Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
SF
Uploaded by
Shintaro Fukushima
52,234 views
外れ値
Read more
34
Save
Share
Embed
Embed presentation
Download
Downloaded 144 times
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
「統計的学習理論」第1章
by
Kota Matsui
PDF
機械学習モデルのハイパパラメータ最適化
by
gree_tech
PPTX
変分ベイズ法の説明
by
Haruka Ozaki
KEY
アンサンブル学習
by
Hidekazu Tanaka
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PPTX
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
PDF
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
PDF
初めてのグラフカット
by
Tsubasa Hirakawa
「統計的学習理論」第1章
by
Kota Matsui
機械学習モデルのハイパパラメータ最適化
by
gree_tech
変分ベイズ法の説明
by
Haruka Ozaki
アンサンブル学習
by
Hidekazu Tanaka
機械学習モデルの判断根拠の説明
by
Satoshi Hara
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
自動微分変分ベイズ法の紹介
by
Taku Yoshioka
初めてのグラフカット
by
Tsubasa Hirakawa
What's hot
PDF
最適輸送の解き方
by
joisino
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PDF
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
PDF
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
PDF
負の二項分布について
by
Hiroshi Shimizu
PPTX
【解説】 一般逆行列
by
Kenjiro Sugimoto
PPTX
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
PDF
深層自己符号化器+混合ガウスモデルによる教師なし異常検知
by
Chihiro Kusunoki
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PPTX
[研究室論文紹介用スライド] Adversarial Contrastive Estimation
by
Makoto Takenaka
PDF
機械学習におけるオンライン確率的最適化の理論
by
Taiji Suzuki
PDF
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
PDF
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
PDF
パターン認識と機械学習入門
by
Momoko Hayamizu
PDF
正準相関分析
by
Akisato Kimura
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PDF
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
PDF
Word2vecの理論背景
by
Masato Nakai
PDF
PRML輪読#1
by
matsuolab
最適輸送の解き方
by
joisino
最適輸送の計算アルゴリズムの研究動向
by
ohken
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
coordinate descent 法について
by
京都大学大学院情報学研究科数理工学専攻
負の二項分布について
by
Hiroshi Shimizu
【解説】 一般逆行列
by
Kenjiro Sugimoto
ようやく分かった!最尤推定とベイズ推定
by
Akira Masuda
深層自己符号化器+混合ガウスモデルによる教師なし異常検知
by
Chihiro Kusunoki
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
[研究室論文紹介用スライド] Adversarial Contrastive Estimation
by
Makoto Takenaka
機械学習におけるオンライン確率的最適化の理論
by
Taiji Suzuki
異常検知と変化検知 第4章 近傍法による異常検知
by
Ken'ichi Matsui
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
パターン認識と機械学習入門
by
Momoko Hayamizu
正準相関分析
by
Akisato Kimura
階層モデルの分散パラメータの事前分布について
by
hoxo_m
階層ベイズとWAIC
by
Hiroshi Shimizu
グラフィカルモデル入門
by
Kawamoto_Kazuhiko
Word2vecの理論背景
by
Masato Nakai
PRML輪読#1
by
matsuolab
Similar to 外れ値
PDF
Rで学ぶロバスト推定
by
Shintaro Fukushima
PDF
行列計算を利用したデータ解析技術
by
Yoshihiro Mizoguchi
PDF
一般化線形混合モデル isseing333
by
Issei Kurahashi
PDF
Rで実験計画法 前編
by
itoyan110
PDF
Rで実験計画法 後編
by
itoyan110
PDF
反応時間データをどう分析し図示するか
by
SAKAUE, Tatsuya
PDF
パターン認識02 k平均法ver2.0
by
sleipnir002
PDF
R Study Tokyo03
by
Yohei Sato
PPTX
13.01.20. 第1回DARM勉強会資料#4
by
Yoshitake Takebayashi
KEY
第5章 統計的仮説検定 (Rによるやさしい統計学)
by
Prunus 1350
PPT
020 1変数の集計
by
t2tarumi
PDF
Excelを使った統計解析とグラフ化入門
by
Mizumoto Atsushi
PDF
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
