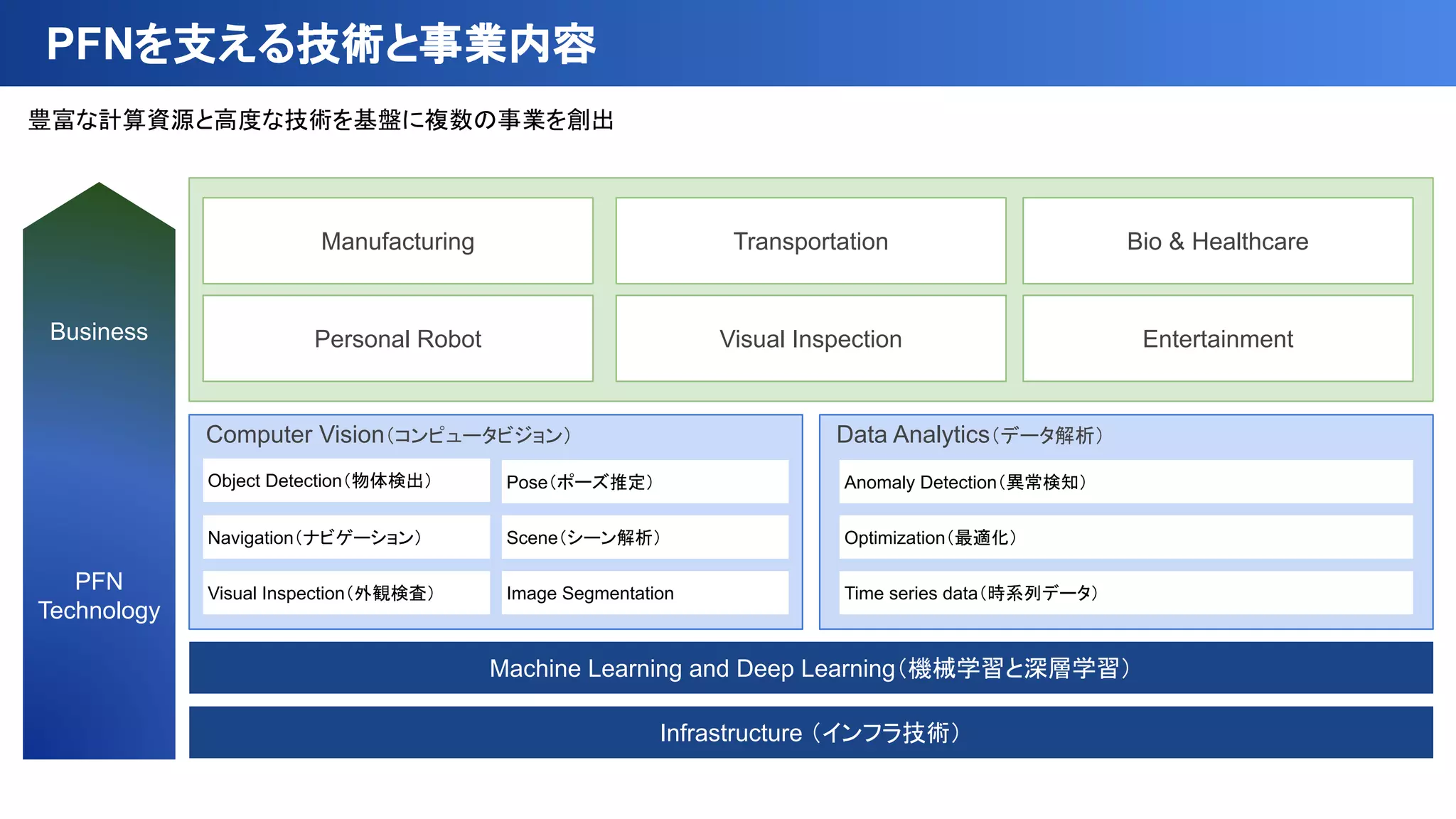
豊富な計算資源と高度な技術を基盤に複数の事業を創出
PFNを支える技術と事業内容
Computer Vision(コンピュータビジョン) DataAnalytics(データ解析)
Navigation(ナビゲーション)
Visual Inspection(外観検査)
Pose(ポーズ推定)
Scene(シーン解析)
Image Segmentation
Anomaly Detection(異常検知)
