K-平均法のアルゴリズム
• 言葉で言ってもわかんないので、可視化した
ものをみてみましょう。
入力: アルゴリズム: 出力:
多次元データX(nxp) *K平均法 データの属するクラスタ
評価関数、
n
L min || xi cl ||
l 1,, k
i 1
を最小化している
クラスタ数k のと同じ。 クラスタ中心
k=3 C {c1 ,ck }
*アルゴリズムの詳細は下記リンクをチェック!
http://d.hatena.ne.jp/nitoyon/20090409/kmeans_visualise
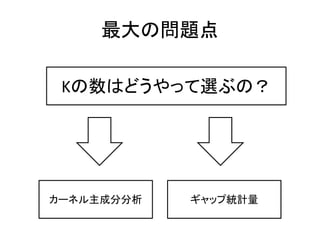
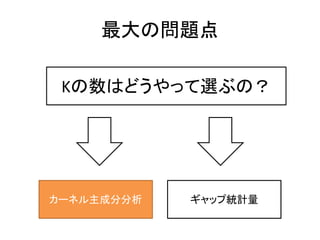
カーネル主成分分析
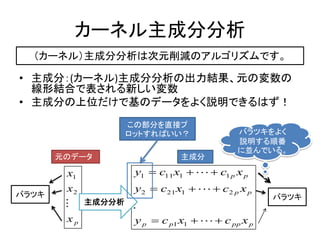
(カーネル)主成分分析は次元削減のアルゴリズムです。
•主成分:(カーネル)主成分分析の出力結果、元の変数の
線形結合で表される新しい変数
• 主成分の上位だけで基のデータをよく説明できるはず!
この部分を直接プ
ロットすればいい? バラツキをよく
説明する順番
に並んでいる。
元のデータ 主成分
x1 y1 c11 x1 c1 p x p
x2 y2 c21 x1 c2 p x p
バラツキ バラツキ
主成分分析
xp y p c p1 x1 c pp x p
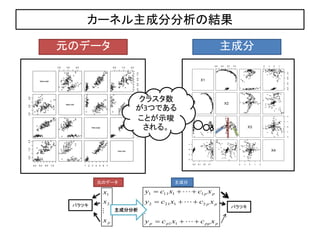
カーネル主成分分析の結果
元のデータ 主成分
クラスタ数
が3つである
ことが示唆
される。
元のデータ 主成分
x1 y1 c11 x1 c1 p x p
x2 y2 c21 x1 c2 p x p
バラツキ バラツキ
主成分分析
xp y p c p1 x1 c pp x p
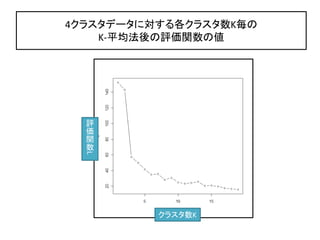
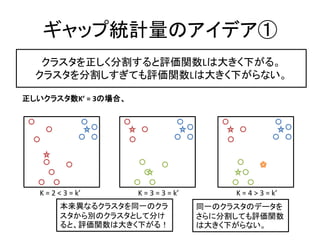
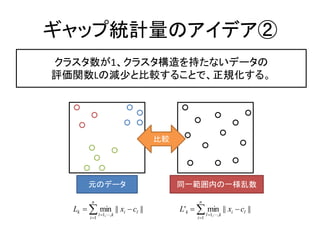
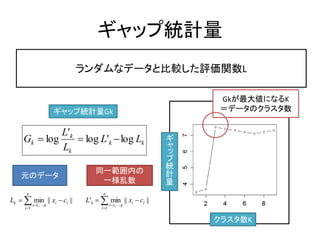
ギャップ統計量
ランダムなデータと比較した評価関数L
Gkが最大値になるK
ギャップ統計量Gk =データのクラスタ数
L'k
Gk log log L'k log Lk ギ
Lk ャ
ッ
プ
統
同一範囲内の 計
元のデータ
一様乱数 量
n n
Lk min || xi cl || L'k min || xi cl ||
l 1,, k l 1,, k
i 1 i 1
クラスタ数K
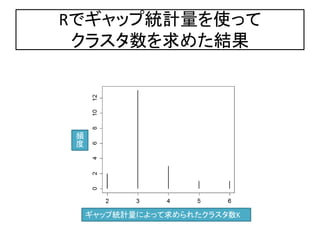
29.
Rでギャップ統計量を使ってデータの
クラスタ数を推定する
> library(SLmisc) Package SLmisc
> x <- iris[,1:4]
> gap <- c() やっぱりIrisデータ
> for (i in 1:20){ 150x4 ,3class
+ kg <- kmeansGap(x)
ギャップ統計
+ nc <- length(kg$cluster$size) 量を求める。 20回
+ gap <- c(gap,nc)
推定されたク くりか
+}
えし
> par(ps=16) ラスタ数を取
> plot(table(gap),xlab="k : num. 得する。
of clusters",ylab="freq.")
推定されたクラス
タ数のヒストグラ
ムを作成




