Recommended
PPTX
PPT
PPT
PPT
PDF
PDF
PDF
PPTX
PDF
2014年5月14日_水曜セミナー発表内容_FINAL
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
PDF
KEY
第5章 統計的仮説検定 (Rによるやさしい統計学)
PDF
「全ての確率はコイン投げに通ず」 Japan.R 発表資料
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PPT
More Related Content
PPTX
PPT
PPT
PPT
PDF
PDF
PDF
PPTX
What's hot
PDF
2014年5月14日_水曜セミナー発表内容_FINAL
PPTX
PDF
PDF
PDF
PDF
PDF
PDF
基礎からのベイズ統計学 輪読会資料 第4章 メトロポリス・ヘイスティングス法
PDF
KEY
第5章 統計的仮説検定 (Rによるやさしい統計学)
PDF
「全ての確率はコイン投げに通ず」 Japan.R 発表資料
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
PDF
Similar to K070k80 点推定 区間推定
PDF
PPT
PPT
PPT
PDF
2014年度秋学期 統計学 第12回 分布の平均を推測する - 区間推定 (2014. 12. 17)
PDF
第6章 2つの平均値を比較する - TokyoR #28
PDF
PDF
2022年度春学期 統計学 第13回 不確かな測定の不確かさを測るー不偏分散とt分布
PDF
PDF
2021年度秋学期 統計学 第13回 不確かな測定の不確かさを測る - 不偏分散とt分布(2021. 12. 21)
PDF
PDF
PDF
2020年度秋学期 統計学 第13回 不確かな測定の不確かさを測る ー 不偏分散とt分布 (2020. 12. 22)
PDF
PDF
2022年度秋学期 統計学 第13回 不確かな測定の不確かさを測る - 不偏分散とt分布 (2022. 12. 20)
PDF
PDF
PPT
PDF
20130223_集計・分析の基礎@アンケート研究会
PDF
LET2015 National Conference Seminar
More from t2tarumi
PPT
PPT
PPT
PPT
K030 appstat201203 2variable
PPT
PPT
PDF
PPT
PPT
PPT
PPT
PPT
PPT
K070k80 点推定 区間推定 1. 統計的推測 Statistical Inference
推定と検定
母集団と標本
点推定
区間推定
2007.07.04 母平均のまとめ追加
2007.05.25 情報統計学 R より編集
2008.06.20 一部編集
2012.07.06 不偏分散
20120713 信頼区間
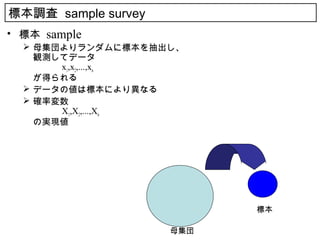
2. 3. 標本調査 sample survey
• 標本 sample
母集団よりランダムに標本を抽出し、
観測してデータ
x1,x2,...,xn
が得られる
データの値は標本により異なる
確率変数
X1,X2,...,Xn
の実現値
標本
母集団
4. 可能な標本の組数
• 有限母集団の場合
母集団の構成要素(岡山大学の全学生数)
N ( N=13,000
)
標本数
n ( n=10
)
• 可能な標本の組数
M = NCn
• どの組を標本に選ぶか?!
