Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Masahito Ohue
1,888 views
Microsoft Azure上でのタンパク質間相互作用予測システムの並列計算と性能評価
情報処理学会 第49回バイオ情報学研究会 Microsoft Azure上でのタンパク質間相互作用予測システムの並列計算と性能評価 大上 雅史(東京工業大学)
Engineering
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 13
2
/ 13
3
/ 13
4
/ 13
5
/ 13
6
/ 13
7
/ 13
8
/ 13
9
/ 13
10
/ 13
11
/ 13
12
/ 13
13
/ 13
More Related Content
PPT
Iugonet 20100816 system
by
Yukinobu Koyama
PDF
Junnosuke Mizutani Bachelor Thesis
by
pflab
PDF
OpenStack Updates
by
Masanori Itoh
PPTX
Cho Bachelor Thesis
by
pflab
PDF
Hidehito Yabuuchi Bachelor Thesis
by
pflab
PPTX
Takahashi Bachelor thesis
by
pflab
PPTX
学生からみた松江高専生とOpenStackで遊んだお話
by
Toru Komatsu
PDF
[量子コンピューター勉強会資料] マヨラナ粒子によるスケーラブルな量子コンピューターの設計
by
Takayoshi Tanaka
Iugonet 20100816 system
by
Yukinobu Koyama
Junnosuke Mizutani Bachelor Thesis
by
pflab
OpenStack Updates
by
Masanori Itoh
Cho Bachelor Thesis
by
pflab
Hidehito Yabuuchi Bachelor Thesis
by
pflab
Takahashi Bachelor thesis
by
pflab
学生からみた松江高専生とOpenStackで遊んだお話
by
Toru Komatsu
[量子コンピューター勉強会資料] マヨラナ粒子によるスケーラブルな量子コンピューターの設計
by
Takayoshi Tanaka
What's hot
PDF
自作プライベートクラウド研究会 OpenStackアップデート
by
Masanori Itoh
PDF
Awamoto master thesis
by
pflab
PPTX
[DL Hacks] Objects as Points
by
Deep Learning JP
PDF
OpenStack Summit Vancouver 2018 Nova最新動向
by
Takashi Natsume
PDF
WebDB Forum 2016 gunosy
by
Hiroaki Kudo
PPT
Iugonet 20100916
by
Yukinobu Koyama
PDF
Osc2012 TokyoSpring OpenStack Abstract
by
Ayumi Oka
PDF
MateriApps: OpenMXを利用した第一原理計算の簡単な実習
by
Computational Materials Science Initiative
PPTX
バッチ高速化のあゆみ
by
dcubeio
PDF
OpenStack概要(オープンクラウド最新動向)
by
Akira Yoshiyama
PDF
Jubakit の紹介
by
kmaehashi
PDF
Ubuntu Offline Meeting 2013.05 Tokyo
by
Masanori Itoh
PPTX
輪読資料 Xception: Deep Learning with Depthwise Separable Convolutions
by
Kotaro Asami
PPTX
“速度情報を組み込んだロードマップの提案 ”を読んで
by
Adachi (OEI)
PDF
OpenStack Abstract @osc2012kyoto
by
Ayumi Oka
PDF
SIGMOD'10勉強会 -Session 8-
by
Takeshi Yamamuro
PDF
Jubaanomalyについて
by
JubatusOfficial
PPTX
Jubatus 1.0 の紹介
by
JubatusOfficial
PDF
RDOで体験! OpenStackの基本機能
by
Etsuji Nakai
PPTX
ChainerMNについて
by
Shuji Suzuki
自作プライベートクラウド研究会 OpenStackアップデート
by
Masanori Itoh
Awamoto master thesis
by
pflab
[DL Hacks] Objects as Points
by
Deep Learning JP
OpenStack Summit Vancouver 2018 Nova最新動向
by
Takashi Natsume
WebDB Forum 2016 gunosy
by
Hiroaki Kudo
Iugonet 20100916
by
Yukinobu Koyama
Osc2012 TokyoSpring OpenStack Abstract
by
Ayumi Oka
MateriApps: OpenMXを利用した第一原理計算の簡単な実習
by
Computational Materials Science Initiative
バッチ高速化のあゆみ
by
dcubeio
OpenStack概要(オープンクラウド最新動向)
by
Akira Yoshiyama
Jubakit の紹介
by
kmaehashi
Ubuntu Offline Meeting 2013.05 Tokyo
by
