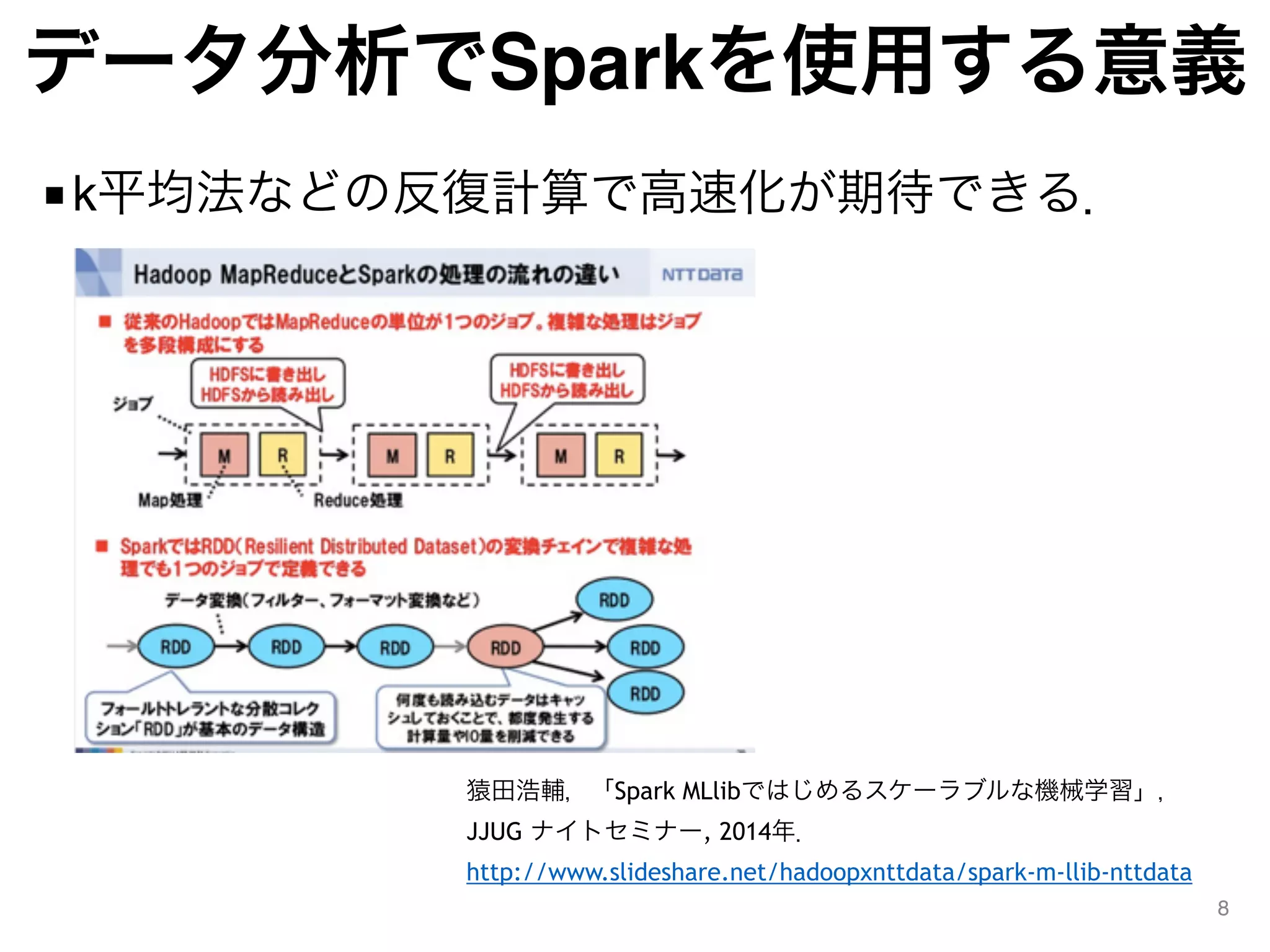
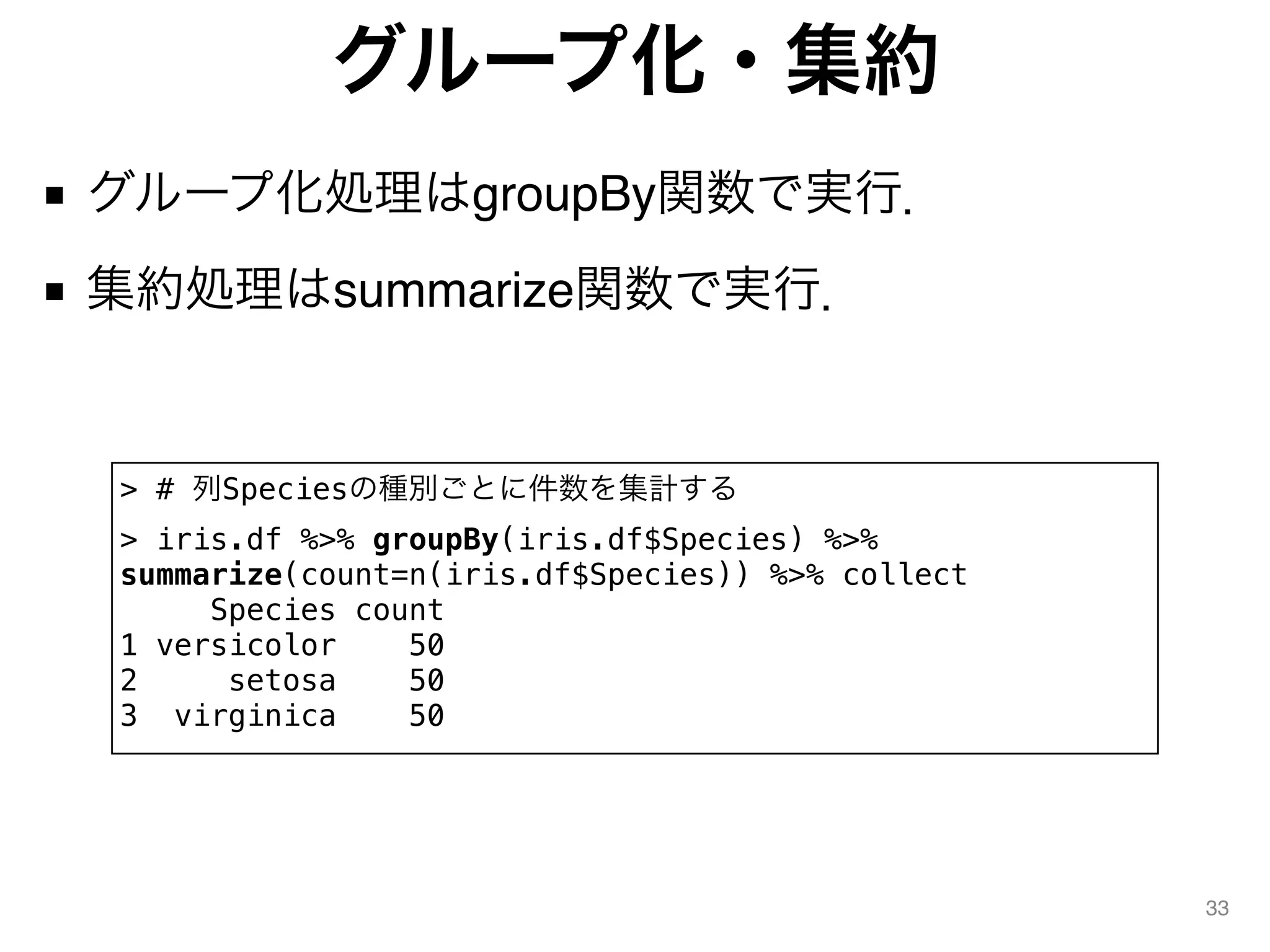
PySparkの起動
■ PySparkの起動
38
$ cd$SPARK_HOME/bin
$ ./pyspark
Python 2.7.9 (default, Feb 10 2015, 03:28:08)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.56)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-
defaults.properties
15/07/11 13:35:56 INFO SparkContext: Running Spark version 1.4.0
(中略)
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/__ / .__/_,_/_/ /_/_ version 1.4.0
/_/
Using Python version 2.7.9 (default, Feb 10 2015 03:28:08)
SparkContext available as sc, HiveContext available as sqlContext.