PDF
LET2015 National Conference Seminar
by
Mizumoto Atsushi
PDF
20130223_集計・分析の基礎@アンケート研究会
by
Takanori Hiroe
PPT
K070k80 点推定 区間推定
by
t2tarumi
PDF
Let中部2012シンポスライド
by
Mizumoto Atsushi
PPT
K020 appstat201202
by
t2tarumi
PPTX
便利な数を100億個の乱数から算出
by
Toshiyuki Shimono
PDF
一攫
by
Yasukazu Kawasaki
Rで学ぶロバスト推定
by
Shintaro Fukushima
行列計算を利用したデータ解析技術
by
Yoshihiro Mizoguchi
一般化線形混合モデル isseing333
by
Issei Kurahashi
Rで実験計画法 前編
by
itoyan110
Rで実験計画法 後編
by
itoyan110
反応時間データをどう分析し図示するか
by
SAKAUE, Tatsuya
パターン認識02 k平均法ver2.0
by
sleipnir002
R Study Tokyo03
by
Yohei Sato
13.01.20. 第1回DARM勉強会資料#4
by
Yoshitake Takebayashi
第5章 統計的仮説検定 (Rによるやさしい統計学)
by
Prunus 1350
020 1変数の集計
by
t2tarumi
Excelを使った統計解析とグラフ化入門
by
Mizumoto Atsushi
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
LET2015 National Conference Seminar
by
Mizumoto Atsushi
20130223_集計・分析の基礎@アンケート研究会
by
Takanori Hiroe
K070k80 点推定 区間推定
by
t2tarumi
Let中部2012シンポスライド
by
Mizumoto Atsushi
K020 appstat201202
by
t2tarumi
便利な数を100億個の乱数から算出
by
Toshiyuki Shimono
一攫
by
Yasukazu Kawasaki
More from Shintaro Fukushima
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PDF
機械学習を用いた予測モデル構築・評価
by
Shintaro Fukushima
PDF
Rあんなときこんなとき(tokyo r#12)
by
Shintaro Fukushima
PDF
20230216_Python機械学習プログラミング.pdf
by
Shintaro Fukushima
PDF
機械学習品質管理・保証の動向と取り組み
by
Shintaro Fukushima
PDF
Juliaで並列計算
by
Shintaro Fukushima
PDF
Numpy scipyで独立成分分析
by
Shintaro Fukushima
PDF
最近のRのランダムフォレストパッケージ -ranger/Rborist-
by
Shintaro Fukushima
PDF
Rユーザのためのspark入門
by
Shintaro Fukushima
PDF
データサイエンスワールドからC++を眺めてみる
by
Shintaro Fukushima
PDF
data.tableパッケージで大規模データをサクッと処理する
by
Shintaro Fukushima
PDF
Materials Informatics and Python
by
Shintaro Fukushima
PDF
Juliaによる予測モデル構築・評価
by
Shintaro Fukushima
PDF
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用
by
Shintaro Fukushima
PDF
mmapパッケージを使ってお手軽オブジェクト管理
by
Shintaro Fukushima
PDF
Why dont you_create_new_spark_jl
by
Shintaro Fukushima
PDF
R3.0.0 is relased
by
Shintaro Fukushima
PDF
Rでreproducible research
by
Shintaro Fukushima
PDF
BPstudy sklearn 20180925
by
Shintaro Fukushima
PDF
アクションマイニングを用いた最適なアクションの導出
by
Shintaro Fukushima
不均衡データのクラス分類
by
Shintaro Fukushima
機械学習を用いた予測モデル構築・評価
by
Shintaro Fukushima
Rあんなときこんなとき(tokyo r#12)
by
Shintaro Fukushima
20230216_Python機械学習プログラミング.pdf
by
Shintaro Fukushima
機械学習品質管理・保証の動向と取り組み
by
Shintaro Fukushima
Juliaで並列計算
by
Shintaro Fukushima
Numpy scipyで独立成分分析
by
Shintaro Fukushima
最近のRのランダムフォレストパッケージ -ranger/Rborist-
by
Shintaro Fukushima
Rユーザのためのspark入門
by
Shintaro Fukushima
データサイエンスワールドからC++を眺めてみる
by
Shintaro Fukushima
data.tableパッケージで大規模データをサクッと処理する
by
Shintaro Fukushima
Materials Informatics and Python
by
Shintaro Fukushima
Juliaによる予測モデル構築・評価
by
Shintaro Fukushima
統計解析言語Rにおける大規模データ管理のためのboost.interprocessの活用
by
Shintaro Fukushima
mmapパッケージを使ってお手軽オブジェクト管理
by
Shintaro Fukushima
Why dont you_create_new_spark_jl
by
Shintaro Fukushima
R3.0.0 is relased
by
Shintaro Fukushima
Rでreproducible research
by
Shintaro Fukushima
BPstudy sklearn 20180925
by
Shintaro Fukushima
アクションマイニングを用いた最適なアクションの導出
by
Shintaro Fukushima
外れ値
1.