Masanori Itoh
輪読資料 Xception: Deep Learning with Depthwise Separable Convolutions
by
Kotaro Asami
“速度情報を組み込んだロードマップの提案 ”を読んで
by
Adachi (OEI)
OpenStack Abstract @osc2012kyoto
by
Ayumi Oka
SIGMOD'10勉強会 -Session 8-
by
Takeshi Yamamuro
Jubaanomalyについて
by
JubatusOfficial
Jubatus 1.0 の紹介
by
JubatusOfficial
RDOで体験! OpenStackの基本機能
by
Etsuji Nakai
ChainerMNについて
by
Shuji Suzuki
Viewers also liked
PDF
学振特別研究員になるために~2018年度申請版
by
Masahito Ohue
PDF
目バーチャルスクリーニング
by
Masahito Ohue
PDF
学振特別研究員になるために~知っておくべき10のTips~
by
Masahito Ohue
PDF
学振特別研究員になるために~知っておくべき10のTips~[平成29年度申請版]
by
Masahito Ohue
PDF
計算で明らかにするタンパク質の出会いとネットワーク(FIT2016 助教が吼えるセッション)
by
Masahito Ohue
PDF
Sistema educativo indígena propio seip La Guajira
by
Mauricio Enrique Ramirez Alvarez
PDF
Wielding the Hard and Soft Science of Service Design
by
brandonschauer
PPS
Eva Peron Evita,Libro De Lectura Para 1er Grado Inferior
by
cristiandadypatria
PDF
Influence of Magnetic Flux Controllers on Induction Heating Systems
by
Fluxtrol Inc.
PPTX
Deep Learning による視覚×言語融合の最前線
by
Yoshitaka Ushiku
PPTX
Portrait of a lady
by
Makala (D)
PPTX
結果を出すチームビルディング術
by
Mao Ohnishi
PPTX
HPC Top 5 Stories: March 22, 2017
by
NVIDIA
PDF
Pythonの処理系はどのように実装され,どのように動いているのか? 我々はその実態を調査すべくアマゾンへと飛んだ.
by
kiki utagawa
PPT
Problemas De La Globalización
by
Mpps :)
PDF
見やすいプレゼン資料の作り方 - リニューアル増量版
by
MOCKS | Yuta Morishige
PPTX
Payments Trends 2017
by
Capgemini
PDF
Infographic: Medicare Marketing: Direct Mail: Still The #1 Influencer For Tho...
by
Scott Levine
PDF
The Marketer's Guide To Customer Interviews
by
Good Funnel
PDF
The Be-All, End-All List of Small Business Tax Deductions
by
Wagepoint
学振特別研究員になるために~2018年度申請版
by
Masahito Ohue
目バーチャルスクリーニング
by
Masahito Ohue
学振特別研究員になるために~知っておくべき10のTips~
by
Masahito Ohue
学振特別研究員になるために~知っておくべき10のTips~[平成29年度申請版]
by
Masahito Ohue
計算で明らかにするタンパク質の出会いとネットワーク(FIT2016 助教が吼えるセッション)
by
Masahito Ohue
Sistema educativo indígena propio seip La Guajira
by
Mauricio Enrique Ramirez Alvarez
Wielding the Hard and Soft Science of Service Design
by
brandonschauer
Eva Peron Evita,Libro De Lectura Para 1er Grado Inferior
by
cristiandadypatria
Influence of Magnetic Flux Controllers on Induction Heating Systems
by
Fluxtrol Inc.
Deep Learning による視覚×言語融合の最前線
by
Yoshitaka Ushiku
Portrait of a lady
by
Makala (D)
結果を出すチームビルディング術
by
Mao Ohnishi
HPC Top 5 Stories: March 22, 2017
by
NVIDIA
Pythonの処理系はどのように実装され,どのように動いているのか? 我々はその実態を調査すべくアマゾンへと飛んだ.
by
kiki utagawa
Problemas De La Globalización
by
Mpps :)
見やすいプレゼン資料の作り方 - リニューアル増量版
by
MOCKS | Yuta Morishige
Payments Trends 2017
by
Capgemini
Infographic: Medicare Marketing: Direct Mail: Still The #1 Influencer For Tho...