>>>












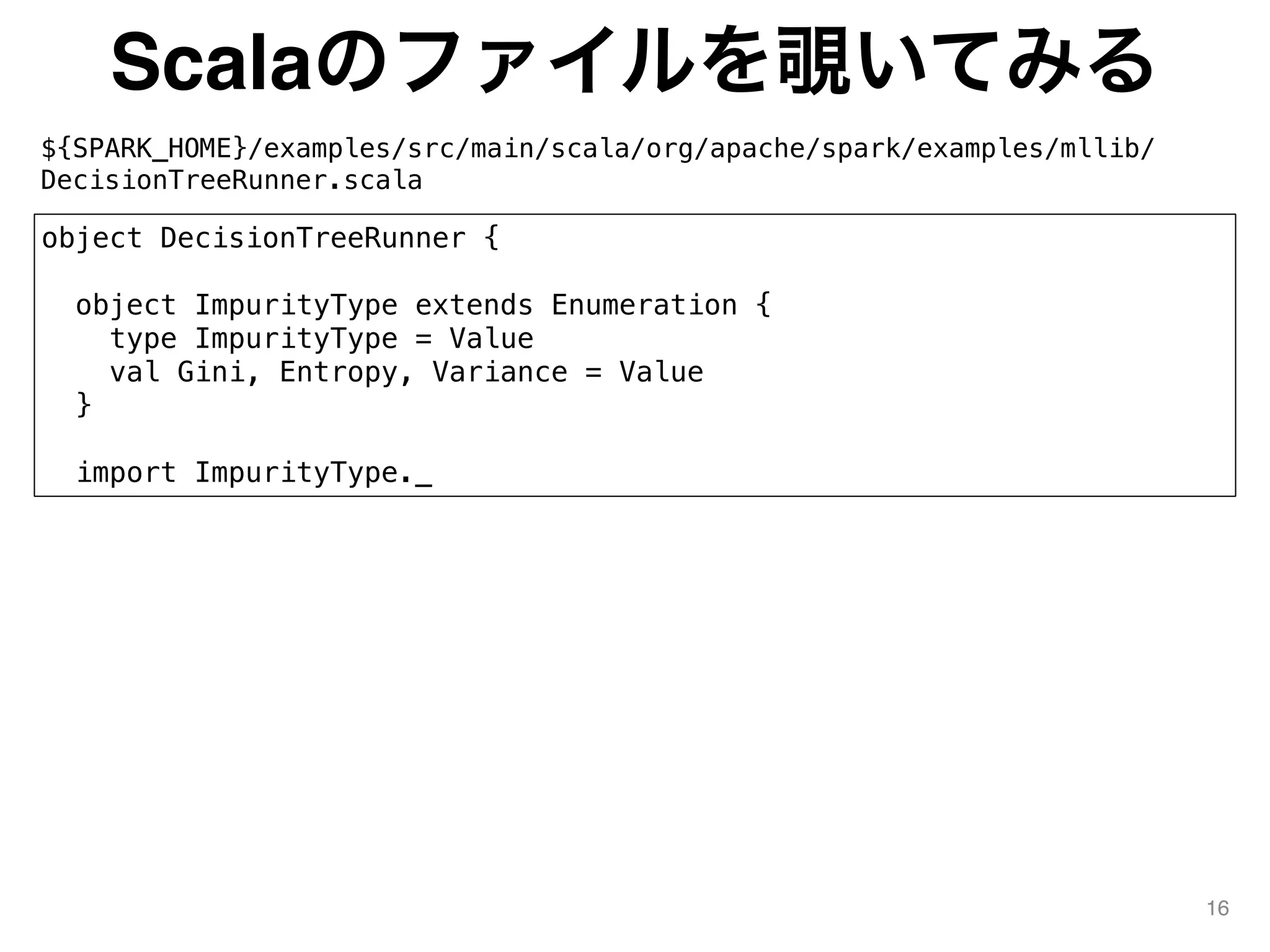
![Scalaのファイルを覗いてみる
${SPARK_HOME}/examples/src/main/scala/org/apache/spark/examples/mllib/
DecisionTreeRunner.scala
17
case class Params(
input: String = null,
testInput: String = "",
dataFormat: String = "libsvm",
algo: Algo = Classification,
maxDepth: Int = 5,
impurity: ImpurityType = Gini,
maxBins: Int = 32,
minInstancesPerNode: Int = 1,
minInfoGain: Double = 0.0,
numTrees: Int = 1,
featureSubsetStrategy: String = "auto",
fracTest: Double = 0.2,
useNodeIdCache: Boolean = false,
checkpointDir: Option[String] = None,
checkpointInterval: Int = 10) extends AbstractParams[Params]
def main(args: Array[String]) {](https://image.slidesharecdn.com/whydontyoucreatenewsparkjl-150711082324-lva1-app6891/75/Why-dont-you_create_new_spark_jl-17-2048.jpg)

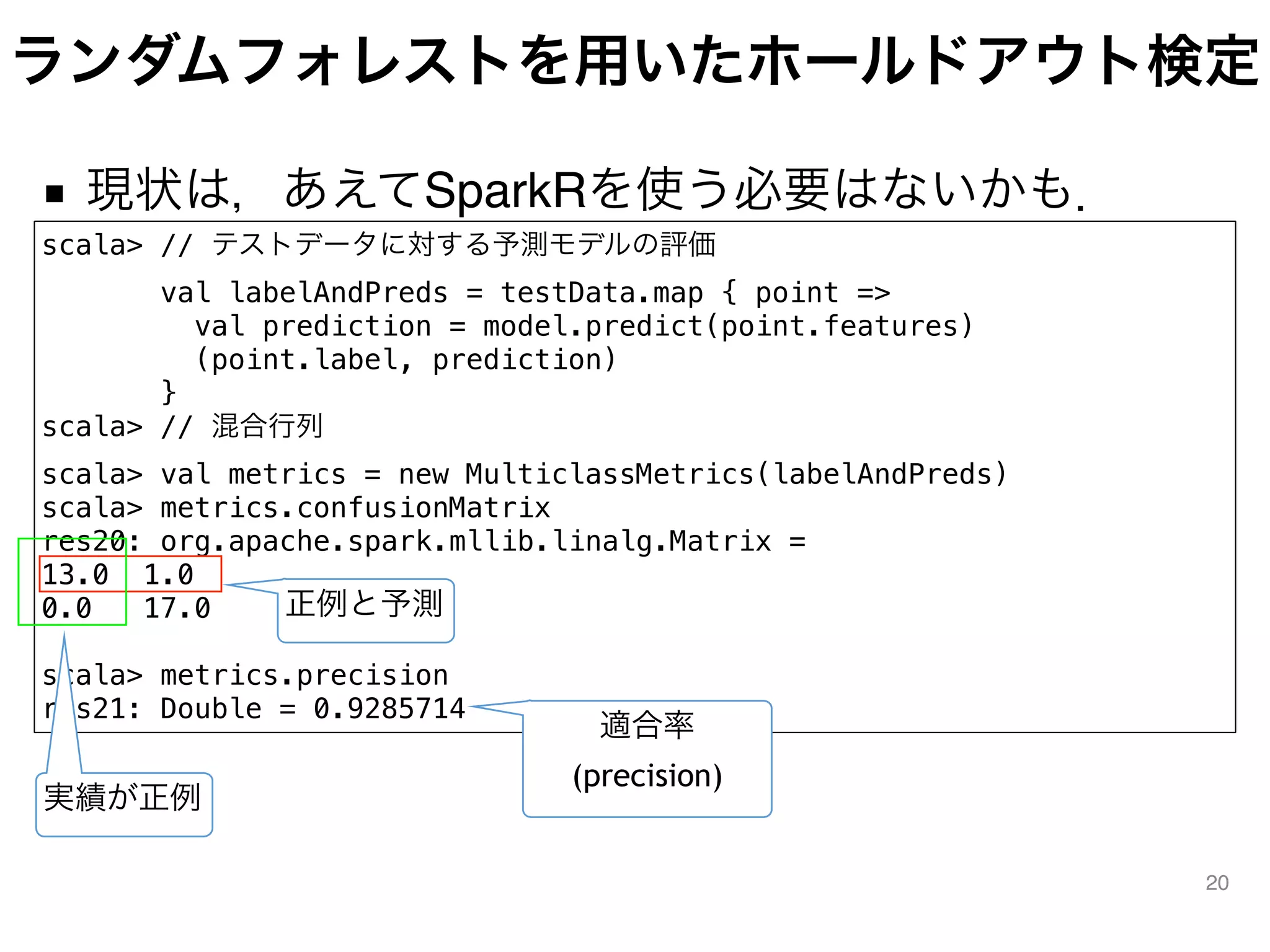
![ランダムフォレストを用いたホールドアウト検定
■ 現状は,あえてSparkRを使う理由はないかも
19
scala> // ランダムフォレストを用いた予測モデルの構築
scala> val numClasses = 2 // クラス数
scala> val categoricalFeaturesInfo = Map[Int, Int]() // カテゴリ変数の
情報
scala> val numTrees = 500 // 構築する決定木の個数
scala> val featureSubsetStrategy = "auto" // 特徴量選択のアルゴリズム
scala> val impurity = "gini" // 不純度に用いる指標