シリーズ前処理2013
外れ値 2013年2月23日 第29回Tokyo.R @sfchaos
2.
� これは,「シリーズ前処理」の発表の一つです. � 前回の@dichikaさんに続いて,今日は外れ値について
取り上げます. � この後も多くの皆さんが発表してくださることを期待し ています. シリーズ前処理 タイトル 発表者 1(第28回) 欠測への対応 @dichika 2(第29回) 外れ値 @sfchaos � � �
3.
アジェンダ 1.
自己紹介 2. データ分析のお仕事 3. 外れ値とその検出方法 4. まとめ
4.
1. 自己紹介
5.
� TwitterID: @sfchaos �
職業: データ分析
6.
2. データ分析のお仕事
7.
2.1 俺たちの日常
やりたかった分析 前処理 「欠測への対応」@dichika再掲, ただしグラフは劣化
8.
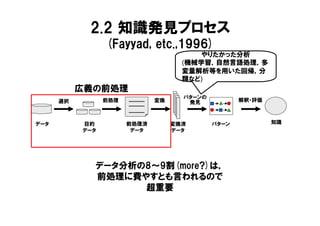
2.2 知識発見プロセス
(Fayyad, etc.,1996) やりたかった分析 (機械学習,自然言語処理,多 変量解析等を用いた回帰,分 類など) 広義の前処理 パターンの 選択 前処理 変換 発見 解釈・評価 データ 目的 前処理済 変換済 パターン 知識 データ データ データ データ分析の8~9割(more?)は, 前処理に費やすとも言われるので 超重要
9.
3. 外れ値とその検出方法
10.
3.1 外れ値とは � 外れ値とは,データセットの中で他から著しく乖離して
いるデータのこと.
11.
3.2 外れ値の例 � Kolaデータセット(ロシアの土壌の成分) >
library(mvoutlier) > data(moss) data(moss moss) > dim(moss) [1] 598 34 > moss[1:5, 1:10] ID XCOO YCOO Ag Al As B Ba Bi Ca 1 1 547960.4 7693790 0.016 71.2 0.123 1.74 14.0 0.002 2310 2 2 770024.8 7679167 0.073 245.0 0.299 2.77 17.4 0.039 2460 3 3 498650.6 7668151 0.032 103.0 0.176 1.89 20.9 0.012 3430 4 4 795151.9 7569386 0.118 307.0 0.423 2.30 21.8 0.033 2860 5 5 437050.0 7855900 0.038 253.0 0.119 4.65 31.1 0.002 3190 Anne Ruiz-Gaze and Christine Thomas-Agnan, Identification of local mutivariate outliers, http://bit.ly/XqDlfG
12.
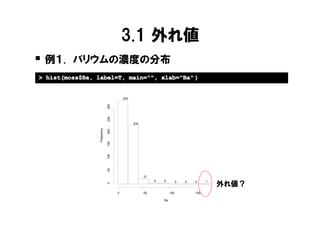
3.1 外れ値 � 例1. バリウムの濃度の分布 >
hist(moss$Ba, label=T, main="", xlab="Ba" ) 334 300 250 234 Frequency 200 150 100 50 21 4 4 0 0 0 1 外れ値? 0 0 50 100 150 Ba
13.
3.1 外れ値 � 例2.
バリウムとカルシウムの散布図(対数変換済み) > corr.plot(log(moss$Ba), log(moss$Ca), xlab="log(Ba)", ylab="log(Ca)") $cor.cla [1] 0.663193 $cor.rob [1] 0.7130014 Classical cor = 0.66 Robust cor = 0.71 9.0 8.5 log(Ca) 8.0 7.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 log(Ba)
14.
3.2 外れ値検出のアプローチ � 外れ値を検出するアプローチはいくつかある. �
各アプローチで,仮定や考え方が異なるので,分析デー タの特性に応じて選ぶべし. 仮定・考え方 代表的なアプローチ 統計的アプローチ データは統計的なモデルに � 統計的検定 (Statistical approaches) 従って発生すると考え,そ � 深さに基づくアプローチ のモデルに従わないデータ � 偏差に基づくアプローチ が外れ値 等 空間的な近さに基づく方法 他のデータと比べて近傍点 � 距離に基づくアプローチ (Proximity-based method) への近接度合いが著しく異 � 密度に基づくアプローチ なるデータが外れ値 クラスタリングに基づく方法 データをクラスタリングする (Clustering-based mathod) 際に,小さいクラスターに 所属するデータが外れ値
15.