by
Scott Levine
The Marketer's Guide To Customer Interviews
by
Good Funnel
The Be-All, End-All List of Small Business Tax Deductions
by
Wagepoint
Similar to Microsoft Azure上でのタンパク質間相互作用予測システムの並列計算と性能評価
PDF
[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する
by
DNA Data Bank of Japan center
PDF
汎用グラフ処理モデルGIM-Vの複数GPUによる大規模計算とデータ転送の最適化
by
Koichi Shirahata
PPTX
2012 1203-researchers-cafe
by
Toshiya Komoda
PDF
SIGBIO54: 生命情報解析分野におけるコンテナ型仮想化技術の動向と性能検証
by
Kento Aoyama
PDF
深層学習向け計算機クラスター MN-3
by
Preferred Networks
PDF
2012-03-08 MSS研究会
by
Kimikazu Kato
PDF
20180227_最先端のディープラーニング 研究開発を支えるGPU計算機基盤 「MN-1」のご紹介
by
Preferred Networks
PDF
M08_あなたの知らない Azure インフラの世界 [Microsoft Japan Digital Days]
by
日本マイクロソフト株式会社
PDF
PCCC22:日本マイクロソフト株式会社 テーマ2「HPC on Azureのお客様事例」03
by
PC Cluster Consortium
PDF
エンジニアリング領域における KEL シンクライアントソリューションのご紹介
by
Dell TechCenter Japan
PDF
MII conference177 nvidia
by
Tak Izaki
PDF
Deep Learning Lab MeetUp 学習編 AzureインフラとBatch AI
by
喜智 大井
PDF
Protein-protein docking-based virtual screening
by
Masahito Ohue
PDF
PCCC22:日本マイクロソフト株式会社 テーマ1「HPC on Microsoft Azure」
by
PC Cluster Consortium
PPT
遊休リソースを用いた 相同性検索処理の並列化とその評価
by
Satoshi Nagayasu
PDF
第1回 配信講義 計算科学技術特論A (2021)
by
RCCSRENKEI
PDF
20160527_07_IoT勉強会 分析WG 配布用
by
IoTビジネス共創ラボ
[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する
by
DNA Data Bank of Japan center
汎用グラフ処理モデルGIM-Vの複数GPUによる大規模計算とデータ転送の最適化
by
Koichi Shirahata
2012 1203-researchers-cafe
by
Toshiya Komoda
SIGBIO54: 生命情報解析分野におけるコンテナ型仮想化技術の動向と性能検証
by
Kento Aoyama
深層学習向け計算機クラスター MN-3
by
Preferred Networks
2012-03-08 MSS研究会
by
Kimikazu Kato
20180227_最先端のディープラーニング 研究開発を支えるGPU計算機基盤 「MN-1」のご紹介
by
Preferred Networks
M08_あなたの知らない Azure インフラの世界 [Microsoft Japan Digital Days]
by
日本マイクロソフト株式会社
PCCC22:日本マイクロソフト株式会社 テーマ2「HPC on Azureのお客様事例」03
by
PC Cluster Consortium
エンジニアリング領域における KEL シンクライアントソリューションのご紹介
by
Dell TechCenter Japan
MII conference177 nvidia
by
Tak Izaki
Deep Learning Lab MeetUp 学習編 AzureインフラとBatch AI
by
喜智 大井
Protein-protein docking-based virtual screening
by
Masahito Ohue
PCCC22:日本マイクロソフト株式会社 テーマ1「HPC on Microsoft Azure」
by
PC Cluster Consortium
遊休リソースを用いた 相同性検索処理の並列化とその評価
by
Satoshi Nagayasu
第1回 配信講義 計算科学技術特論A (2021)
by
RCCSRENKEI
20160527_07_IoT勉強会 分析WG 配布用
by
IoTビジネス共創ラボ
More from Masahito Ohue
PDF
学振特別研究員になるために~2024年度申請版
by
Masahito Ohue
PDF
学振特別研究員になるために~2023年度申請版
by
Masahito Ohue
PDF
学振特別研究員になるために~2022年度申請版
by
Masahito Ohue
PDF
第43回分子生物学会年会フォーラム2F-11「インシリコ創薬を支える最先端情報科学」から抜粋したAlphaFold2の話
by
Masahito Ohue
PDF
Learning-to-rank for ligand-based virtual screening
by
Masahito Ohue
PDF
Parallelized pipeline for whole genome shotgun metagenomics with GHOSTZ-GPU a...
by
Masahito Ohue
PDF
Molecular Activity Prediction Using Graph Convolutional Deep Neural Network C...