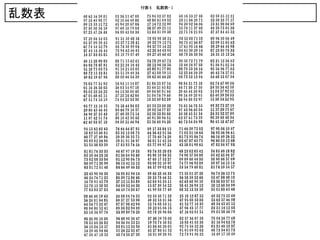
5. 無作為抽出 random sampling
• 独立性の保証
乱数
• 乱数表
• 乱数賽(サイコロ)
• 非復元無作為抽出 without replacement
• 復元無作為抽出 with replacement
• 層別抽出法 stratified sampling
6. 7. 8. 9. 47 都道府県
• 1 北海道 • 24 三重
• 2 青森 • 25 滋賀
• 3 岩手 • 26 京都
• 4 秋田 • 27 大阪
• 5 宮城 • 28 兵庫
• 6 山形 • 29 奈良
• 7 福島 • 30 和歌
• 8 茨城 • 31 鳥取
• 9 栃木 • 32 島根
• 10 群馬 • 33 岡山
• 11 埼玉 • 34 広島
• 12 千葉 • 35 山口
• 13 東京 • 36 徳島
• 14 神奈川 • 37 香川
• 15 新潟 • 38 愛媛
• 16 富山 • 39 高知
• 17 石川 • 40 福岡
• 18 福井 • 41 佐賀
• 19 山梨 • 42 長崎
• 20 長野 • 43 熊本
• 21 岐阜 • 44 大分
• 22 静岡 • 45 宮崎
• 23 愛知 • 46 鹿児島
• 47 沖縄
10. 11. 推定と検定
• 推定 estimation
母集団の特性値に何の情報もない
特性値の値はどんな値か知りたい
• 点推定 point estimation
• 区間推定 interval estimation/ confidence interval
• 検定 testing
母集団の特性値についてある情報を持っている
その情報が正しいか否かを知りたい
• 帰無仮説と対立仮説
null hypothesis/ alternative hypothesis
12. 点推定
• 仮想的な母集団
i 名前
> p1 <- c(148, 160, 159, 153, 151, 140)
θi > p1
[1] 148 160 159 153 151 140
1 A 148 > mean(p1)
[1] 151.8333 母平均
2 B 160 > var(p1)
3 C 159 [1] 54.96667 母分散
4 D 153
5 E 151
6 F 140
13. 標本の取り出し方
6⋅5
M = N Cn = 6 C4 = = 15
2 ⋅1
標本 x1 x2 x3 x4 標本平均
1 ABCD 148 160 159 153 155.00
2 ABCE 148 160 159 151 154.50
3 ABCF 148 160 159 140 151.75 > mean(c(159, 153, 151, 140))
[1] 150.75
4 ABDE 148 160 153 151 153.00
途中省略
5 ABDF 148 160 153 140 150.25
6 ABEF 148 160 151 140 149.75 > mean(c(159, 153, 151, 140))
7 ACDE 148 159 153 151 152.75 [1] 150.75
> mean(c(155.00, 154.50, 151.75, 153.00, 150.25
8 ACDF 148 159 153 140 150.00
+ 149.75, 152.75, 150.00, 149.50, 148.00,
9 ACEF 148 159 151 140 149.50 + 155.75, 153.00, 152.50, 151.00, 150.75))
10 ADEF 148 153 151 140 148.00 [1] 151.8333
11 BCDE 160 159 153 151 155.75
12 BCDF 160 159 153 140 153.00
13 BCEF 160 159 151 140 152.75
14 BDEF 160 153 151 140 151.00
15 CDEF 159 153 151 140 150.75
総平均 151.833
14. 15. 点推定と区間推定 15
• 未知母数 ( パラメータ )θ を推定するには 2 つの方法がある
区間推定
• 区間で当てる
点推定
• 点で当てる
たった一組のデータで求めた値が,母平均の値などに一致する可能性
は少ない
• 区間推定
θ1≦θ≦θ2 のようにある幅をつけて母数 θ を推定する方法
• パラメータ θ が入るであろう範囲を一定の信頼度(確率)で指定
• 点推定
θ=θ0 として,幅をつけずに一個の推定値で推定
一点で当てる
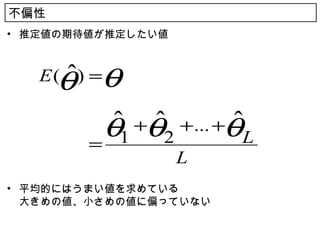
16. 点推定に望まれる性質 16
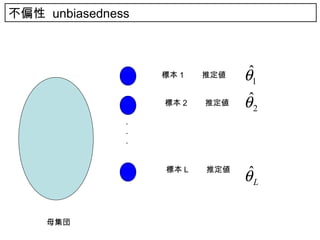
• 不偏性
標本に基づいて推定した値が,偏っていない
• 何回も推定を繰り返すと,平均的には,推定したい値 θ にあって
いる
• 一致性
n を N に近づけたとき,全数調査の値,母集団のパラメータ θ に一致
してほしい
• 有効性
一致性,不偏性を満たすものは多数
推定量の分散が小さいほうが望ましい
• 最尤法
あとで説明。
17. 不偏性 17
何回も推定を繰り返すと,平均的に