3.2 外れ値検出のアプローチ � 外れ値を検出するアプローチはいくつかある. �
各アプローチで,仮定や考え方が異なるので,分析デー タの特性に応じて選ぶべし. 仮定・考え方 代表的なアプローチ 統計的アプローチ データは統計的なモデルに � 統計的検定 (Statistical approaches) 従って発生すると考え,そ � 深さに基づくアプローチ のモデルに従わないデータ � 偏差に基づくアプローチ が外れ値 等 空間的な近さに基づく方法 他のデータと比べて近傍点 � 距離に基づくアプローチ (Proximity-based method) への近接度合いが著しく異 � 密度に基づくアプローチ なるデータが外れ値 クラスタリングに基づく方法 データをクラスタリングする (Clustering-based mathod) 際に,小さいクラスターに 所属するデータが外れ値
16.
3.3 統計的アプローチ � 統計的検定,深さに基づくアプローチ,偏差に基づくア
プローチなどがある.
17.
3.3.1 統計的検定 � 箱ひげ図,Grubbs検定などがある.
18.
3.3.1 (1)箱ひげ図
334 300 250 234 Frequency 200 150 100 > res <- boxplot(moss$Ba) 50 21 > res$stats 4 4 0 0 0 1 0 [,1] 0 50 100 150 Ba [1,] 6.71 [2,] 15.20 150 [3,] 19.00 [4,] 23.90 100 [5,] 36.70 50 0
19.
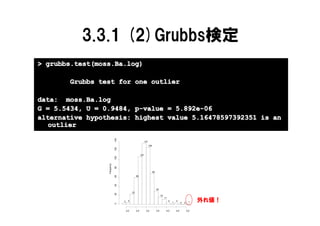
3.3.1 (2)Grubbs検定 � 1次元のデータが全て正規分布から発生したと仮定. �
一番大きな値(or小さい値,または両方)のzスコアが閾 値以上かどうかにより,帰無仮説の棄却判定を行う. � この検定の結果により,一番大きい(or小さい)値を持 つデータが外れ値かどうかを判定する. 帰無仮説 全データが同じ分布(正 x−x z= 規分布)から生成される σ 対立仮説 一番大きい(or小さい) x 2 値のデータは他のデータ N −1 tα / 2 N , N − 2 とは異なる分布から生成 z≥ 2 される N N − 2 + tα / 2 N , N − 2
20.
3.3.1 (2)Grubbs検定 � バリウムのデータは正規分布に従っていないので,対数
変換を行って正規分布に近づける. > library(e1071) > moss.Ba.log <- log(moss$Ba) > kurtosis(moss.Ba.log) [1] 2.690639 > hist(log(moss$Ba), labels=T, nclass=20, main="", xlab="log(Ba)") 140 137 128 120 334 300 107 100 250 Frequency 234 80 Frequency 対数変換 200 69 60 60 150 40 100 30 23 20 50 16 11 21 3 4 4 4 4 4 0 0 0 1 1 0 0 1 0 0 0 50 100 150 2.0 2.5 3.0 3.5 4.0 4.5 5.0 Ba log(Ba)
21.
3.3.1 (2)Grubbs検定 > grubbs.test(moss.Ba.log)
Grubbs test for one outlier data: moss.Ba.log G = 5.5434, U = 0.9484, p-value = 5.892e-06 alternative hypothesis: highest value 5.16478597392351 is an outlier 140 137 128 120 107 100 Frequency 80 69 60 60 40 30 23 20 16 外れ値! 11 3 4 4 4 1 0 0 1 0 2.0 2.5 3.0 3.5 4.0 4.5 5.0 log(Ba)
22.
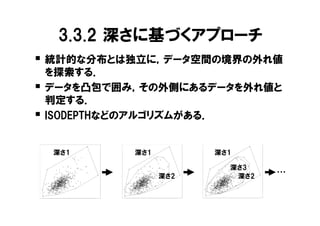
3.3.2 深さに基づくアプローチ
� 統計的な分布とは独立に,データ空間の境界の外れ値 を探索する. � データを凸包で囲み,その外側にあるデータを外れ値と 判定する. � ISODEPTHなどのアルゴリズムがある. 9.0 9.0 9.0 深さ1 深さ1 深さ1 8.5 8.5 8.5 深さ3 log(Ca) log(Ca) log(Ca) ・・・ 深さ2 深さ2 8.0 8.0 8.0 7.5 7.5 7.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 2.0 2.5 3.0 3.5 4.0 4.5 5.0 2.0 2.5 3.0 3.5 4.0 4.5 5.0 log(Ba) log(Ba) log(Ba)
23.