by
Masahito Ohue
PDF
学振特別研究員になるために~2020年度申請版
by
Masahito Ohue
PPTX
出会い系タンパク質を探す旅
by
Masahito Ohue
PDF
学振特別研究員になるために~2019年度申請版
by
Masahito Ohue
PPTX
Link Mining for Kernel-based Compound-Protein Interaction Predictions Using a...
by
Masahito Ohue
PDF
Finding correct protein–protein docking models using ProQDock (ISMB2016読み会, 大上)
by
Masahito Ohue
PPTX
ISMB/ECCB2015読み会:大上
by
Masahito Ohue
PDF
学振特別研究員になるために~知っておくべき10のTips~[平成28年度申請版]
by
Masahito Ohue
PDF
IIBMP2014 Lightning Talk - MEGADOCK 4.0
by
Masahito Ohue
PPTX
PrePPI: structure-based protein-protein interaction prediction
by
Masahito Ohue
PDF
Protein-Protein Interaction Prediction Based on Template-Based and de Novo Do...
by
Masahito Ohue
PDF
PRML Chapter 14
by
Masahito Ohue
PPTX
W8PRML5.1-5.3
by
Masahito Ohue
PDF
Accurate protein-protein docking with rapid calculation
by
Masahito Ohue
学振特別研究員になるために~2024年度申請版
by
Masahito Ohue
学振特別研究員になるために~2023年度申請版
by
Masahito Ohue
学振特別研究員になるために~2022年度申請版
by
Masahito Ohue
第43回分子生物学会年会フォーラム2F-11「インシリコ創薬を支える最先端情報科学」から抜粋したAlphaFold2の話
by
Masahito Ohue
Learning-to-rank for ligand-based virtual screening
by
Masahito Ohue
Parallelized pipeline for whole genome shotgun metagenomics with GHOSTZ-GPU a...
by
Masahito Ohue
Molecular Activity Prediction Using Graph Convolutional Deep Neural Network C...
by
Masahito Ohue
学振特別研究員になるために~2020年度申請版
by
Masahito Ohue
出会い系タンパク質を探す旅
by
Masahito Ohue
学振特別研究員になるために~2019年度申請版
by
Masahito Ohue
Link Mining for Kernel-based Compound-Protein Interaction Predictions Using a...
by
Masahito Ohue
Finding correct protein–protein docking models using ProQDock (ISMB2016読み会, 大上)
by
Masahito Ohue
ISMB/ECCB2015読み会:大上
by
Masahito Ohue
学振特別研究員になるために~知っておくべき10のTips~[平成28年度申請版]
by
Masahito Ohue
IIBMP2014 Lightning Talk - MEGADOCK 4.0
by
Masahito Ohue
PrePPI: structure-based protein-protein interaction prediction
by
Masahito Ohue
Protein-Protein Interaction Prediction Based on Template-Based and de Novo Do...
by
Masahito Ohue
PRML Chapter 14
by
Masahito Ohue
W8PRML5.1-5.3
by
Masahito Ohue
Accurate protein-protein docking with rapid calculation
by
Masahito Ohue
Microsoft Azure上でのタンパク質間相互作用予測システムの並列計算と性能評価
1.
Microsoft Azure上でのタンパク質間相互作用 予測システムの並列計算と性能評価 1 東京工業大学
情報理工学院 情報工学系 2 東京工業大学 情報生命博士教育院 情報処理学会 第49回バイオ情報学研究会 (4) 2017年3月23日(木) 於 北陸先端科学技術大学院大学 大上 雅史1 山本 悠生1,2 秋山 泰1,2
2.
• パブリッククラウド – 利点 •
利用料金を払えば誰でも利用可能、運用はアウトソース • 環境や資源を共有するしくみが充実 • 計算資源の増減が簡単 パブリッククラウドの普及 2017/3/23 49 (4)第 回バイオ情報学研究会 大上雅史 2
3.
パブリッククラウド上での並列計算の例 2017/3/23 49 (4)第
回バイオ情報学研究会 大上雅史 • タンパク質の類似構造検索タスク。 • Searcher role 6台まで、ほぼリニアに高速化。 • Searcher role 8台超で性能低下するも、 18台でも約89%の効率。 Searcher roleの数 Speedup Mrozek D, et al. Cloud4Psi: cloud computing for 3D protein structure similarity searching. Bioinformatics 2014, 30: 2822-2825. Fig. 1 Fig. 2(a) 3 仮想マシン (VM)
4.