Optimization(最適化)
Time series data(時系列データ)
Infrastructure (インフラ技術)
Machine Learning and Deep Learning(機械学習と深層学習)
Manufacturing Transportation Bio & Healthcare
Personal Robot Visual Inspection Entertainment
PFN
Technology
Business
Object Detection(物体検出)
Accelerator for deeplearning
4-die package / 500W max
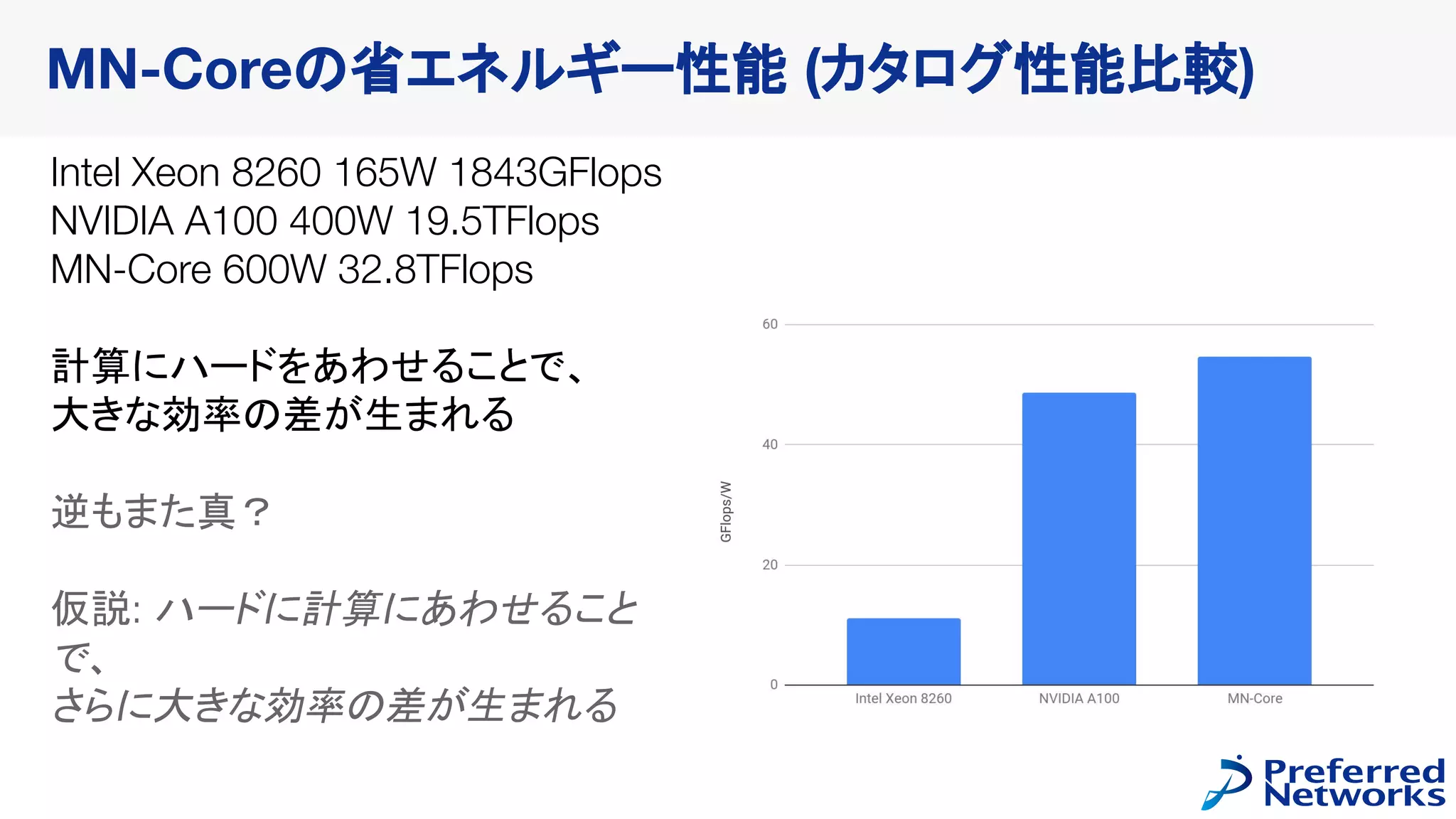
Design peak performance and performance per watt:
● DP: 32.8 Tops / 0.066 Tops/W
● SP: 131 Tops / 0.26 Tops/W
