者)
27.
■Attentionの効果の比較 NANというAttention baseの手 法と比較 Temporal Ansamble(TR)と ADRLは効果がある(と言ってい る) Results
on YouTube Face Dataset NAN [Yang+, CVPR2017] (彼らは自分らよりパワフルな ネットワーク使ってるけどな!By 著者)
28.
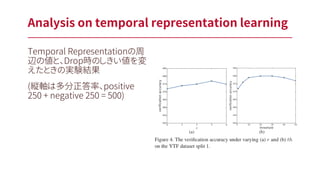
Analysis on temporal
representation learning Temporal Representationの周 辺の値と、Drop時のしきい値を変 えたときの実験結果 (縦軸は多分正答率、positive 250 + negative 250 = 500)
29.
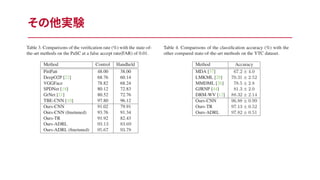
その他実験
30.
Qでソートした結果の定性評価 Analysis on deep
reinforcement learning
31.
動画の顔認証の精度を上げるために最適な画像を選択する方法の提案 認証に利用する顔画像の選択方法をMarkov decision processに落とす ことで強化学習の枠組みを適用できた 顔画像の良し悪しを、顔認証精度の比較問題に落とすことでexpertを作り、 追加ラベル無しでQ学習の枠組みに落とした 大体SOTAの精度がでた まとめ
32.
We are finding
awesome researchers! Please contact us! Mail: recruit@abeja.asia https://www.wantedly.com/companies/abeja









![多くの先行研究では、Attentionのweightを計算す
る際にfeature vectorの関係を利用している
しかしながら、一般的に顔認証の特徴抽出アルゴリ
ズムはpose / illumination / expressionなどに不
変な特徴として学習させている
=> 顔の特徴空間だけでなく、顔画像から直接
Attentionを計算するようなアルゴリズムが良いの
ではないか?
Attention-aware Deep Reinforcement Learning
[Yang+, CVPR2017]](https://image.slidesharecdn.com/180203attentionaware-180204062843/85/180204-Attention-aware-Deep-Reinforcement-Learning-for-Video-Face-Recognition-11-320.jpg)







を利用
Experiments
[Wen+, ECCV2016]](https://image.slidesharecdn.com/180203attentionaware-180204062843/85/180204-Attention-aware-Deep-Reinforcement-Learning-for-Video-Face-Recognition-25-320.jpg)

![■Attentionの効果の比較
NANというAttention baseの手
法と比較
Temporal Ansamble(TR)と
ADRLは効果がある(と言ってい
る)
Results on YouTube Face Dataset
NAN [Yang+, CVPR2017]
(彼らは自分らよりパワフルな
ネットワーク使ってるけどな!By
著者)](https://image.slidesharecdn.com/180203attentionaware-180204062843/85/180204-Attention-aware-Deep-Reinforcement-Learning-for-Video-Face-Recognition-27-320.jpg)


















![[クリエイティブハント2018]LT 道場破りしたらできちゃった/// #ゴーハント](https://cdn.slidesharecdn.com/ss_thumbnails/chy2018-lt-coderdojo-community-181031162644-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)