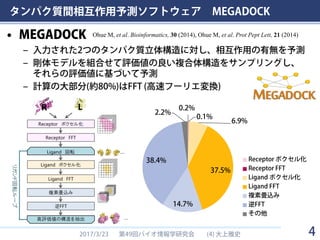
タンパク質間相互作用予測ソフトウェア MEGADOCK • MEGADOCK –
入力された2つのタンパク質立体構造に対し、相互作用の有無を予測 – 剛体モデルを組合せて評価値の良い複合体構造をサンプリングし、 それらの評価値に基づいて予測 – 計算の大部分(約80%)はFFT (高速フーリエ変換) 2017/3/23 49 (4)第 回バイオ情報学研究会 大上雅史 0.2% 0.1% 6.9% 37.5% 14.7% 38.4% 2.2% Receptor ボクセル化 Receptor FFT Ligand ボクセル化 Ligand FFT 複素畳込み 逆FFT その他 4 Ohue M, et al. Bioinformatics, 30 (2014), Ohue M, et al. Prot Pept Lett, 21 (2014)
5.
MEGADOCKのコアの部分 2017/3/23 49 (4)第
回バイオ情報学研究会 大上雅史 タンパク質が結合したときの評価値を高速に評価 5 Katzhalski-Katzir E, et al. Proc Natl Acad Sci (1992), 89(6): 2195–2199.
6.
本研究の目的 • Microsoft Azure上でMEGADOCKの並列計算を実施 –
Azure上の複数のVMを用い、MPIによって計算を並列実行 – 数十VM規模での性能を計測 – 特に、GPU付きVMに注目 2017/3/23 49 (4)第 回バイオ情報学研究会 大上雅史 6 Instance CPU GPU(*) RAM Network 価格 NC24 24コア Tesla K80 x 4 1,440 GB 440.65円/h NC24r 24コア Tesla K80 x 4 1,440 GB RDMA (InfiniBand) 484.71円/h DS14 16コア なし 112 GB 141.48円/h A9 16コア なし 112 GB RDMA (InfiniBand) 197.06円/h H16 16コア なし 112 GB 178.50円/h H16r 16コア なし 112 GB RDMA (InfiniBand) 195.84円/h Azureの代表的なインスタンス(VMの種類) (*)ただし、物理的にはK80が2枚。 (K80は1枚の中に2つのGPUチップを含む)
7.
• MEGADOCKは既にGPUクラスタ向け並列化が実装済 – プロセス単位でMasterとWorkerに資源を割り当て –
Masterがタンパク質ペアをWorkerに渡し、Workerが計算 – GPUはWorkerが使用 マルチGPUノード並列 2017/3/23 49 (4)第 回バイオ情報学研究会 大上雅史 Ohue M, Shimoda T, Suzuki S, Ishida T, Akiyama Y. Bioinformatics, 30(22): 2014. 7
8.
Azureへの実装 2017/3/23 49 (4)第
回バイオ情報学研究会 大上雅史 Azure上のシステム構成 概要 • Masterプロセス(1つ)が タンパク質ペアをWorkerに割り当て。 • 各VMのWorkerプロセスが 割り当てられたペアの予測計算を実施。 8
9.
並列化粒度 2017/3/23 49 (4)第
回バイオ情報学研究会 大上雅史 VM 1 VM 2 VM 3 VM n 9 • プロセス並列とスレッド並列の粒度を決める – これまでのクラスタ上での実装の場合、 主にメモリ制限のため、各ノード・1プロセスとしていた。 – 最近のクラウドのVMはメモリが豊富。 – (今回対象の)GPUインスタンスはGPUチップが4枚/VM → 本研究では、各VM 4プロセスずつ割り当てた。
10.
評価実験 • データセット – ZDOCK
Docking Benchmark 1.0 の 59タンパク質ペアの相手を入れ替えた全組み合わせ → 59×59 = 3,481件の予測計算 • 使用インスタンス • VM内の実行プロセス – 各VMに4プロセス – Masterを1つ立てる – Worker: 6 CPUコア+1 GPU 2017/3/23 49 (4)第 回バイオ情報学研究会 大上雅史 Instance CPU GPU(*) RAM Network 価格 NC24 24コア Tesla K80 x 4 1,440 GB 440.65円/h NC24r 24コア Tesla K80 x 4 1,440 GB RDMA (InfiniBand) 484.71円/h (Chen R, Proteins 47, 2002) (*)ただし、物理的にはK80が2枚。 (K80は1枚の中に2つのGPUチップを含む) 10
11.