● HP: 524 Tops / 1 Tops/W
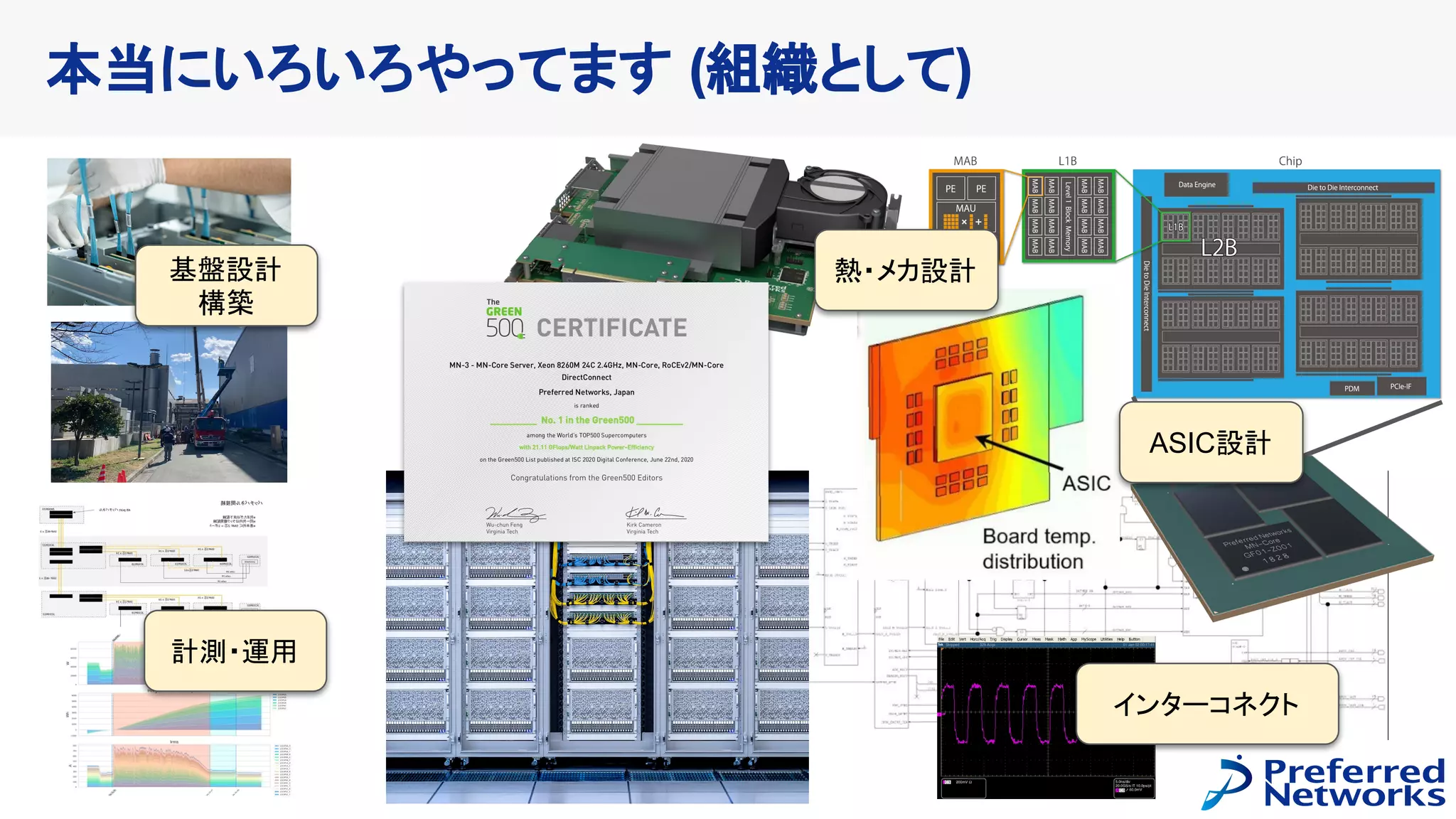
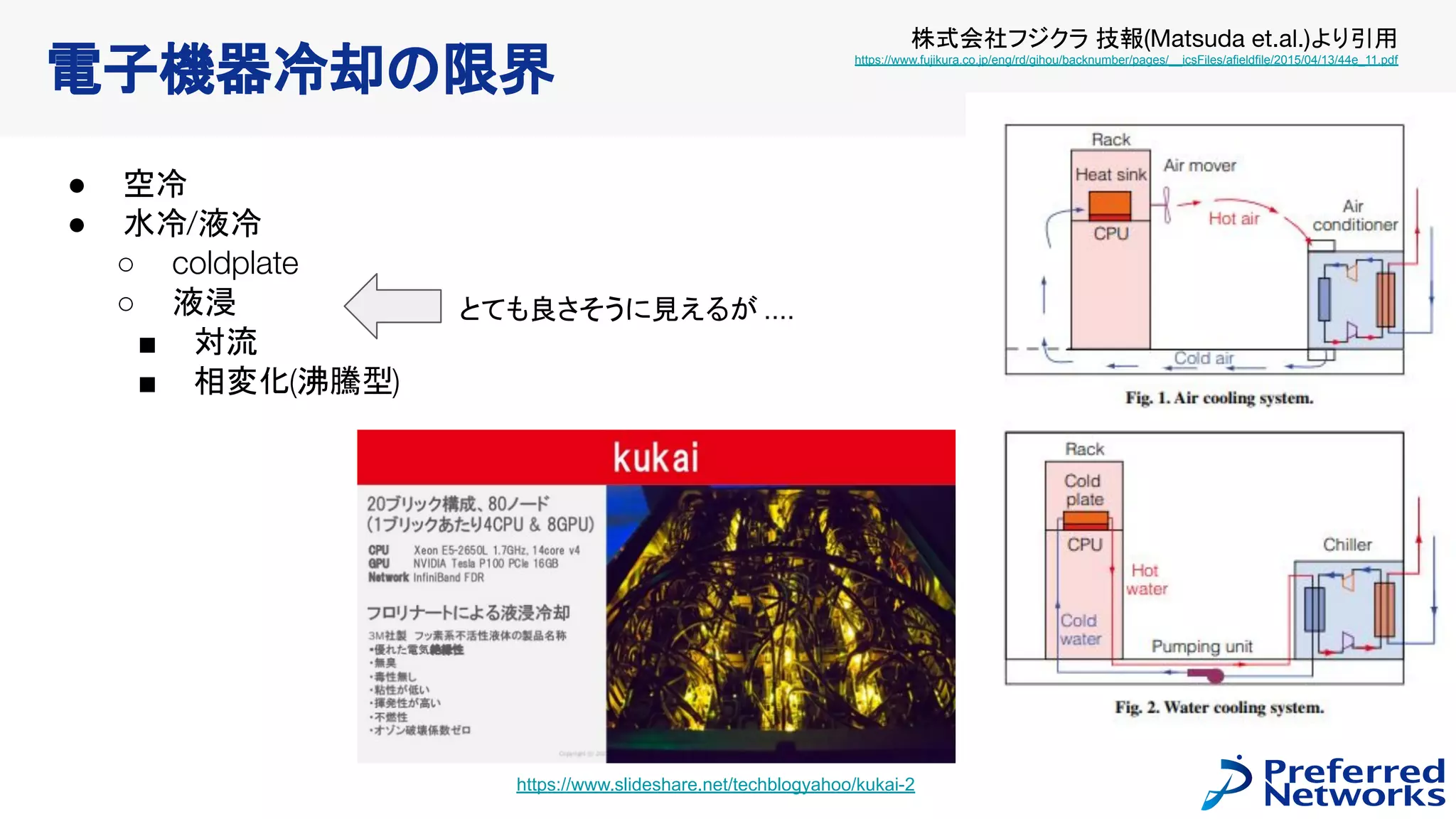
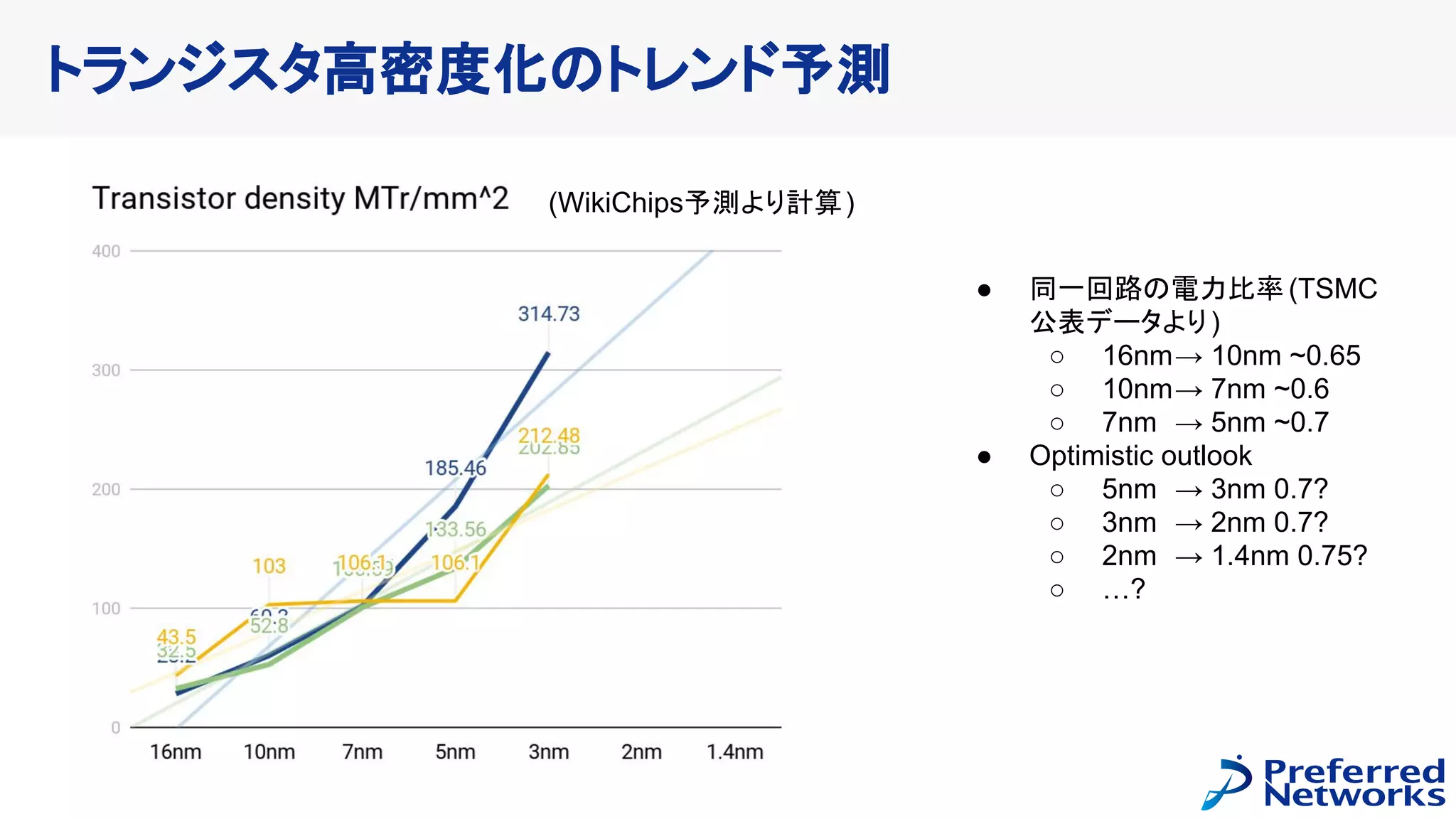
計算力の自前調達に向けて
In collaboration with Prof. Makino (Kobe-U) with his team