は推定したい値 θ に合っている
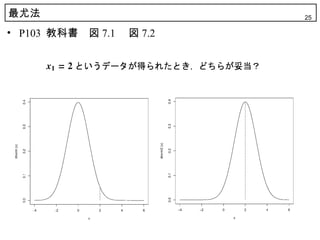
18. 19. 20. 21. 22. 23. 24. 25. 最尤法 25
• P103 教科書 図 7.1 図 7.2
26. 27. 28. 29. 30. 31. 正規分布の平均の点推定
1
• 標本平均が
不偏性
µ
ˆ = ∑ Xi
n i
一致性
有効性 (BLUE)
最尤性
• のすべての意味で、一番良い推定量である。
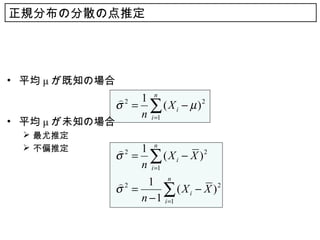
32. 正規分布の分散の点推定
• 平均 μ が既知の場合
2 1 n
σ = ∑ ( X i − µ )2
n i =1
• 平均 μ が未知の場合
最尤推定
不偏推定 2 1 n
σ = ∑ ( X i − X )2
n i =1
2 1 n
σ = ∑
n − 1 i =1
( X i − X )2
33. 不偏分散
n
E[ S ] = E[ ∑ ( X i − X ) 2 ]
2
i =1
n
= E[∑ {( X i − µ ) − ( X − µ )}2 ]
i =1
n
= E[ ∑ ( X i − µ ) 2 − n ( X − µ ) 2 ]
i =1
n
= E[∑ (X i − µ ) 2 ] − nE[( X − µ ) 2 ]
i =1
σ2 1 2 1 n
= nσ 2 − n
n
U = 2
n −1
S = ∑
n − 1 i =1
(X i − X ) 2
= (n − 1)σ 2
1 1
E[U ] =
2
E[ S ] =
2
(n − 1)σ 2 = σ 2
n −1 n −1
34. 35. 36. 37. 区間推定 37
• たった一組のデータで求めた値が,母平均の値に一
致する可能性は少ない。
• 区間を求める「区間推定」を考える
求める区間の幅はできるだけ狭く
定めた区間内にパラメータが入っている確率はできるだけ
大きくなるように
• 同時に満たすことは難しい
確率に条件を付ける
• 信頼度 1-α を定める。
• 求めた推定区間の中にパラメータが入っている確率が
1-α 以上になる区間のなかで,幅をできるだけ狭くする
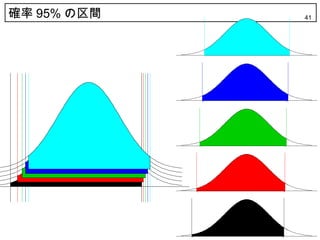
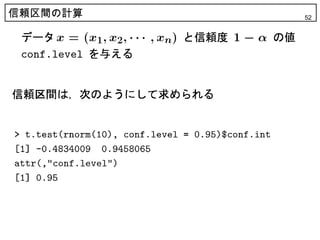
38. 39. 40. 信頼区間の幅 40
> xseq<-seq(0.001, 0.049, 0.0001)
0.4
> cL<-qnorm(xseq)
> cU<-qnorm(1-0.05+xseq)
0.3
> Ran<-cU-cL
> plot(Ran)
dnorm (x)
0.2
> which.min(Ran)
[1] 241
> points(241,Ran[241],col="red")
0.1
> xseq[241]
[1] 0.025
0.0
> cbind(cL,cU,Ran) -3 -2 -1 0 1 2 3
cL cU Ran x
[1,] -3.090232 1.654628 4.744860
4.6
[2,] -3.061814 1.655614 4.717428
[3,] -3.035672 1.656602 4.692274
省略
4.4
Ran
[239,] -1.963398 1.956553 3.919951
[240,] -1.961678 1.958256 3.919934
4.2
[241,] -1.959964 1.959964 3.919928
[242,] -1.958256 1.961678 3.919934
4.0
[243,] -1.956553 1.963398 3.919951
以下省略 0 100 200 300 400 500
41. 42. 43. シミュレーション 43
• R の関数 rnorm は N(0, 1) に従う乱数を生成
これを母集団と考えて, 10 個の乱数(標本)をとり,
母平均の信頼度 1-α=0.95 の信頼区間を作る
44. 45. 46. 46
• 区間推定を 100 回繰り返して,確かめてみる。
区間を 100 個作る。
> for(i in 1:100){
print(conf.interval(rnorm(10), 0.95, 1))
}
• 関数 sim.conf.interval
シミュレーションの回数,標本数,信頼度
標本数 n=10 ・信頼度 1-α=0.95 ・シミュレーション回数 5 回
sim.conf.interval(5, 10, 0.95)
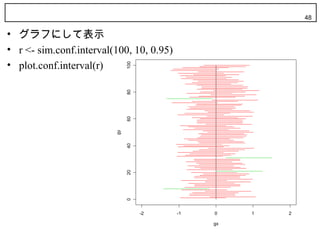
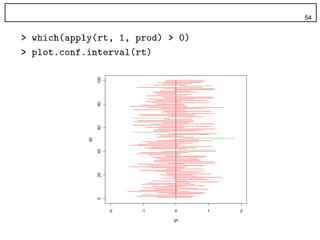
47. 48. 48
• グラフにして表示
• r <- sim.conf.interval(100, 10, 0.95)
• plot.conf.interval(r)
100
80
60
gy
40
20
0
-2 -1 0 1 2
gx
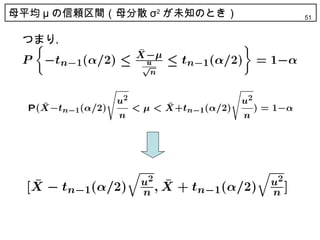
49. 母平均 μ の信頼区間(母分散 σ2 が未知のとき) 49
• 母分散 σ2 が未知のときは,先ほどの方法は使えない
