More Related Content

PDF

PDF
入門 Kubeflow ~Kubernetesで機械学習をはじめるために~ (NTT Tech Conference #4 講演資料) 
PDF
MLOps に基づく AI/ML 実運用最前線 ~画像、動画データにおける MLOps 事例のご紹介~(映像情報メディア学会2021年冬季大会企画セッショ... 
PPTX
リクルートを支える横断データ基盤と機械学習の適用事例 
PPTX

PDF
ブレインパッドにおける機械学習プロジェクトの進め方 
PDF

PDF
What's hot

PPTX
PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築 
PDF
分散学習のあれこれ~データパラレルからモデルパラレルまで~ 
PPTX
![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送 
PDF

PDF

PDF

PDF
Amazon SageMaker で始める機械学習 
PPTX

PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp 
PPTX
学習時に使ってはいないデータの混入「リーケージを避ける」 
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 ![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing 
PDF

PDF

PDF

PDF

PDF
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision 
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021) Similar to MLOps入門

PDF

PDF
Getting started with MLOps 
PPTX
Amazon SageMakerでゼロからはじめる機械学習入門 
PPTX
Amazon SageMaker の紹介 + デモ ![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
![[CTO Night & Day 2019] ML services: MLOps #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessionml-191027185903-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[CTO Night & Day 2019] ML services: MLOps #ctonight 
PDF

PDF
Hands on-ml section1-1st-half-20210317 
PDF

PPTX

PDF
MLOpsの概要と初学者が気をつけたほうが良いこと 
PDF

PDF
Azure Machine Learning� getting started 
PDF

PDF
Amazon SageMaker: 機械学習の民主化から工業化へ(in Japanese) 
PPTX
機械学習プラットフォーム5つの課題とAmazon SageMakerの4つの利点 
PDF
Machine learning for biginner 
PPTX