![クラスタリングのアルゴリズム
@hamadakoichiさんの資料より
[データマイニング+WEB勉強会][R勉強会] R言語によるクラスター分析 - 活用編
http://www.slideshare.net/hamadakoichi/r-3754836](https://image.slidesharecdn.com/02-kver2-0-110528032516-phpapp02/85/02-k-ver2-0-6-320.jpg)


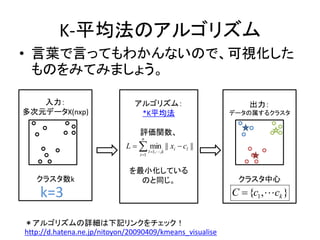


![Rでカーネル主成分分析を行う
>library(kernlab) Package kernlab
>x<-as.matrix(iris[,1:4]) Irisデータ
>gamma<-median(dist(x)) 150x4 ,3class
>sigma<-1/(2*gamma^2) ガウスカーネルのパラ
>kp<-kpca(x, kernel=“rbfdot”, メータσを作成
kpar=list(sigma=sigma)) ガウスカーネルで
>plot(iris[, 1:4]) カーネル主成分分析
>plot(data.frame(pcv(kp)) 元のデータで散布図
[,1:4])
主成分で散布図](https://image.slidesharecdn.com/02-kver2-0-110528032516-phpapp02/85/02-k-ver2-0-16-320.jpg)


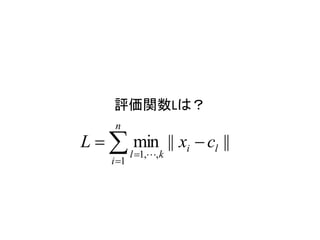



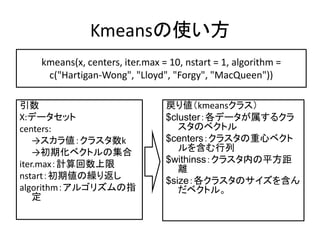
![Rでギャップ統計量を使ってデータの
クラスタ数を推定する
> library(SLmisc) Package SLmisc
> x <- iris[,1:4]
> gap <- c() やっぱりIrisデータ
> for (i in 1:20){ 150x4 ,3class
+ kg <- kmeansGap(x)
ギャップ統計
+ nc <- length(kg$cluster$size) 量を求める。 20回
+ gap <- c(gap,nc)
推定されたク くりか
+}
えし
> par(ps=16) ラスタ数を取
> plot(table(gap),xlab="k : num. 得する。
of clusters",ylab="freq.")
推定されたクラス
タ数のヒストグラ
ムを作成](https://image.slidesharecdn.com/02-kver2-0-110528032516-phpapp02/85/02-k-ver2-0-29-320.jpg)