• ここで次の性質を使う。( σ2 は未知なため, σ は使えない)
50. 51. 52. 53. 54. gy
0 20 40 60 80 100
-2
-1
0
gx
1
2
54
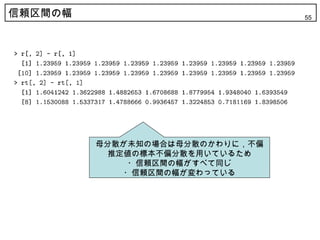
55. 信頼区間の幅 55
母分散が未知の場合は母分散のかわりに,不偏
推定値の標本不偏分散を用いているため
・信頼区間の幅がすべて同じ
・信頼区間の幅が変わっている
56. 演習 56
• N(0,1) に従う乱数を 999 個作成し,小さいほうから 25 番目,
975 番目の値を求め, qnorm 関数より, α=0.025 の値, α =
0.975 の値と比較せよ。
並べ替えは sort 関数で行うことができる
• sort(x) で x を小さい順に並べ替える
– その 1 番目の値を見るためには, sort(x)[1]
57. レポート 57
• N(0,1) に従う乱数を 16 個発生させ,その平均を求めることを
999 回繰り返す。
999 個の平均の,平均を求めよ。
小さいほうから 25 番目の値と、 975 番目の値を求めよ。
Editor's Notes #41 > curve(dnorm,-3,3) > abline(h=0) > segments(cL[50],0,cL[50],dnorm(cL[50]),col="blue") > segments(cU[50],0,cU[50],dnorm(cU[50]),col="blue") > segments(cL[241],0,cL[241],dnorm(cL[241]),col="red") > segments(cU[241],0,cU[241],dnorm(cU[241]),col="red") > #42 xseq<-seq(0.001, 0.049, 0.0001) cL<-qnorm(xseq) cU<-qnorm(1-0.05+xseq) dr <- function(i, col, offset=0) { j1<-which(g$x>cL[i])[1] temp.j2<-which(g$x<cU[i]) j2<-temp.u[length(temp.u)] xx<-c(cL[i],g$x[j1:j2],cU[i]) yy<-dnorm(xx) xxx<-c(xx[length(xx)],xx[length(xx)],xx[1],xx[1],xx) yyy<-c(yy[length(yy)],0,0,yy[1],yy) polygon(xxx,yyy+offset,col=col) } ###============================== par(mar=c(1,1,1,1)) id<-c(50,100,150,200,251) layout(matrix(5:1,ncol=1)) k<-0 for(j in id) { k<-k+1 curve(dnorm,-3,3,frame=F,axes=F,xlab="") abline(h=0) ##dr(j,rgb(j,j,j,max=255)) dr(j,k) abline(v=cL[j],col=k) abline(v=cU[j],col=k) h<-0 h<-h-0.005 arrows(cL[j],h,cU[j],h,code=3,length=0.1,col=k) } ##========================================= par(mfrow=c(1,1),mar=c(1,1,1,1)) curve(dnorm,-3,3,frame=F,axes=F,ylim=c(-0.05,0.5),xlab="",ylab="") i<-50; abline(v=cL[i],col=1); abline(v=cU[i],col=1) i<-100; abline(v=cL[i],col=2); abline(v=cU[i],col=2) i<-150; abline(v=cL[i],col=3); abline(v=cU[i],col=3) i<-200; abline(v=cL[i],col=4); abline(v=cU[i],col=4) i<-251; abline(v=cL[i],col=5); abline(v=cU[i],col=5) dr(50,1,0) lines(g$x,g$y+0.02) dr(100,2,0.02) lines(g$x,g$y+0.04) dr(150,3,0.04) lines(g$x,g$y+0.06) dr(200,4,0.06) lines(g$x,g$y+0.08) dr(251,5,0.08) abline(h=0)







![点推定
• 仮想的な母集団
i 名前
> p1 <- c(148, 160, 159, 153, 151, 140)
θi > p1
[1] 148 160 159 153 151 140
1 A 148 > mean(p1)
[1] 151.8333 母平均
2 B 160 > var(p1)
3 C 159 [1] 54.96667 母分散
4 D 153
5 E 151
6 F 140](https://image.slidesharecdn.com/k070k80-130416203044-phpapp01/85/K070k80-12-320.jpg)