3.3.3 深さに基づくアプローチ � 深さ1~5までの凸包を生成する. >
library(depth) > isodepth(log(moss[, c("Ba", "Ca")]), dpth=1:5, mustdith=T, xlab="log(Ba)", ylab="log(Ca)") 9.0 8.5 log(Ca) 8.0 外れ値と判定する深さの閾値は, ユーザが指定する必要がある 7.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 log(Ba)
24.
3.4 空間的な近さに基づく方法 � 距離に基づくアプローチ,密度に基づくアプローチ等が
ある. 仮定・考え方 代表的な方法 距離に基づくアプローチ 近傍のデータ数が少ない � DB(ε, π)-外れ値 等 (distance-based データが外れ値(距離を用 approaches) いて近傍のデータ数をカウ ント) 密度に基づくアプローチ 近傍点と比べて密度が大 � LOF 等 (density-based method) いに異なるデータが外れ値
25.
3.4.1 距離に基づくアプローチ � DB(ε,
π)-outlier � 各データの周囲に半径ε以内に存在する点の割合がπ以下 の点を外れ値と判定する. ε 半径ε以内に 半径ε以内に 4点存在する 1点しか存在しない (割合=4/7=0.57) (割合=1/7=0.14) π=0.2のとき 外れ値でない 外れ値である
26.
3.4.2 密度に基づくアプローチ � 距離に基づくアプローチでは,データ全体を対象にデー
タ間の距離を計算しているので,以下のデータ o1, o2 は外れ値とはみなされない. � しかし,クラスターC1, C2を念頭におくと,o1, o2は外 れ値とみなすこともできる. 距離に基づく方法では 外れ値とはみなされない O1 C1 O2 C2
27.
3.4.2 密度に基づくアプローチ � 密度に基づくアプローチでは,このように局所的に発生
する外れ値を検出することを目的とする. � 代表的な手法がLOF(Local Outlier Factor) � データ点付近の密度と,近傍点付近の密度が著しく異なる 点を外れ値として判定する. データの近傍点を用いて データの近傍点の密度 推定した局所的な密度 密度が著しく異なる点を 外れ値と判定
28.
3.4.2 密度に基づくアプローチ
� 密度の推定に使用する近傍点の個数を10個として LOFを実行 > library(DMwR) > lof <- lofactor(log(moss[, c("Ba", "Ca")]), 10) > hist(lof, nclas=20, labels=T, main="", xlab="LOF") 285 250 200 Frequency 164 150 100 57 50 36 19 8 7 6 外れ値? 1 4 2 2 4 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 1.0 1.5 2.0 2.5 3.0 3.5 外れ値と判定するLOFの閾値は LOF ユーザが指定
29.
4. まとめ
30.
� 外れ値 =
データセット内で,他から著しく離れている データ. � 外れ値の検出は,統計的アプローチ,空間的な近さに 基づくアプローチ,クラスタリングに基づくアプローチな どが代表的. � 各アプローチが前提とする仮定・考え方が異なるので, データの性質に応じてアプローチや手法を選ぶべし.
31.
