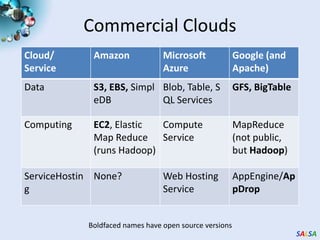
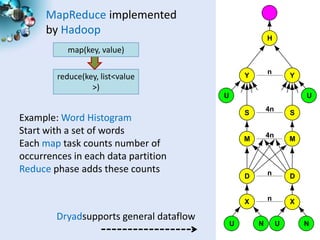
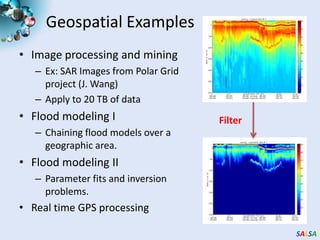
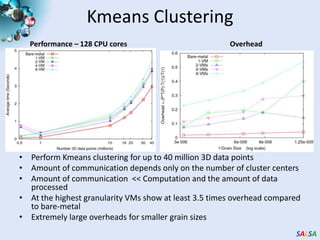
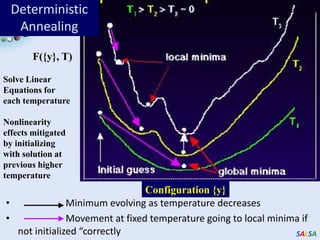
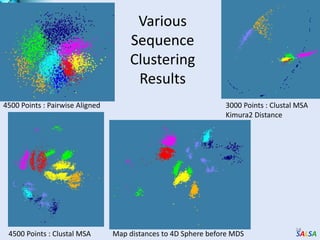
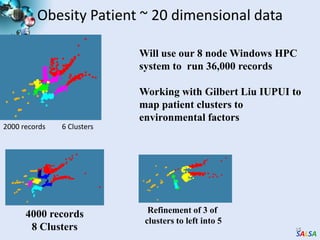
Cloud computing provides outsourced computing infrastructure and tools like Hadoop and Dryad for data-parallel processing. Commercial clouds are proprietary but open-source versions exist. Building open-architecture clouds requires understanding hardware, virtualization, services, and runtimes best practices. Cloud runtimes can run data-file parallel and dataflow applications at large scales for problems in areas like biology, geospatial processing, and clustering. Deterministic annealing is a parallelizable algorithm for data clustering that has been run on clouds. Clouds may change scientific computing by providing controllable, sustainable infrastructure without local clusters.














































![Cloud Computing Bootcamp On The Google App Engine [v1.1]](https://cdn.slidesharecdn.com/ss_thumbnails/cloudcomputingbootcamponthegoogleappenginev1-1-090506155059-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











































