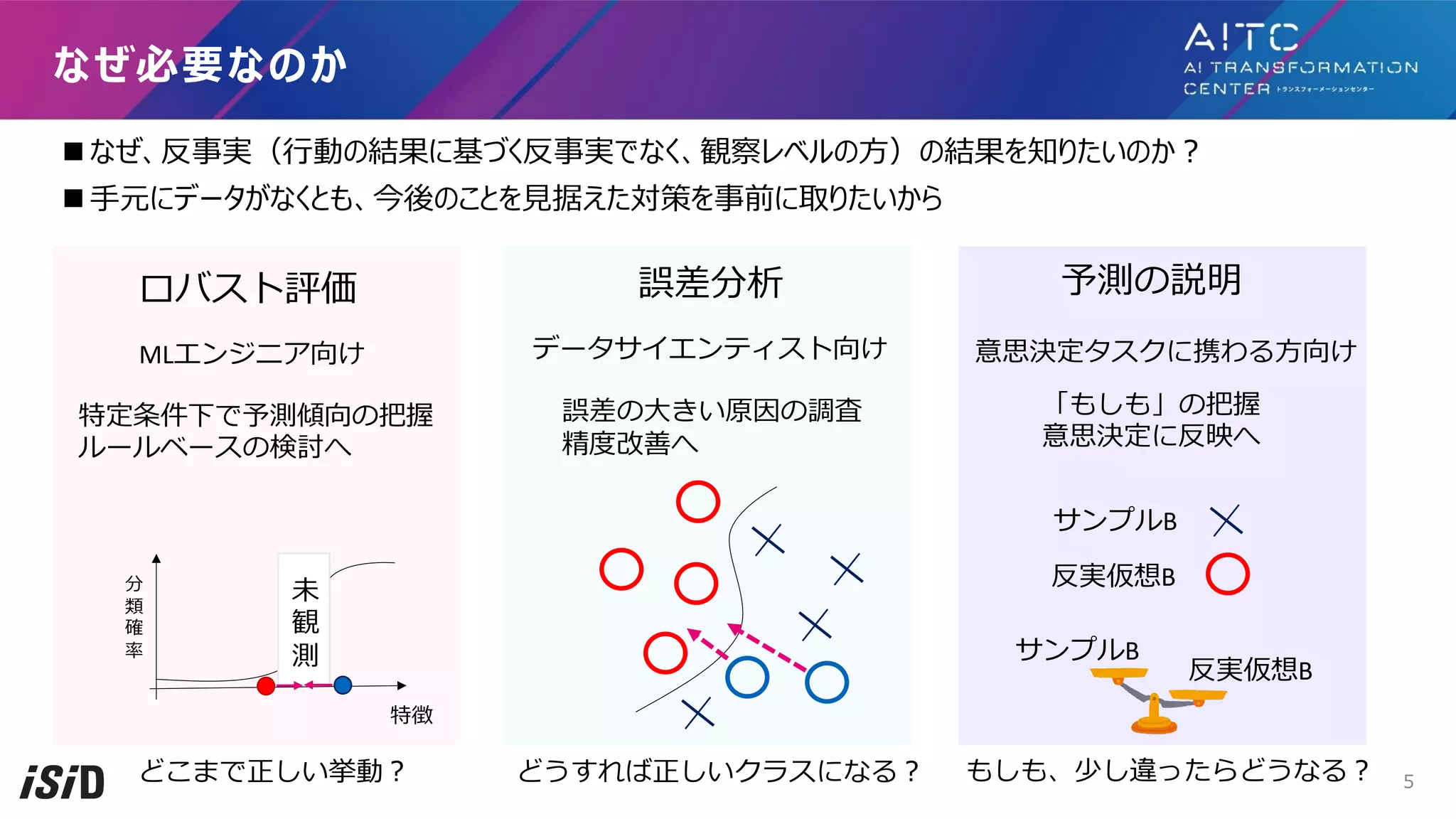
⾃⼰紹介
n 太⽥ 真⼈
nISIDでデータサイエンティストをしています。
n お仕事は、AI製品開発、データ分析案件、研究など
n 最近は、⼈とAIの協調など、HCIに興味があります。
n この資料は、予測の反実仮想説明のサーベイです。
n 基礎的な内容とテーブル、画像、テキストに対する反実仮想説明を紹介しています。
n サーベイ論⽂をまとめたわけではなく、⾃分で検索して調べたため、⾼い網羅性があるとは⾔えません。
n 各スライドの末尾に引⽤論⽂名と国際会議名を載せました。
はじめに
n対照的説明(Contrastive explanation )
ØwhyP, rather than Q? 「なぜQではなくPなのだろう。」を説明することを⽬指す。
Ø会計⼠でなく、なぜ⻭医者かと、⾔われると(2)の⻩⾊の所属機関が理由
Ø結果、ある事象が他の事象と対照的になぜ起こったのかが明らかになる。
n半事実説明(Semi-Factual Explanation)
ØEven if 「たとえ、何かをしても結果は変わらないだろう。」を出⼒することを⽬指す。
Ø半事実説明は、分類結果を変えないギリギリのサンプルを提⽰する。
関連する⽤語
反実仮想
事実
半事実