scala> val maxDepth = 5 // 木の最大の深さ
scala> val maxBins = 32
scala> val model = RandomForest.trainClassifier(trainingData,
numClasses, categoricalFeaturesInfo, numTrees,
featureSubsetStrategy, impurity, maxDepth, maxBins)](https://image.slidesharecdn.com/whydontyoucreatenewsparkjl-150711082324-lva1-app6891/75/Why-dont-you_create_new_spark_jl-19-2048.jpg)






![DataFrameオブジェクトの作成
■ createDataFrame関数によりRのデータフレームから作成
30
> iris.df <- createDataFrame(sqlContext, iris)
> iris.df
DataFrame[Sepal_Length:double, Sepal_Width:double,
Petal_Length:double, Petal_Width:double, Species:string]
> class(iris.df)
[1] "DataFrame"
attr(,"package")
[1] “SparkR"
> head(iris.df, 3)
Sepal_Length Sepal_Width Petal_Length Petal_Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa](https://image.slidesharecdn.com/whydontyoucreatenewsparkjl-150711082324-lva1-app6891/75/Why-dont-you_create_new_spark_jl-30-2048.jpg)





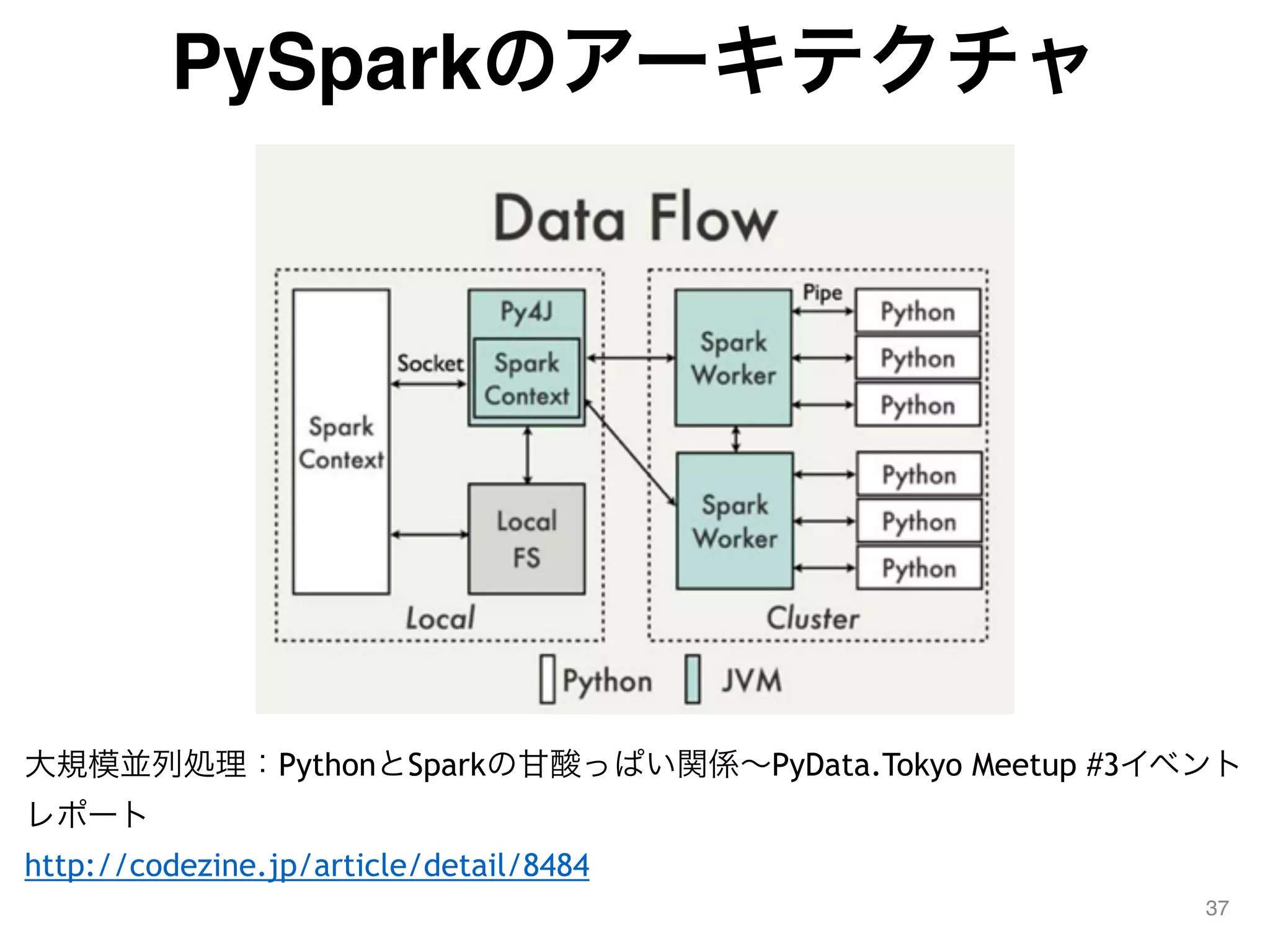
![PySparkの起動
■ PySparkの起動
38
$ cd $SPARK_HOME/bin
$ ./pyspark
Python 2.7.9 (default, Feb 10 2015, 03:28:08)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.56)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-