参考資料
文献名 著者 出版社等 コメント Data Mining: Jiawei Han, Morgan Kaufmann データマイニングの Concepts and Micheline Kamber, 代表的な教科書.ま Techniques(12章) Jian Pei とまっていて分かり やすい. Outlier Detection H-P.Kriegel, Tutorial Notes: 外れ値の検出に関し Techniques P.Kroger, A.Zimek SIAM SDM 2010, て俯瞰したサーベイ. Columbus, Ohio 一読すべし. Outlier Analysis Charu C. Aggarwal Springer 最近刊行された書 籍.若干敷居は高い が読む価値は大いに アリ. https://sites.google.c まとまっていて分かり om/site/scriptofbioin やすい.一度目を通 formatics/mian- すと良い. qiangmemo/waire- zhi-jian-chu-zhi-shi
Download









![3.2 外れ値の例
� Kolaデータセット(ロシアの土壌の成分)
> library(mvoutlier)
> data(moss)
data(moss
moss)
> dim(moss)
[1] 598 34
> moss[1:5, 1:10]
ID XCOO YCOO Ag Al As B Ba Bi Ca
1 1 547960.4 7693790 0.016 71.2 0.123 1.74 14.0 0.002 2310
2 2 770024.8 7679167 0.073 245.0 0.299 2.77 17.4 0.039 2460
3 3 498650.6 7668151 0.032 103.0 0.176 1.89 20.9 0.012 3430
4 4 795151.9 7569386 0.118 307.0 0.423 2.30 21.8 0.033 2860
5 5 437050.0 7855900 0.038 253.0 0.119 4.65 31.1 0.002 3190
Anne Ruiz-Gaze and Christine Thomas-Agnan,
Identification of local mutivariate outliers,
http://bit.ly/XqDlfG](https://image.slidesharecdn.com/random-130222225745-phpapp02/85/slide-11-320.jpg)
![3.1 外れ値
� 例2. バリウムとカルシウムの散布図(対数変換済み)
> corr.plot(log(moss$Ba), log(moss$Ca), xlab="log(Ba)", ylab="log(Ca)")
$cor.cla
[1] 0.663193
$cor.rob
[1] 0.7130014
Classical cor = 0.66 Robust cor = 0.71
9.0
8.5
log(Ca)
8.0
7.5
2.0 2.5 3.0 3.5 4.0 4.5 5.0
log(Ba)](https://image.slidesharecdn.com/random-130222225745-phpapp02/85/slide-13-320.jpg)




![3.3.1 (1)箱ひげ図 334
300
250
234
Frequency
200
150
100
> res <- boxplot(moss$Ba)
50
21
> res$stats 4 4 0 0 0 1
0
[,1] 0 50 100 150
Ba
[1,] 6.71
[2,] 15.20
150
[3,] 19.00
[4,] 23.90
100
[5,] 36.70 50
0](https://image.slidesharecdn.com/random-130222225745-phpapp02/85/slide-18-320.jpg)

![3.3.1 (2)Grubbs検定
� バリウムのデータは正規分布に従っていないので,対数
変換を行って正規分布に近づける.
> library(e1071)
> moss.Ba.log <- log(moss$Ba)
> kurtosis(moss.Ba.log)
[1] 2.690639
> hist(log(moss$Ba), labels=T, nclass=20, main="",
xlab="log(Ba)")
140
137
128
120
334
300
107
100
250
Frequency
234
80
Frequency
対数変換
200
69
60
60
150
40
100
30
23
20
50
16
11
21
3 4 4 4
4 4 0 0 0 1 1 0 0 1
0
0
0 50 100 150 2.0 2.5 3.0 3.5 4.0 4.5 5.0
Ba
log(Ba)](https://image.slidesharecdn.com/random-130222225745-phpapp02/85/slide-20-320.jpg)
![3.3.3 深さに基づくアプローチ
� 深さ1~5までの凸包を生成する.
> library(depth)
> isodepth(log(moss[, c("Ba", "Ca")]), dpth=1:5,
mustdith=T, xlab="log(Ba)", ylab="log(Ca)")
9.0
8.5
log(Ca)
8.0
外れ値と判定する深さの閾値は,
ユーザが指定する必要がある
7.5
2.0 2.5 3.0 3.5 4.0 4.5 5.0
log(Ba)](https://image.slidesharecdn.com/random-130222225745-phpapp02/85/slide-23-320.jpg)




![3.4.2 密度に基づくアプローチ
� 密度の推定に使用する近傍点の個数を10個として
LOFを実行
> library(DMwR)
> lof <- lofactor(log(moss[, c("Ba", "Ca")]), 10)
> hist(lof, nclas=20, labels=T, main="", xlab="LOF")
285
250
200
Frequency
164
150
100
57
50
36
19
8 7 6
外れ値?
1 4 2 2 4 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 1
0
1.0 1.5 2.0 2.5 3.0 3.5
外れ値と判定するLOFの閾値は
LOF
ユーザが指定](https://image.slidesharecdn.com/random-130222225745-phpapp02/85/slide-28-320.jpg)







![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)











![[研究室論文紹介用スライド] Adversarial Contrastive Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/acepub-181119101425-thumbnail.jpg?width=640&height=640&fit=bounds)

















