GPUインスタンスでの測定結果 2017/3/23 49 (4)第
回バイオ情報学研究会 大上雅史 0 50 100 150 200 250 300 350 Speedup(#pair/min) NC24r 測定値 NC24 測定値 0 5 10 15 20 25 0 120 240 360 480 600 0 20 40 60 80 100 #Virtual Machines #CPU cores #Tesla K80 GPUs NC24 CPUのみ NC24r CPUのみ ● ● 3.8倍の高速化 Strong scaling = 89% (対#VM=5値) #VM=22 #VM=20 #VM=10 #VM=5 (NC24 CPU→GPU) 11 ※マイクロソフトのクオータコア制限のため、最大22VMまで測定。 ・89%の並列化効率(強スケーリング)を達成 ・GPUを使わずに計算した場合に比べて3.8倍高速
12.
GPUの効果 • GPUインスタンスの費用対効果 2017/3/23 49
(4)第 回バイオ情報学研究会 大上雅史 Instance CPU GPU Network 価格 NC24 E5-2690v3 24コア Tesla K80 x 4 440.65円/h NC24r E5-2690v3 24コア Tesla K80 x 4 RDMA (InfiniBand) 484.71円/h A9 E5-2670 16コア なし RDMA (InfiniBand) 197.06円/h NC24rとA9を比較 ・A9を1.5倍して、24コア→295.59円/hと見積もり。 ・NC24r 484.71円/h ÷ 295.59円/h ≒ 1.64 →GPUによる高速化率が1.64倍以上ならば、GPUインスタンスが 得。 今回の場合、GPU利用時で3.8倍高速だったので、 MEGADOCKにおいてはGPUインスタンスの利用が推奨される。 12
13.
まとめ • MEGADOCKをAzure上に移植、AzureのGPUインスタンス を用いた並列実行を実施し、その性能を評価した。 – 89%の並列化効率
(NC24, 5 VM → 22 VM) – GPUによる3.8倍の高速化 (NC24, CPU → CPU+GPU) – InfiniBandはMEGADOCKの計算にはほとんど寄与しない – クオータコア制限が41 VMまで緩和されたので、今後測定を実施 – コンテナ型仮想化技術を用いた場合の検証も今後の課題 • 謝辞 – JSPS科研費 (24240044, 15K16081) – JST CREST (Extreme Big Dataプロジェクト) – JSTリサーチコンプレックス推進プログラム 川崎市殿町拠点 – Microsoft Business Investment Funding – ㈱リバネス 第30回リバネス研究費 (日本マイクロソフト賞) 2017/3/23 49 (4)第 回バイオ情報学研究会 大上雅史 13 (3) 15:50-16:15 コンテナ型仮想化による分散計算環境におけるタンパク質間相互作用予測システムの性能評価 青山 健人、山本 悠生、大上 雅史、秋山 泰
Download




















![[量子コンピューター勉強会資料] マヨラナ粒子によるスケーラブルな量子コンピューターの設計](https://cdn.slidesharecdn.com/ss_thumbnails/20180315microsoftquantumdevice-180317073848-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL Hacks] Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/centernetpub-190627053219-thumbnail.jpg?width=640&height=640&fit=bounds)




















![学振特別研究員になるために~知っておくべき10のTips~[平成29年度申請版]](https://cdn.slidesharecdn.com/ss_thumbnails/10tips29-160403152412-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する](https://cdn.slidesharecdn.com/ss_thumbnails/31ddbjingohta-150626022623-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)






![M08_あなたの知らない Azure インフラの世界 [Microsoft Japan Digital Days]](https://cdn.slidesharecdn.com/ss_thumbnails/m08azure-211027131016-thumbnail.jpg?width=640&height=640&fit=bounds)






















![学振特別研究員になるために~知っておくべき10のTips~[平成28年度申請版]](https://cdn.slidesharecdn.com/ss_thumbnails/random-150226210930-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)