defaults.properties
15/07/11 13:35:56 INFO SparkContext: Running Spark version 1.4.0
(中略)
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/__ / .__/_,_/_/ /_/_ version 1.4.0
/_/
Using Python version 2.7.9 (default, Feb 10 2015 03:28:08)
SparkContext available as sc, HiveContext available as sqlContext.
>>>](https://image.slidesharecdn.com/whydontyoucreatenewsparkjl-150711082324-lva1-app6891/75/Why-dont-you_create_new_spark_jl-38-2048.jpg)
![MLlibの使用
■ランダムフォレストの実行
39
>>> from pyspark.mllib.tree import RandomForest, RandomForestModel
>>> from pyspark.mllib.util import MLUtils
>>> # データファイルをロードしパースしてLabeledPointのRDDに変換
>>> data = MLUtils.loadLibSVMFile(sc,
... ’../data/mllib/sample_libsvm_data.txt’)
>>> # データを訓練用とテスト用に分割 (テスト用は30%)
>>> (trainingData, testData) = data.randomSplit([0.7, 0.3], seed=123)
>>> # ランダムフォレストを用いた予測モデル構築
>>> model = RandomForest.trainClassifier(
... trainingData, numClasses=2,
... categoricalFeaturesInfo={}, numTrees=3,
... featureSubsetStrategy=‘auto’, impurity='gini',
... maxDepth=4, maxBins=32)
>>> # テストデータに対してモデルを評価し,誤差を算出
>>> predictions = model.predict(testData.map(lambda x: x.features))
>>> labelsAndPredictions = testData.map(