[EMNLP21] Contrastive Explanations for Model Interpretability
[AAAI21] On Generating Plausible Counterfactual and Semi-Factual Explanations for Deep Learning 19
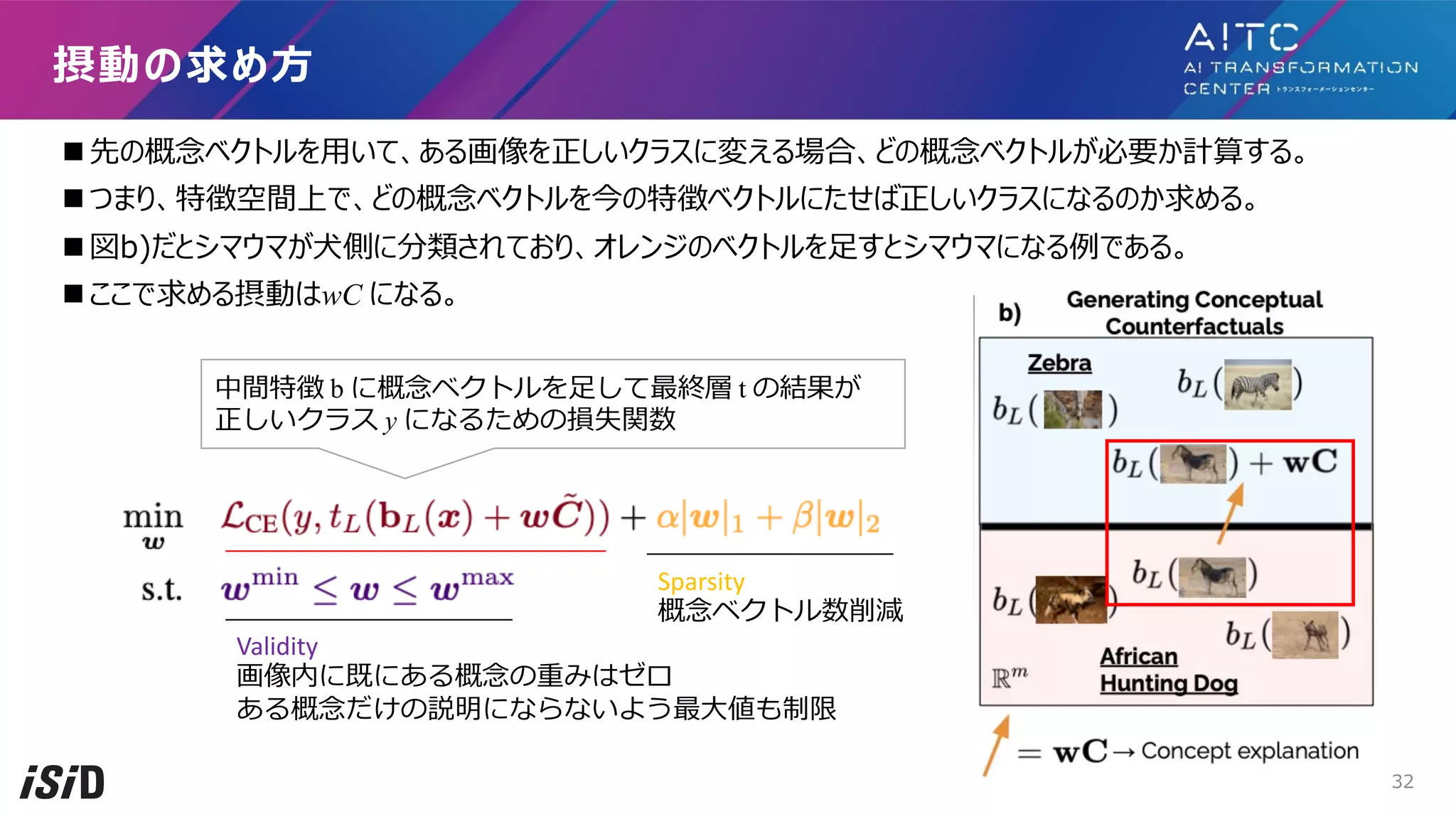
n 先のように、画像上ではどうしても摂動がノイズになり、説明にならない。
n そこで摂動対象を概念活性化ベクトル[Kim 18] に変えたConceptual Counterfactual Explanations(CCE)を提案
n 説明⽅法は図c)のように、間違えた予測を正しい予測に変えるために必要な概念ベクトルが緑で⽰される。
n 図c)はシマウマなのにストライプがないために別クラスになっているとわかる。
概念レベルの反実仮想例に向けて
[ICML 22] Meaningfully Debugging Model Mistakes using Conceptual Counterfactual Explanations 30
31.
n 概念活性化ベクトル Conceptactivation vectors (CAVs) [Kim 18]の算出⽅法を説明する。