PPTX
MLOpsを機械学習モデル改善の観点から考察.pptx 
PPTX
1028 TECH & BRIDGE MEETING MLOps入門
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
実際に機械学習を使い始めるには
• プログラミング言語:
• 機械学習用ライブラリが豊富なためPython を使うのが一般的です
• R 、Java、Go、Rubyなども一応可能(事前設定や制約あり)
• 環境準備:
• Google Colaboratory が一番早いです
• SaaSサービスで、Googleアカウントがあればコーディングをすぐに始められます
• GPUは無料版の場合 Tesla K80
• MLOpsではNotebookに書いたコードをパイプラインに使う
スクリプトに利用できるのでここでモデル開発に慣れておくのが良い
• Pythonライブラリ:
※SaaS版JupyterNotebook
- 9.
- 10.
- 11.
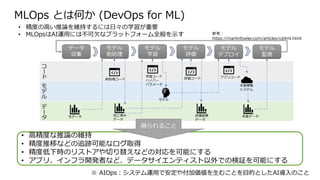
MLOps とは何か (DevOpsfor ML)
• 高精度な推論の維持
• 精度推移などの追跡可能なログ取得
• 精度低下時のリストアや切り替えなどの対応を可能にする
• アプリ、インフラ開発者など、データサイエンティスト以外での検証を可能にする
※ AIOps:システム運用で安定や付加価値を生むことを目的としたAI導入のこと
参考:
https://martinfowler.com/articles/cd4ml.html
コ
ー
ド
モ
デ
ル
デ
ー
タ
データ
収集
モデル
前処理
モデル
学習
モデル
評価
モデル
デプロイ
モデル
監視
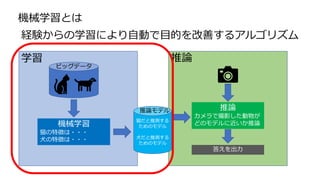
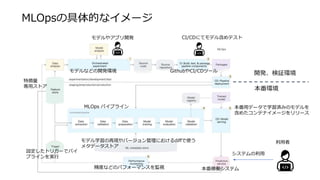
• 精度の高い推論を維持するには日々の学習が重要
• MLOpsはAI運用には不可欠なプラットフォーム全般を示す
前処理コード
生データ 加工済み
データ
評価結果
データ
本番データ
学習コード
ハイパー
パラメータ 本番稼働
システム
モデル
評価コード アプリコード
得られること
- 12.
- 13.
- 14.
- 15.
- 16.
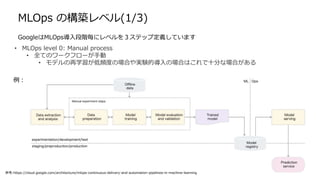
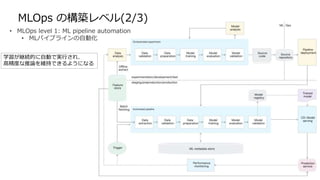
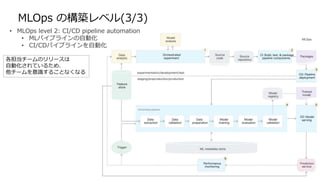
MLOps の構築レベル(3/3)
• MLOpslevel 2: CI/CD pipeline automation
• MLパイプラインの自動化
• CI/CDパイプラインを自動化
各担当チームのリリースは
自動化されているため、
他チームを意識することなくなる
- 17.
- 18.
- 19.
- 20.
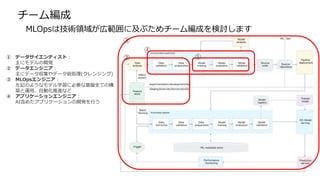
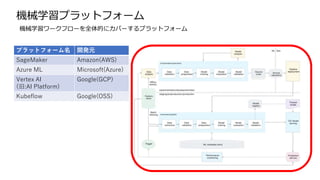
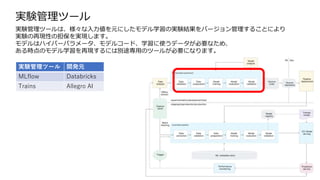
実験管理ツール 開発元
MLflow Databricks
TrainsAllegro AI
実験管理ツール
実験管理ツールは、様々な入力値を元にしたモデル学習の実験結果をバージョン管理することにより
実験の再現性の担保を実現します。
モデルはハイパーパラメータ、モデルコード、学習に使うデータが必要なため、
ある時点のモデル学習を再現するには別途専用のツールが必要になります。
- 21.
- 22.
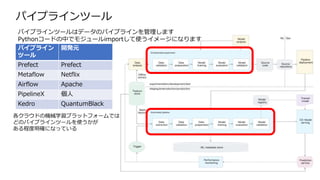
パイプラインツール 説明
Prefect Luigiの後継的な立ち位置としてリリース。並列実行、GUIに強みを持つ。
MetaflowAWS専用として開発されていた側面があり、他クラウドではあまり使えません。
Airflow GUIでの実行状況の可視化や特定タスクからのリトライが可能。
注意点として構造化データの同士のやりとりで使われるため、学習モデル、画像、
動画など非構造化データのやりとりができません。高機能ではあるがモデル学習
や学習評価周りのパイプラインでの使用はできません。
PipelineX KedroとMLflowを内包されている。
Kedro パイプラインの途中から実行ができませんが、様々な形式のファイルに対応して
おり、比較的多機能のように思える。
パイプラインツールの比較
パイプラインツールはもともと一部機械学習分野以外で使われていたため、
全てのツールが学習パイプラインの中で使えるわけではありません
- 23.
- 24.
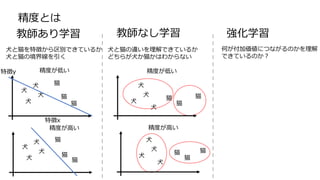
機械学習で具体的に何をしたいのか?
教師あり学習
教師なし学習
強化学習
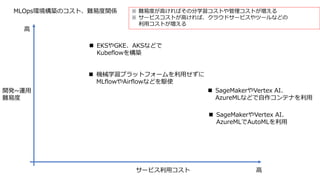
MLOpsの構築目的は?
学習頻度が低頻度のサービスや実験的なプロジェクトの場合は構築レベル0程度で検討する
本格的なサービス展開を検討している場合でも最初は構築レベルを抑えるか(0 or 1)検討する
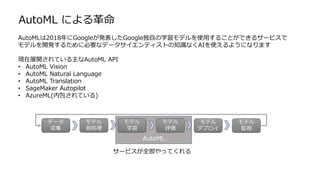
AutoMLで学習可能か?
可能であればモデル開発のコストが削減できる可能性がある
AutoMLサービス精度が一番高いクラウドはどれか?
各クラウドの検証結果(terrafromで検証自動化)
PJ内または社内でナレッジが豊富なクラウドは何か?
既に豊富なナレッジを持つクラウドを選択する
コストが一番安いクラウドは何か
サービス料金
管理コスト(必要な管理の範囲)
マネージドなコンテナサービスの選定など
その他コンポーネントサービスの優位性はないか?
MLOpsを始める前に確認しておきたいこと
- 25.
- 26.
- 27.
- 28.
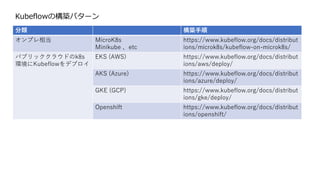
Kubeflowの構築パターン
分類 構築手順
オンプレ相当 MicroK8s
Minikube、etc
https://www.kubeflow.org/docs/distribut
ions/microk8s/kubeflow-on-microk8s/
パブリッククラウドのk8s
環境にKubeflowをデプロイ
EKS (AWS) https://www.kubeflow.org/docs/distribut
ions/aws/deploy/
AKS (Azure) https://www.kubeflow.org/docs/distribut
ions/azure/deploy/
GKE (GCP) https://www.kubeflow.org/docs/distribut
ions/gke/deploy/
Openshift https://www.kubeflow.org/docs/distribut
ions/openshift/
- 29.
- 30.
- 31.
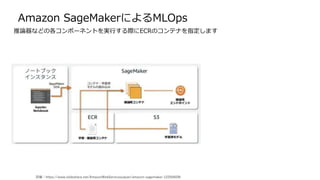
Amazon SageMaker とは
SageMakerPipelines は SageMaker Python SDKを使用して、json形式のパイプラインを定義します
機械学習関連のコンポーネントはクラウドの中でも一番多い印象
1.データ収集・準備
コンポーネント名 簡易説明
SageMaker Ground Truth 学習データへのラベル付け
SageMaker Data Wrangler 機械学習用のデータの集約及び準備
SageMaker Processing 組み込み Python
SageMaker Feature Store 特徴の保存、更新、取得及び共有
SageMaker Clarify バイアスの検出とモデルの予測と理解
コンポーネント名 簡易説明
SageMaker Studio Notebooks PJ内で共有可能なJupyter Notebook
組み込み及びごくじアルゴリズム 機械学習用のデータの集約及び準備
ローカルモード ローカルマシンでテストとプロトタイプ作成
SageMaker Autopilot 機械学習モデルを自動的に作成する
