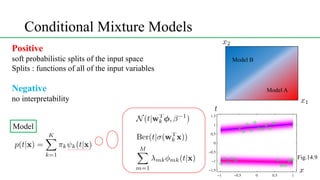
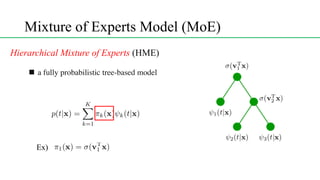
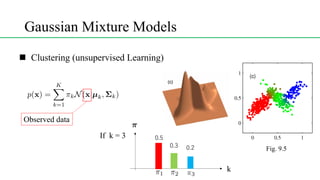
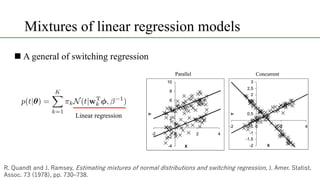
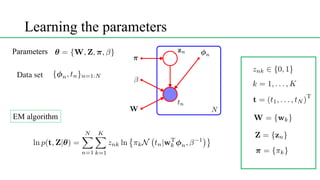
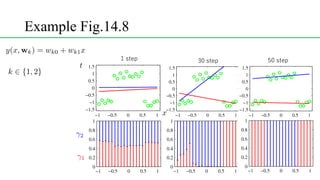
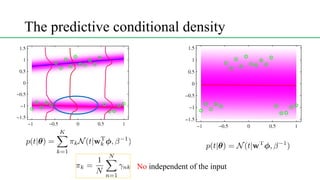
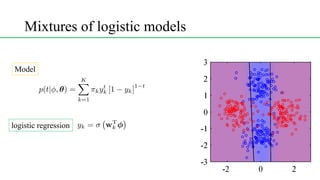
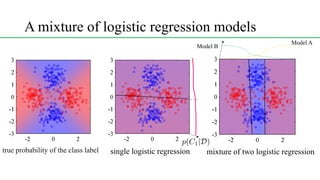
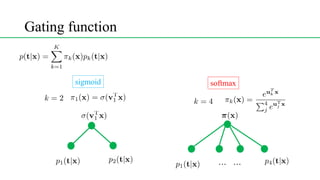
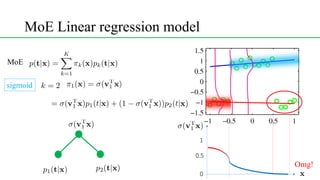
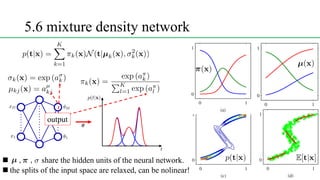
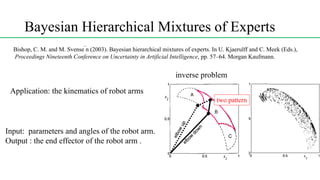
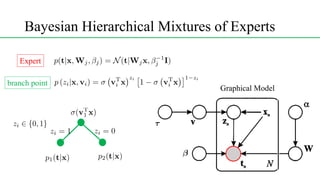
This document discusses conditional mixture models, including mixtures of linear regression models, mixtures of logistic models, and mixtures of experts models. It provides details on learning the parameters of these models using the EM algorithm. Mixtures of experts models use a gating network to determine which expert network is responsible for different regions of the input space. Hierarchical mixtures of experts extend this idea by incorporating multiple levels of gating networks.












































































![[論文紹介] 機械学習システムの安全性における未解決な問題](https://cdn.slidesharecdn.com/ss_thumbnails/random-211002234309-thumbnail.jpg?width=640&height=640&fit=bounds)






