1. まず概念は⼈が定義する。 定義をするのは、ドメインエキスパートが望ましい。
2. 次に各概念に対する正例と負例を訓練データから100件程度選ぶ。
3. 選択データを分類器の中間層の特徴量でSVM分類器を学習し、分類境界の法線ベクトルを概念ベクトルとする。
n 図だとストライプの概念をベクトルを計算している。
n こうして、各概念ベクトルを計算し、説明時に利⽤する。
⾃然画像の場合は以下の⼀般概念170個を定義していた。
(a) 特定の物体の存在(例︓鏡、⼈物)
(b) 状況(例︓道路、雪)
(c) 質感(例︓ストライプ、⾦属)
(d) 画像の質(例︓ぼやけ、緑)
概念活性化ベクトルの算出⽅法
31
n テーブルや画像のような最適化による反実仮想説明を求めない。
n ⼈間が、⼿動でテキストを書き換えたり、摂動関数を定義し、反実仮想サンプルを作成する。
n反実仮想サンプルを推論し、結果から反実仮想説明を求める。
n 紹介するPolyjuiceは⽣成モデルGPT-2を頼り、反実仮想サンプルの作成を効率化する。
n ⼿動でテキストを書き換え
Ø[ACL 20] Beyond accuracy: Behavioral testing of NLP models with CheckList.