SageMaker JumpStart あらかじめ構築されたソリューション
2.ビルド
3.トレーニング・チューニング
コンポーネント名 簡易説明
ワンクリックトレーニング 分散インフラストラクチャの管理
SageMaker Experiments 全てのステップをキャプチャ
自動モデルチューニング ハイパーパラメータの最適化
分散トレニングライブラリ 大規模なトレーニング用
SageMaker Debugger バイアスの検出とモデルの予測と理解
マネージドスポットトレーニ
ング
トレーニング費用を90%削減
コンポーネント名 簡易説明
ワンクリックデプロイ フルマネージド型、超低レイテンシー、高スルー
プット
K8sと Kubeflow の統合 k8sベースの機械学習を簡素化
マルチモデルエンドポイント インスタンスごとに複数のモデルをホストすること
で費用を削減
SageMaker Model Monitor デプロイされたモデルの精度の維持
SageMaker Edge Manager エッジデバイスでのモデルの管理及びモニタリング
SageMaker Pipelines ワークフローのオーケストレーションと自動化
(kubeflow pipelines)
4.デプロイ & 管理
- 32.
- 33.
Amazon SageMaker でのPipeline について
SageMaker では SageMaker Studio というIDEを使用してパイプラインの作成や実行、
Notebookの使用、git管理などをしていきます
from sagemaker.workflow.pipeline import Pipeline
# 1000AI-Pipeline パイプラインの作成
pipeline_name = f"1000AI-Pipeline"
pipeline = Pipeline(
name=pipeline_name,
parameters=[
processing_instance_type,
processing_instance_count,
training_instance_type,
model_approval_status,
input_data,
batch_data,
],
steps=[step_process, step_train, step_eval,
step_cond],
)
SageMaker SDK:
scikit-learnライクをラップしたIF
kubeflow pipeline準拠のPythonコードで
パイプラインを定義する
- 34.
- 35.
- 36.
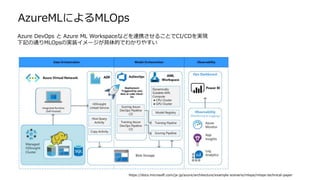
AzureMLによるMLOps
Azure DevOps とAzure ML Workspaceなどを連携させることでCI/CDを実現
下記の通りMLOpsの実装イメージが具体的でわかりやすい
https://docs.microsoft.com/ja-jp/azure/architecture/example-scenario/mlops/mlops-technical-paper
- 37.
AzureML での Pipelineについて
AzureMLでは 以下AzureML スタジオを使用して機械学習の管理を行います
AzureMLではデザイナと呼ばれる機能で、ドラッグ&ドロップでのパイプラインとモデル開発が可能
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
AzureML SDK:
scikit-learnライクをラップしたIF
kubeflow pipeline準拠のPythonコードで
パイプラインを定義する
- 38.
- 39.
- 40.
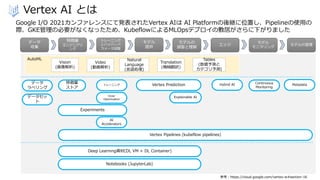
Vertex AI とは
参考:https://cloud.google.com/vertex-ai#section-16
GoogleI/O 2021カンファレンスにて発表されたVertex AIは AI Platformの後継に位置し、Pipelineの使用の
際、GKE管理の必要がなくなったため、KubeflowによるMLOpsデプロイの敷居がさらに下がりました
データ
収集
特徴量
エンジニアリ
ング
トレーニング
とハイパーパ
ラメータ調整
モデル
提供
モデルの
調整と理解
エッジ
モデル
モニタリング
モデルの管理
AutoML
Vision
(画像解析)
Video
(動画解析)
Natural
Language
(言語処理)
Translation
(機械翻訳)
Tables
(数値予測と
カテゴリ予測)
特徴量
ストア
トレーニング
Vizier
Optimization
Experiments
AI
Accelerators
Vertex Pipelines (kubeflow pipelines)
Deep Learning資材(DL VM + DL Container)
Notebooks (JupyterLab)
データ
ラベリング
データセッ
ト
Vertex Prediction
Explainable AI
Hybrid AI Continuous
Monitoring
Metadata
- 41.
- 42.
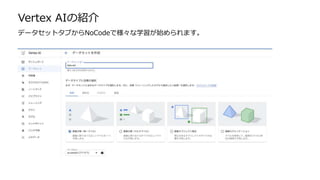
Vertex PipelinesによるMLOps
Vertex Piplinesはkubeflow SDK v2で作成したjsonを使用します(manufest.yaml相当)
Pipeline では 各コンポーネントを実行する際にGCRのコンテナを指定します
必要に応じてコンテナを立ち上げます
■Pipeline
■GCR
import kfp
from google.cloud import aiplatform
from google_cloud_pipeline_components import aiplatform as gcc_aip
from kfp.v2 import compiler
from kfp.v2.google.client import AIPlatformClient
@kfp.dsl.pipeline(
name=PIPELINE_NAME,
pipeline_root=f"gs://{GCP_GCS_PIPELINE_ROOT}/",
)
def kfp_sample_pipeline(suffix: str = "_xf"):
data_generator = _data_generator_op()
transform = _transform_op(
train_data_path=data_generator.outputs[GeneratedData.TrainData.value],
eval_data_path=data_generator.outputs[GeneratedData.EvalData.value],
suffix=suffix,
)
trainer = _trainer_op(
transformed_train_data_path=transform.outputs[
GeneratedData.TransformedTrainData.value
],
suffix=suffix,
)
_ = _evaluator_op(
trained_model_path=trainer.outputs[GeneratedData.TrainedModel.value],
transformed_eval_data_path=transform.outputs[GeneratedData.TransformedEvalData.value],
suffix=suffix,
)
# Compile the pipeline with V2 SDK to test the compatibility between V1 and V2 SDK
compiler.Compiler().compile(
pipeline_func=kfp_sample_pipeline,
package_path="kfp_sample_pipeline.json",
)
■コード一部抜粋
詳細や具体的な手順は後日ブログにて共有します
- 43.
- 44.
- 45.

