members, and Prof. Hiraki (U-Tokyo, now he is with PFN),
Giant SIMD Processor
●Single instruction stream
● Hierarchical structure with unique on-chip
network (broadcast, aggregation, etc)
● Large SRAM to accommodate weights and
filters in-place
○ programmers can/shall control EVERY memory
copy explicitly (no implicit cache)
○ Easier to predict the performance
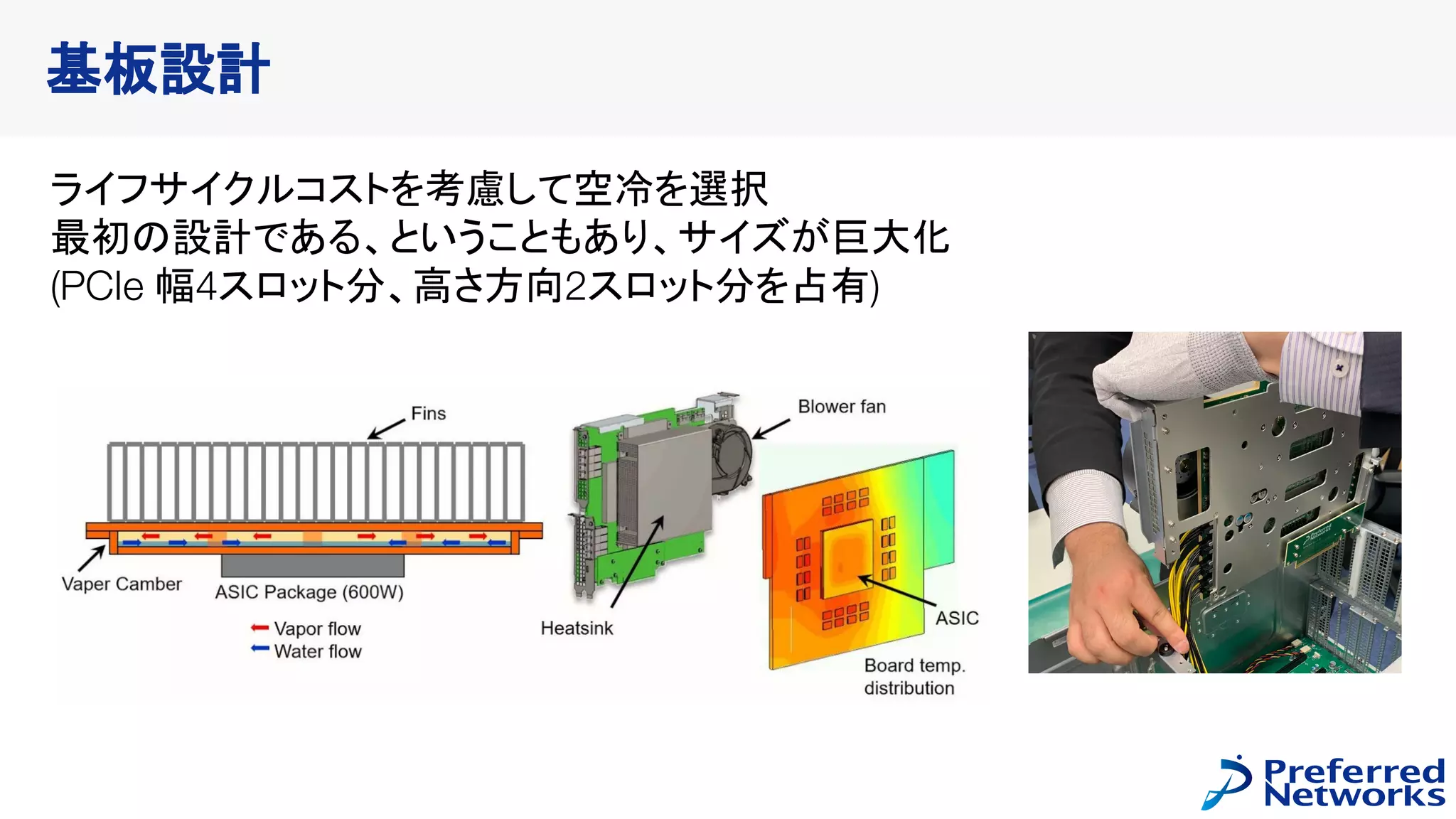
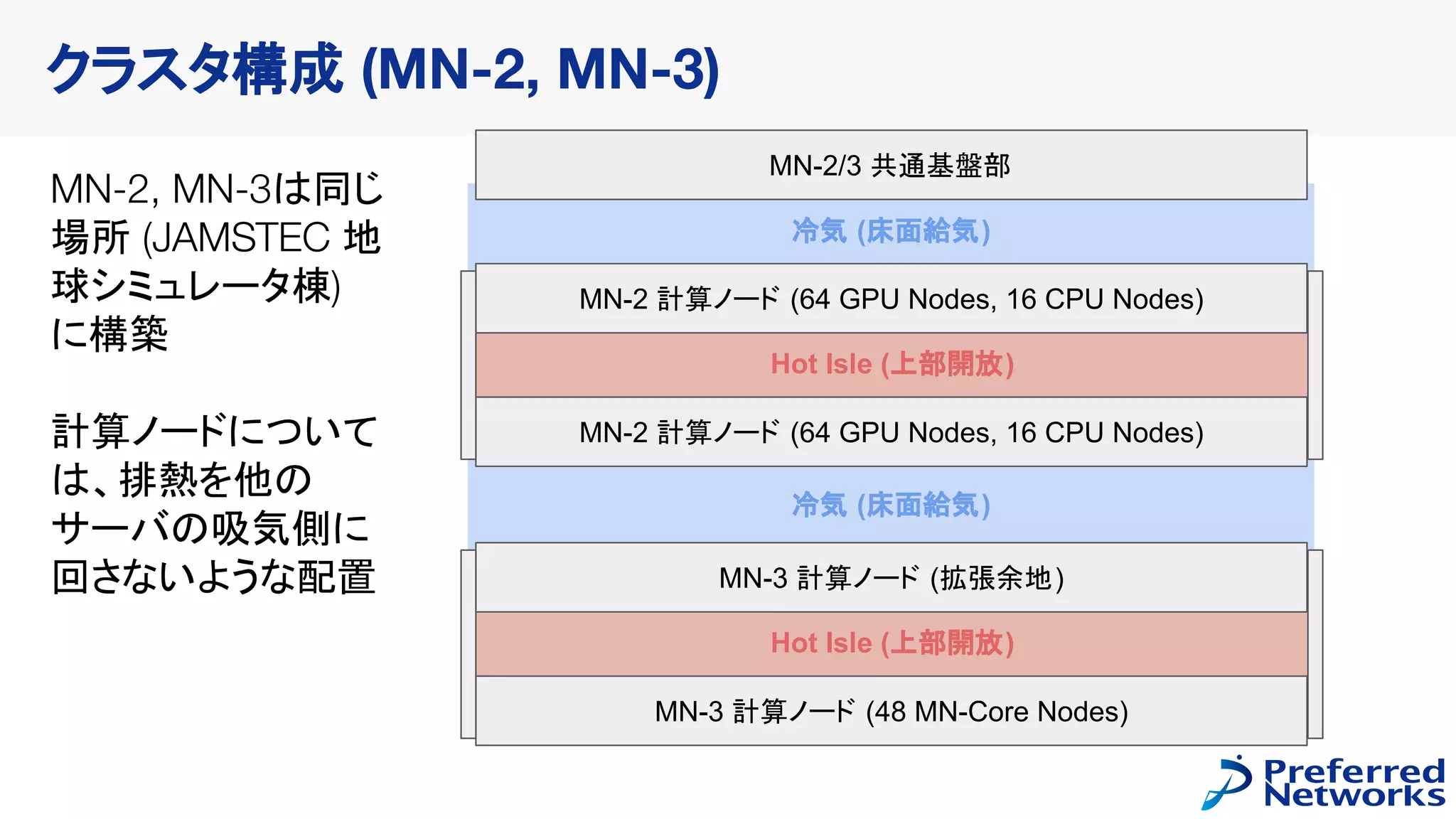
MN-Coreの概要
Philosophy behind MN-CoreHardware (a.k.a. “Makino-ism”)
● とにかく削ぎ落として演算器を詰め込む
Push floating-point operation unit as much as possible
● 不便?柔軟性?そこはソフトで頑張ってよ
Inconvenient? Good luck, software team...
https://xtech.nikkei.com/atcl/nxt/column/18/00589/020900002/
Prof. Makino
(Kobe Univ.)