Ø[ICLR 20] Learning the difference that makes A difference with counterfactually-augmented data.
n 摂動関数を定義
Ø[ACL 20] Semantically equivalent adversarial rules for debugging NLP models
n 制御可能な⽣成モデルの利⽤
Ø[ACL 21] Polyjuice: Generating Counterfactuals for Explaining, Evaluating, and Improving Models
テキストの反実仮想説明の現状
35
36.
n NLPの反実仮想サンプルは⼈かAIが⽣成している。
n 期待するクラスに予測を変えるにはどうすれば良いのか。
nNLPでは、yʻに対するxʼを求める逆問題が、⽣成x1,…,xn を推論し、yʼになるサンプルを探す問題に変わって
いる。
n ⽣成の条件づけが、⼈が解釈するのに直感的なものかがポイントになる。
テキストの反実仮想は説明性として機能しているのか
Why x’ ? Because
f
⼈が条件を数ある中から決める
⼈かAIにより⽣成
f
,
は対応する を反実仮想説明とする。
Why x’ ? Because
の中に があれば、
従来の⽅法 テキストの場合
36
37.
n 下図は、意味的に違和感のない敵対的⽂章を変換ルールで作成する。
Ø 単語の⾔い換え
nこの⽅法は複数のルールから共通する要因を⼈が調べ、予測モデルの傾向に気づかせる。
n 単語を省略形にすると間違う⽐率が⾼いから、このモデルは省略形に弱いと⼈に想起させる。
既存⼿法︓意味的に同じな敵対的⽂章による説明
[ACL20] Semantically equivalent adversarial rules for debugging NLP models
変換ルール
G(z)
z
37
既存⼿法︓意図に沿って⼈が反実仮想サンプルを作成
[ACL20] Beyond accuracy:Behavioral testing of NLP models with CheckList.
n ロバスト性を確認するために要件ごとにテキストを⼈が編集し、テス
ト形式で調査しています。
A 単体テスト
Ø 正常動作を確認
B 不変性テスト((Invariance test )
Ø 現実的にラベルが変わらない範囲でワードを変えて予測が不変か確
認
C ラベル変化テスト (A Directional Expectation test)
Ø 元⽂と類似するがラベルが変化する⽂章で正しく予測ラベルが変化
するか確認
G(z)
z
39
n 元⽂章の[BLANK]部分に対して、否定的な⽂章を⽣成してみた。
1. #the base sentence
2. text = "It's sunny today, so we'll play outside."
3. b_text = "It's sunny today, so we [BLANK] outside.”
4. pj = Polyjuice(model_path="uw-hai/polyjuice", is_cuda=True)
5. perturbations = pj.perturb(
6. orig_sent=text, #オリジナル⽂章
7. blanked_sent=b_text, #ブランク付き⽂章
8. ctrl_code=“negation”, #制御ルール
9. perplex_thred=5, #⽣成⽂章の質の閾値
10. num_perturbations=3, #⽣成⽂の返り値の最⼤数
11. )
12.print(perturbations)
[Out]: ["It's sunny today, so we don't need to play outside.", "It's sunny today, so we don't have to go outside."]
やってみた
41
42.
n 制御ルールを与えずに⽣成させることも可能。
Text =“週末に台⾵が来るから、どこにも出かけられない。”
Atyphoon is coming this weekend, so I can't go out anywhere.
⽣成結果
n "今週末は台⾵が来るから、海に⾏けないよ”
n "今週末は台⾵が来るから、どこにも出かけられないよ”
n "今週末は台⾵が来るから、仕事に⾏けないよ"
n "I have a typhoon this weekend, so I can't go to the beach.”
n "The typhoon is coming this weekend, so I can't go out anywhere.”
n "I have a typhoon this weekend, so I can't go to work."