![Amazon SageMaker での Pipeline について
SageMaker では SageMaker Studio というIDEを使用してパイプラインの作成や実行、
Notebookの使用、git管理などをしていきます
from sagemaker.workflow.pipeline import Pipeline
# 1000AI-Pipeline パイプラインの作成
pipeline_name = f"1000AI-Pipeline"
pipeline = Pipeline(
name=pipeline_name,
parameters=[
processing_instance_type,
processing_instance_count,
training_instance_type,
model_approval_status,
input_data,
batch_data,
],
steps=[step_process, step_train, step_eval,
step_cond],
)
SageMaker SDK:
scikit-learnライクをラップしたIF
kubeflow pipeline準拠のPythonコードで
パイプラインを定義する](https://image.slidesharecdn.com/mlops-210904052026/85/MLOps-33-320.jpg)


![AzureML での Pipeline について
AzureMLでは 以下AzureML スタジオを使用して機械学習の管理を行います
AzureMLではデザイナと呼ばれる機能で、ドラッグ&ドロップでのパイプラインとモデル開発が可能
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
AzureML SDK:
scikit-learnライクをラップしたIF
kubeflow pipeline準拠のPythonコードで
パイプラインを定義する](https://image.slidesharecdn.com/mlops-210904052026/85/MLOps-37-320.jpg)


