Downloaded 33 times





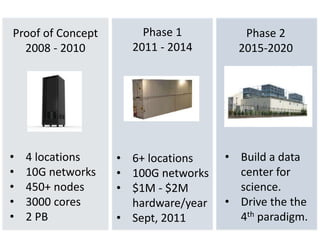

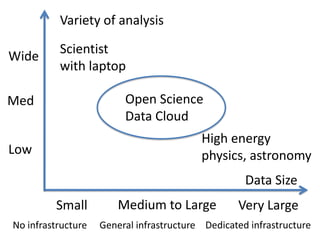





The Open Science Data Cloud (OSDC) is a project by the Open Cloud Consortium aimed at providing cloud infrastructure to support the scientific community by managing, archiving, and analyzing medium to large datasets. The project also seeks to create protocols and tools for data encapsulation, integration of new infrastructure, and long-term data preservation in cloud environments. Funding and collaborative efforts are planned from 2011 to 2020 across multiple phases to enhance scientific data access and analysis capabilities.





















































