別の⽣成例
42
n 反実仮想説明の概要と求められることを紹介しました。
n テーブル、画像、テキストに対して、簡単な実装例と最新論⽂の紹介をしました。
n画像は、概念レベル(背景雪、⽬の⾊、⽿の形)で反事実を得ようとしてます。
n テキストは、条件をもとに⽂章を多数⽣成し、テストケースで反事実を得ようとしています。
n 画像とテキストに共通して、⼈間のドメイン知識を解釈⼿法に組み込もうとしています。
Ø 画像の場合、概念をベクトル化する際に、概念の選別は⼈が決めます。
Ø テキストの場合、⽣成させる条件を⼈が決めます。
n 業務知識のある⼈たちが⾃分の意思決定する要因を洗い出し、それらを解釈⼿法に組み込むことで信頼のある
AIに近づくと考えます。
まとめ
46






![n[Wachter+ 17] が発表した多くの論⽂の根幹の考え⽅
nx︓オリジナルサンプル, y︓オリジナルラベル
nxʼ︓x の反実仮想(CF)サンプル, yʼ︓期待するラベル
反実仮想サンプルを求める最適化の考え⽅
⼊⼒空間は離れず
予測は期待ラベル
に近づける
[Arxiv 20] Counterfactual Explanations for Machine Learning: A Review 8](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-8-2048.jpg)


![n テーブルデータでは、変更可能な特徴と不可能な特徴がある。
n 推薦の場合、どの特徴が変更可能で(例えば、収⼊、年齢)、どの特徴が変更不可能か(例えば、⼈種、出
⾝国)についての考察が重要。
n 推奨される反実仮想は、決して不変の特徴を変更してはならない。
n ⾏動可能な特徴の集合をA と呼び、損失関数を次のように更新することができる。
⾏動可能性 Actionability( Rationality )
⾏動範囲を制限
[IUI 20] ViCE: Visual Counterfactual Explanations for Machine Learning Models 11](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-11-2048.jpg)
![n 変更する特徴の数と、摂動の⼤きさには、トレードオフが存在する。
n 反実仮想は、理想的には、より少ない数の特徴を変更する必要がある。
スパース性(Sparsity)
[FAT20] Explaining Machine Learning Classifiers through Diverse Counterfactual Explanations
オリジナル
L0/L1 ノルム
12](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-12-2048.jpg)


![n テーブルデータは最適化アルゴリズムから反実仮想を求めることが多い。
n 画像やテキストの⾮構造データは⽣成モデルを⽤いることが多い。
反実仮想アルゴリズム
画像・テキスト系
テーブル系
Azure ML提供
Polyjuice
後で紹介
G
P
T
2
元図 [Arxiv 21] MCCE: Monte Carlo sampling of realistic counterfactual explanations 15](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-15-2048.jpg)

![反実仮想例と類似する概念の説明
説明
1と予測したのは右の訓練
画像があったから。
説明
たとえ、右の⽣成画像のよ
うでも9と予測します。
(⽣成画像の⽅がより分類
境界に近い)
説明
もし、画像が真ん中や右の⽣成画像の
ようになれば8と予測します。
⼀般的なテーブルデータではなく、画像を例にfactualとsemi-factualとcounterfactualを紹介
左の画像に対して、その説明を右の画像がそれぞれしている。
[AAAI 21] On Generating Plausible Counterfactual and Semi-Factual Explanations for Deep Learning 17](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-17-2048.jpg)
![n敵対的学習(Adversarial Learning )
Ø敵対的学習は、与えられた⼊⼒を異なる分類にするために、⼊⼒に最⼩限の変化を与えることを⽬的とし
ている。
Ø敵対的学習の設定には⼈間に気付かないノイズレベルを⼊⼒に与えることが多い。
Ø⼀⽅で、反実仮想説明では、⼈間が検出可能で、理解可能で、もっともらしいものでなければならない。
関連する⽤語
オリジナル CF
オリジナル AE
[arXiv 13] Intriguing properties of neural networks
[ACL18] Semantically Equivalent Adversarial Rules for Debugging NLP Models
敵対的サンプル 反実仮想サンプル
18](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-18-2048.jpg)