![標本の取り出し方
6⋅5
M = N Cn = 6 C4 = = 15
2 ⋅1
標本 x1 x2 x3 x4 標本平均
1 ABCD 148 160 159 153 155.00
2 ABCE 148 160 159 151 154.50
3 ABCF 148 160 159 140 151.75 > mean(c(159, 153, 151, 140))
[1] 150.75
4 ABDE 148 160 153 151 153.00
途中省略
5 ABDF 148 160 153 140 150.25
6 ABEF 148 160 151 140 149.75 > mean(c(159, 153, 151, 140))
7 ACDE 148 159 153 151 152.75 [1] 150.75
> mean(c(155.00, 154.50, 151.75, 153.00, 150.25
8 ACDF 148 159 153 140 150.00
+ 149.75, 152.75, 150.00, 149.50, 148.00,
9 ACEF 148 159 151 140 149.50 + 155.75, 153.00, 152.50, 151.00, 150.75))
10 ADEF 148 153 151 140 148.00 [1] 151.8333
11 BCDE 160 159 153 151 155.75
12 BCDF 160 159 153 140 153.00
13 BCEF 160 159 151 140 152.75
14 BDEF 160 153 151 140 151.00
15 CDEF 159 153 151 140 150.75
総平均 151.833](https://image.slidesharecdn.com/k070k80-130416203044-phpapp01/85/K070k80-13-320.jpg)















![不偏分散
n
E[ S ] = E[ ∑ ( X i − X ) 2 ]
2
i =1
n
= E[∑ {( X i − µ ) − ( X − µ )}2 ]
i =1
n
= E[ ∑ ( X i − µ ) 2 − n ( X − µ ) 2 ]
i =1
n
= E[∑ (X i − µ ) 2 ] − nE[( X − µ ) 2 ]
i =1
σ2 1 2 1 n
= nσ 2 − n
n
U = 2
n −1
S = ∑
n − 1 i =1
(X i − X ) 2
= (n − 1)σ 2
1 1
E[U ] =
2
E[ S ] =
2
(n − 1)σ 2 = σ 2
n −1 n −1](https://image.slidesharecdn.com/k070k80-130416203044-phpapp01/85/K070k80-33-320.jpg)






![信頼区間の幅 40
> xseq<-seq(0.001, 0.049, 0.0001)
0.4
> cL<-qnorm(xseq)
> cU<-qnorm(1-0.05+xseq)
0.3
> Ran<-cU-cL
> plot(Ran)
dnorm (x)
0.2
> which.min(Ran)
[1] 241
> points(241,Ran[241],col="red")
0.1
> xseq[241]
[1] 0.025
0.0
> cbind(cL,cU,Ran) -3 -2 -1 0 1 2 3
cL cU Ran x
[1,] -3.090232 1.654628 4.744860
4.6
[2,] -3.061814 1.655614 4.717428
[3,] -3.035672 1.656602 4.692274
省略
4.4
Ran
[239,] -1.963398 1.956553 3.919951
[240,] -1.961678 1.958256 3.919934
4.2
[241,] -1.959964 1.959964 3.919928
[242,] -1.958256 1.961678 3.919934
4.0
[243,] -1.956553 1.963398 3.919951
以下省略 0 100 200 300 400 500](https://image.slidesharecdn.com/k070k80-130416203044-phpapp01/85/K070k80-40-320.jpg)









![演習 56
• N(0,1) に従う乱数を 999 個作成し,小さいほうから 25 番目,
975 番目の値を求め, qnorm 関数より, α=0.025 の値, α =
0.975 の値と比較せよ。
並べ替えは sort 関数で行うことができる
• sort(x) で x を小さい順に並べ替える
– その 1 番目の値を見るためには, sort(x)[1]](https://image.slidesharecdn.com/k070k80-130416203044-phpapp01/85/K070k80-56-320.jpg)





























































