This document summarizes a student's doctoral research on runtime environments for data-intensive scalable computing. The key points are:
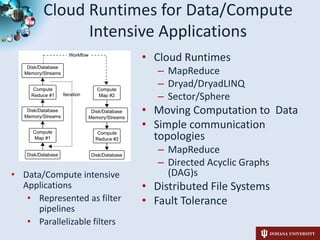
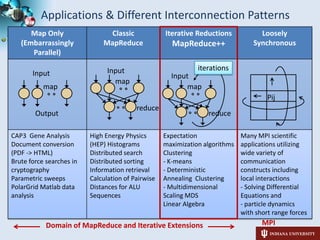
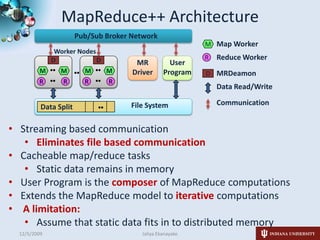
1) The student is investigating cloud runtimes like MapReduce, DryadLINQ, and i-MapReduce for data and compute-intensive applications represented as filter pipelines.
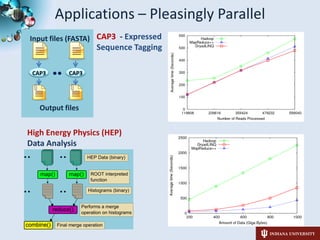
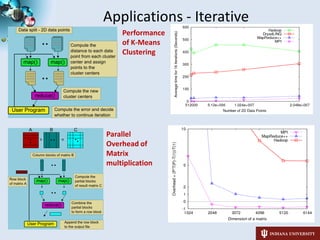
2) The student has applied these runtimes to applications in domains like genomics, phylogenetics, and high energy physics, demonstrating their ability to parallelize tasks.
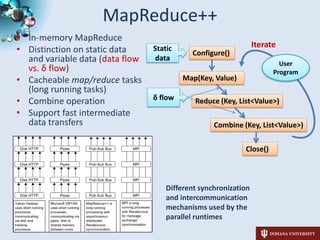
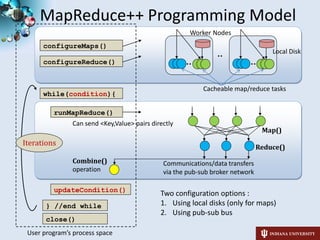
3) The student has developed i-MapReduce to support iterative MapReduce computations more efficiently than traditional MapReduce systems by caching static data in memory between iterations.
4) Current research directions include evaluating the


![Parallelizable filtersApplications using Hadoop and DryadLINQ (1)Input files (FASTA)CAP3 [1] - Expressed Sequence Tag assembly to re-construct full-length mRNACAP3CAP3CAP3DryadLINQOutput files“Map only” operation in HadoopSingle “Select” operation in DryadLINQ[1] X. Huang, A. Madan, “CAP3: A DNA Sequence Assembly Program,” Genome Research, vol. 9, no. 9, pp. 868-877, 1999.](https://image.slidesharecdn.com/sc09-doc-symposium-091205000949-phpapp01/85/Architecture-and-Performance-of-Runtime-Environments-for-Data-Intensive-Scalable-Computing-4-320.jpg)
![Applications using Hadoop and DryadLINQ (2)PhyloD [1]project from Microsoft ResearchDerive associations between HLA alleles and HIV codons and between codons themselvesDryadLINQ implementation[1] Microsoft Computational Biology Web Tools, http://research.microsoft.com/en-us/um/redmond/projects/MSCompBio/](https://image.slidesharecdn.com/sc09-doc-symposium-091205000949-phpapp01/85/Architecture-and-Performance-of-Runtime-Environments-for-Data-Intensive-Scalable-Computing-5-320.jpg)





























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)