... lambda lp: lp.label).zip(predictions)
>>> testErr = labelsAndPredictions.filter(
... lambda (v, p): v != p).count() / float(testData.count())
>>> print('Test Error = ' + str(testErr))
>>> print('Learned classification forest model:')
>>> print(model.toDebugString())
自然な記述が可能](https://image.slidesharecdn.com/whydontyoucreatenewsparkjl-150711082324-lva1-app6891/75/Why-dont-you_create_new_spark_jl-39-2048.jpg)



































![[機械学習]文章のクラス分類](https://cdn.slidesharecdn.com/ss_thumbnails/ss-160218112331-thumbnail.jpg?width=640&height=640&fit=bounds)






![[データマイニング+WEB勉強会][R勉強会] はじめてでもわかる 統計解析・データマイニング R言語入門](https://cdn.slidesharecdn.com/ss_thumbnails/rlecturehamada100213-100216161757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Oracle big data jam session #1] Apache Spark ことはじめ](https://cdn.slidesharecdn.com/ss_thumbnails/oraclebigdatajamsession1apachesparkquickstart-191127094941-thumbnail.jpg?width=640&height=640&fit=bounds)








![SparkとJupyterNotebookを使った分析処理 [Html5 conference]](https://cdn.slidesharecdn.com/ss_thumbnails/html5conference-160903045852-thumbnail.jpg?width=640&height=640&fit=bounds)






