![n対照的説明(Contrastive explanation )
Øwhy P, rather than Q? 「なぜQではなくPなのだろう。」を説明することを⽬指す。
Ø会計⼠でなく、なぜ⻭医者かと、⾔われると(2)の⻩⾊の所属機関が理由
Ø結果、ある事象が他の事象と対照的になぜ起こったのかが明らかになる。
n半事実説明(Semi-Factual Explanation)
ØEven if 「たとえ、何かをしても結果は変わらないだろう。」を出⼒することを⽬指す。
Ø半事実説明は、分類結果を変えないギリギリのサンプルを提⽰する。
関連する⽤語
反実仮想
事実
半事実
[EMNLP21] Contrastive Explanations for Model Interpretability
[AAAI21] On Generating Plausible Counterfactual and Semi-Factual Explanations for Deep Learning 19](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-19-2048.jpg)

![nAzureMLでは、テーブルデータに対して、DiCEが実装されている。
nDiCE( Diverse Counterfactual Explanations)
Ø複数の反事実を求める
Øモデルに依存しない計算⽅法(Azure対応)
• ランダムサンプリング
• KD-Tree (トレーニング データ内の反事実)
• 遺伝的アルゴリズム
Øモデルに依存する計算⽅法
• 勾配ベースな⽅法
AzureMLの反実仮想説明
https://learn.microsoft.com/ja-jp/azure/machine-learning/concept-counterfactual-analysis
[FAT20] Explaining Machine Learning Classifiers through Diverse Counterfactual Explanations
21](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-21-2048.jpg)



![特徴の可能な範囲を狭める
n 先の例に、年齢の範囲を[20,60]とする。
n 結果、四捨五⼊した61歳までの範囲の結果が求められる。
n この場合、年齢が60歳になるまでに教育を受け、職業を変えると超えられるらしい。
年収が$50Kを超えるには︖
25](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-25-2048.jpg)




![n 先のように、画像上ではどうしても摂動がノイズになり、説明にならない。
n そこで摂動対象を概念活性化ベクトル [Kim 18] に変えたConceptual Counterfactual Explanations(CCE)を提案
n 説明⽅法は図c)のように、間違えた予測を正しい予測に変えるために必要な概念ベクトルが緑で⽰される。
n 図c)はシマウマなのにストライプがないために別クラスになっているとわかる。
概念レベルの反実仮想例に向けて
[ICML 22] Meaningfully Debugging Model Mistakes using Conceptual Counterfactual Explanations 30](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-30-2048.jpg)
![n 概念活性化ベクトル Concept activation vectors (CAVs) [Kim 18]の算出⽅法を説明する。
1. まず概念は⼈が定義する。 定義をするのは、ドメインエキスパートが望ましい。
2. 次に各概念に対する正例と負例を訓練データから100件程度選ぶ。
3. 選択データを分類器の中間層の特徴量でSVM分類器を学習し、分類境界の法線ベクトルを概念ベクトルとする。
n 図だとストライプの概念をベクトルを計算している。
n こうして、各概念ベクトルを計算し、説明時に利⽤する。
⾃然画像の場合は以下の⼀般概念170個を定義していた。
(a) 特定の物体の存在(例︓鏡、⼈物)
(b) 状況(例︓道路、雪)
(c) 質感(例︓ストライプ、⾦属)
(d) 画像の質(例︓ぼやけ、緑)
概念活性化ベクトルの算出⽅法
31](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-31-2048.jpg)


![n テーブルや画像のような最適化による反実仮想説明を求めない。
n ⼈間が、⼿動でテキストを書き換えたり、摂動関数を定義し、反実仮想サンプルを作成する。
n 反実仮想サンプルを推論し、結果から反実仮想説明を求める。
n 紹介するPolyjuiceは⽣成モデルGPT-2を頼り、反実仮想サンプルの作成を効率化する。
n ⼿動でテキストを書き換え
Ø[ACL 20] Beyond accuracy: Behavioral testing of NLP models with CheckList.
