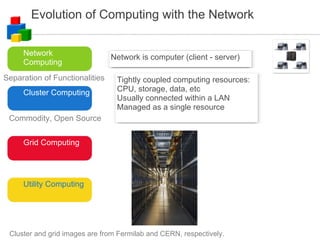
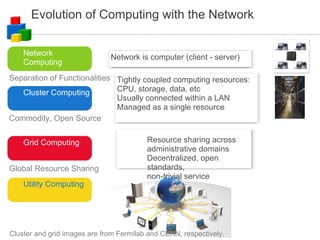
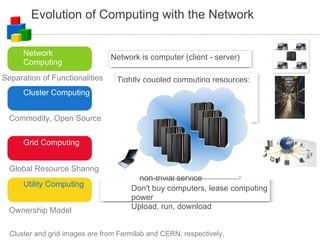
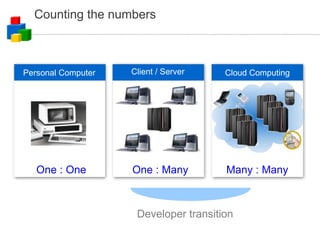
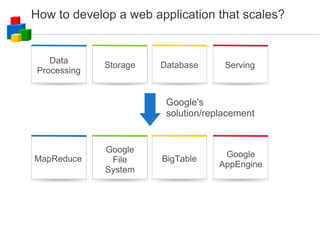
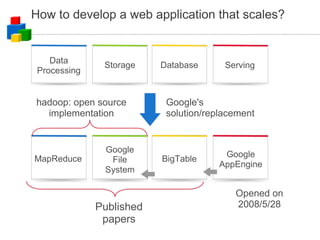
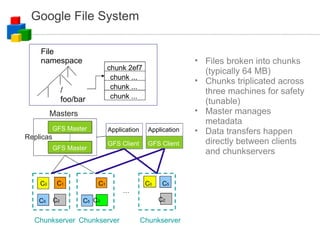
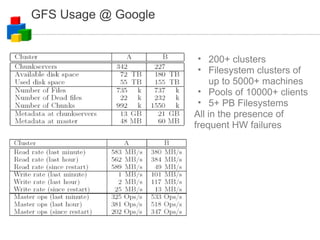
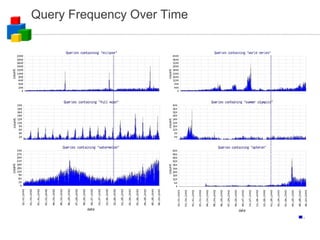
The document discusses the evolution of computing models from clusters and grids to cloud computing. It describes how cluster computing involved tightly coupled resources within a LAN, while grids allowed for resource sharing across domains. Utility computing introduced an ownership model where users leased computing power. Finally, cloud computing allows access to services and data from any internet-connected device through a browser.
















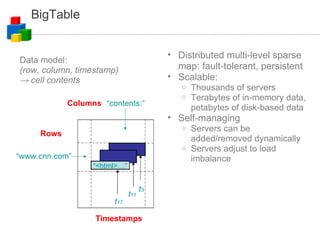

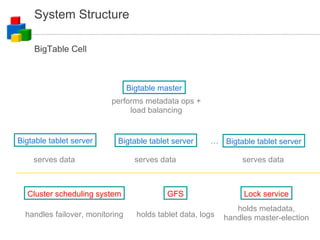
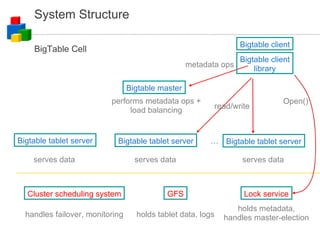
![Distributed Data Processing How do you process 1 month of apache logs to find the usage pattern numRequest[minuteOfTheWeek]? Input files: N rotated logs Size: O(TB) for popular sites – multiple physical disks Processing phase 1: launch M processes input: N/M log files output: one file of numRequest[minuteOfTheWeek] Processing phase 2: merge M output files of step 1](https://image.slidesharecdn.com/googlecloudcomputing-090804034027-phpapp01/85/Google-Cloud-Computing-on-Google-Developer-2008-Day-33-320.jpg)
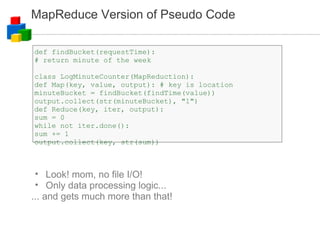
![Pseudo Codes for Phase 1 and 2 def findBucket(requestTime): # return minute of the week numRequest = zeros(1440*7) # an array of 1440*7 zeros for filename in sys.argv[2:]: for line in open(filename): minuteBucket = findBucket(findTime(line)) numRequest[minuteBucket] += 1 outFile = open(sys.argv[1], 'w') for i in range(1440*7): outFile.write("%d %d\n" % (i, numRequest[i])) outFile.close() numRequest = zeros(1440*7) # an array of 1440*7 zeros for filename in sys.argv[2:]: for line in open(filename): col = line.split() [i, count] = [int(col[0]), int(col[1])] numRequest[i] += count # write out numRequest[] like phase 1](https://image.slidesharecdn.com/googlecloudcomputing-090804034027-phpapp01/85/Google-Cloud-Computing-on-Google-Developer-2008-Day-34-320.jpg)
![MapReduce – A New Model and System Map: (in_key, in_value) ➔ { ( key j , value j ) | j = 1, ..., K } Reduce: ( key , [ value 1 , ... value L ]) ➔ ( key , f_value ) Two phases of data processing](https://image.slidesharecdn.com/googlecloudcomputing-090804034027-phpapp01/85/Google-Cloud-Computing-on-Google-Developer-2008-Day-37-320.jpg)
![MapReduce Programming Model Borrowed from functional programming map(f, [x 1 , x 2 , ...]) = [f(x 1 ), f(x 2 ), ...] reduce(f, x 0 , [x 1 , x 2 , x 3 ,...]) = reduce(f, f(x 0 , x 1 ), [x 2 ,...]) = ... (continue until the list is exausted) Users implement two functions: map (in_key, in_value) ➔ ( key j , value j ) list reduce [ value 1 , ... value L ] ➔ f_value](https://image.slidesharecdn.com/googlecloudcomputing-090804034027-phpapp01/85/Google-Cloud-Computing-on-Google-Developer-2008-Day-38-320.jpg)






























































![UNIT I -Introduction to CLOUD COMPUTING [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uniti-introductiontocloudcomputingautosaved-250128091123-f66abd14-thumbnail.jpg?width=640&height=640&fit=bounds)

