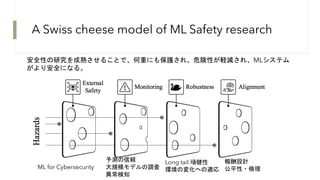
A Swiss cheesemodel of ML Safety research
安全性の研究を成熟させることで、何重にも保護され、危険性が軽減され、MLシステム
がより安全になる。
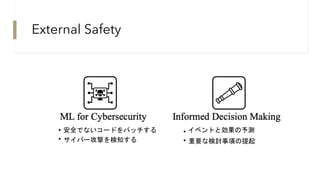
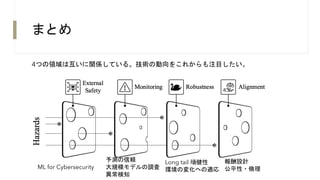
ML for Cybersecurity
予測の信頼
大規模モデルの調査
異常検知
Long tail 頑健性
環境の変化への適応
報酬設計
公平性・倫理
6.
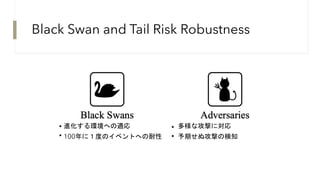
Black Swan andTail Risk Robustness
進化する環境への適応
100年に1度のイベントへの耐性
多様な攻撃に対応
予期せぬ攻撃の検知
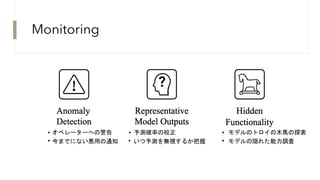
Representative Model Outputs
•監視者は、モデルが自身の理解や不足を正確に、正直に、忠実に表現した出力を出せ
ば、より効果的にモデルをモニタリングできる。
正直さ(honestly):学習データからわからないことに対して、予測確率を下げる。
NLPの文脈では嘘の文章を生成しない。
忠実さ(faithfully):違う入力でも意味的に同じ内容なら、同じ答えを返す(一貫性)
Language modelでの研究
• 大規模モデルの文章生成に一貫性を持たせる。
• モデルの予測が矛盾していることを検出する評価スキームを作成する。
Making Model Outputs Honest and Truthful






















![[DL輪読会]SoftTriple Loss: Deep Metric Learning Without Triplet Sampling (ICCV2019)](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190920dlhack-190920011134-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Parity Models: A General Framework for Coding-Based Resilience in ML I...](https://cdn.slidesharecdn.com/ss_thumbnails/20191115misono-191115035735-thumbnail.jpg?width=640&height=640&fit=bounds)
