![Vertex PipelinesによるMLOps
Vertex Piplines はkubeflow SDK v2で作成したjsonを使用します(manufest.yaml相当)
Pipeline では 各コンポーネントを実行する際にGCRのコンテナを指定します
必要に応じてコンテナを立ち上げます
■Pipeline
■GCR
import kfp
from google.cloud import aiplatform
from google_cloud_pipeline_components import aiplatform as gcc_aip
from kfp.v2 import compiler
from kfp.v2.google.client import AIPlatformClient
@kfp.dsl.pipeline(
name=PIPELINE_NAME,
pipeline_root=f"gs://{GCP_GCS_PIPELINE_ROOT}/",
)
def kfp_sample_pipeline(suffix: str = "_xf"):
data_generator = _data_generator_op()
transform = _transform_op(
train_data_path=data_generator.outputs[GeneratedData.TrainData.value],
eval_data_path=data_generator.outputs[GeneratedData.EvalData.value],
suffix=suffix,
)
trainer = _trainer_op(
transformed_train_data_path=transform.outputs[
GeneratedData.TransformedTrainData.value
],
suffix=suffix,
)
_ = _evaluator_op(
trained_model_path=trainer.outputs[GeneratedData.TrainedModel.value],
transformed_eval_data_path=transform.outputs[GeneratedData.TransformedEvalData.value],
suffix=suffix,
)
# Compile the pipeline with V2 SDK to test the compatibility between V1 and V2 SDK
compiler.Compiler().compile(
pipeline_func=kfp_sample_pipeline,
package_path="kfp_sample_pipeline.json",
)
■コード一部抜粋
詳細や具体的な手順は後日ブログにて共有します](https://image.slidesharecdn.com/mlops-210904052026/85/MLOps-42-320.jpg)