Downloaded 14 times









![Datacenter(s) as a computer
• Existing tools do not generalize well
– Partial failure (how many machines might fail before
the datacenter becomes non-operational? … about
50%)
– Hadoop like metrics (data locality, # of slots, heartbeat
delays)
– Installation and lifecycle management
– Heterogenious nodes
• The ultimate user wants to USE the system, not
CONFIGURE it
– let insight = [ for i in my_smart_algos -> data |> i ]
12
©2011 Cloudera, Inc. All Rights Reserved.](https://image.slidesharecdn.com/yackozlovfinal-111009081918-phpapp02/85/Cloudera-Cloudera-Inc-12-320.jpg)




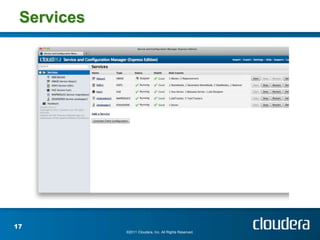
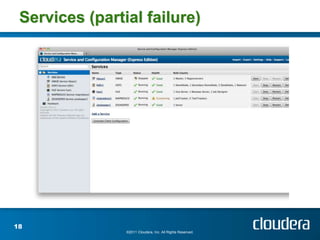







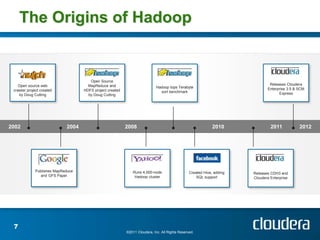
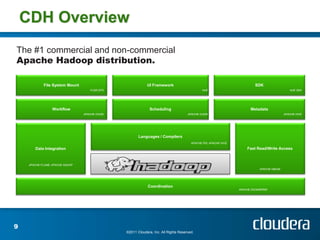
The document discusses Cloudera's tools for managing distributed systems, emphasizing the challenges of handling large data efficiently. It covers the importance of Hadoop and the need for operational support within its frameworks, particularly addressing issues of partial failures and node functionality. Cloudera aims to enhance data management and analysis through scalable platforms and innovative solutions to improve job performance diagnostics.
































































