Ø[ICLR 20] Learning the difference that makes A difference with counterfactually-augmented data.
n 摂動関数を定義
Ø[ACL 20] Semantically equivalent adversarial rules for debugging NLP models
n 制御可能な⽣成モデルの利⽤
Ø[ACL 21] Polyjuice: Generating Counterfactuals for Explaining, Evaluating, and Improving Models
テキストの反実仮想説明の現状
35](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-35-2048.jpg)

![n 下図は、意味的に違和感のない敵対的⽂章を変換ルールで作成する。
Ø 単語の⾔い換え
n この⽅法は複数のルールから共通する要因を⼈が調べ、予測モデルの傾向に気づかせる。
n 単語を省略形にすると間違う⽐率が⾼いから、このモデルは省略形に弱いと⼈に想起させる。
既存⼿法︓意味的に同じな敵対的⽂章による説明
[ACL20] Semantically equivalent adversarial rules for debugging NLP models
変換ルール
G(z)
z
37](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-37-2048.jpg)
![アノテーターに⽂章を修正するよう指⽰しデータ拡張
変更の条件
(a)反実仮想ラベルが適⽤されること
(b)⽂書の⼀貫性を保つこと
(c)不必要な修正をしないこと
n アノテーションの結果
Ø 8つの共通パターンを発⾒(右表)
既存⼿法︓アノテーターに反実仮想サンプルの作成
[ICLR20] Learning the difference that makes A difference with counterfactually-augmented data.
[arXiv 20] Evaluating models’ local decision boundaries via contrast sets.
期待される事実の⾔い換え
⽪⾁の追加
修飾語の挿⼊
修飾語の変換
フレーズの挿⼊
修飾語による感情の減衰
異なる視点
レーティングの変更
G(z)
z
38](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-38-2048.jpg)
![既存⼿法︓意図に沿って⼈が反実仮想サンプルを作成
[ACL20] Beyond accuracy: Behavioral testing of NLP models with CheckList.
n ロバスト性を確認するために要件ごとにテキストを⼈が編集し、テス
ト形式で調査しています。
A 単体テスト
Ø 正常動作を確認
B 不変性テスト((Invariance test )
Ø 現実的にラベルが変わらない範囲でワードを変えて予測が不変か確
認
C ラベル変化テスト (A Directional Expectation test)
Ø 元⽂と類似するがラベルが変化する⽂章で正しく予測ラベルが変化
するか確認
G(z)
z
39](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-39-2048.jpg)
![n 反実仮想サンプルをGPT-2によって⽣成できること
ü⽣成させたい反実仮想のルールを部分的に制御可能
ü反実仮想⽂章を⼈が作らなくて良い
ü質の⾼い⽂章を作れる
Polyjuiceの良いところ
Polyjuiceの全体構成
⽣成可能な条件リスト
z G(z)
[ACL 21] Polyjuice: Generating Counterfactuals for Explaining, Evaluating, and Improving Models 40](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-40-2048.jpg)
![n 元⽂章の[BLANK]部分に対して、否定的な⽂章を⽣成してみた。
1. # the base sentence
2. text = "It's sunny today, so we'll play outside."
3. b_text = "It's sunny today, so we [BLANK] outside.”
4. pj = Polyjuice(model_path="uw-hai/polyjuice", is_cuda=True)
5. perturbations = pj.perturb(
6. orig_sent=text, #オリジナル⽂章
7. blanked_sent=b_text, #ブランク付き⽂章
8. ctrl_code=“negation”, #制御ルール
9. perplex_thred=5, #⽣成⽂章の質の閾値
10. num_perturbations=3, #⽣成⽂の返り値の最⼤数
11. )
12.print(perturbations)
[Out]: ["It's sunny today, so we don't need to play outside.", "It's sunny today, so we don't have to go outside."]
やってみた
41](https://image.slidesharecdn.com/random-221021135048-38498e3c/75/slide-41-2048.jpg)















![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=640&height=640&fit=bounds)















![[論文紹介] 機械学習システムの安全性における未解決な問題](https://cdn.slidesharecdn.com/ss_thumbnails/random-211002234309-thumbnail.jpg?width=640&height=640&fit=bounds)








