Downloaded 43 times






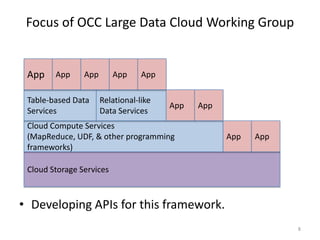



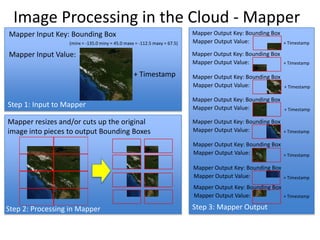
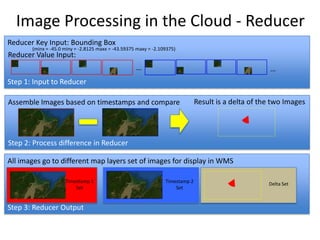








The document discusses Project Matsu, an initiative by the Open Cloud Consortium to provide cloud computing resources for large-scale image processing to assist with disaster relief. It proposes three technical approaches: 1) Using Hadoop and MapReduce to process images in parallel across nodes; 2) Using Hadoop streaming with Python to preprocess images into a single file for processing; and 3) Using the Sector distributed file system and Sphere UDFs to process images while keeping them together on nodes without splitting files. The overall goal is to enable elastic computing on petabyte-scale image datasets for change detection and other analyses to support disaster response.


























































