MN-Coreの思想: 計算に必要な回路のみを実装する
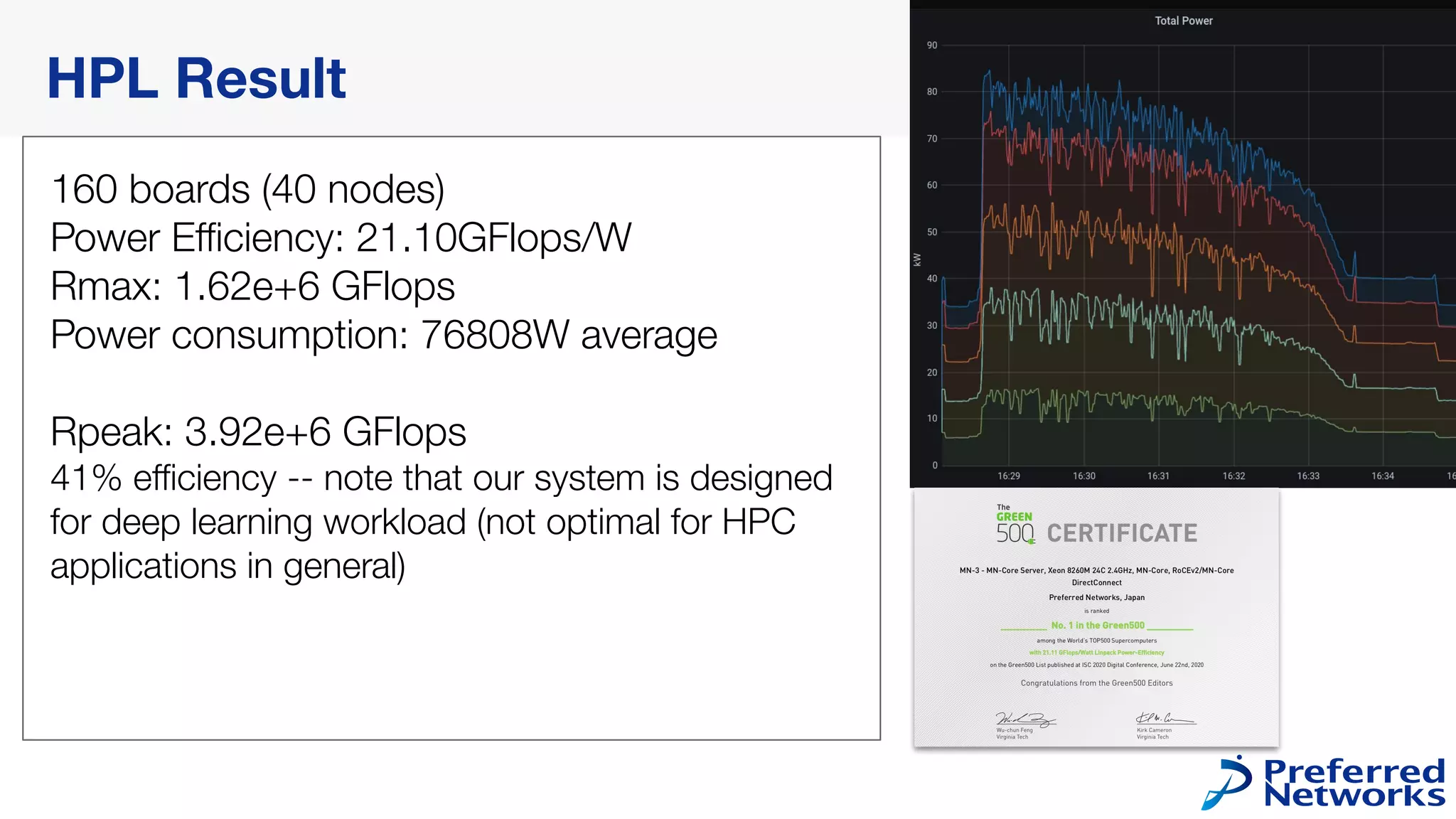
160 boards (40nodes)
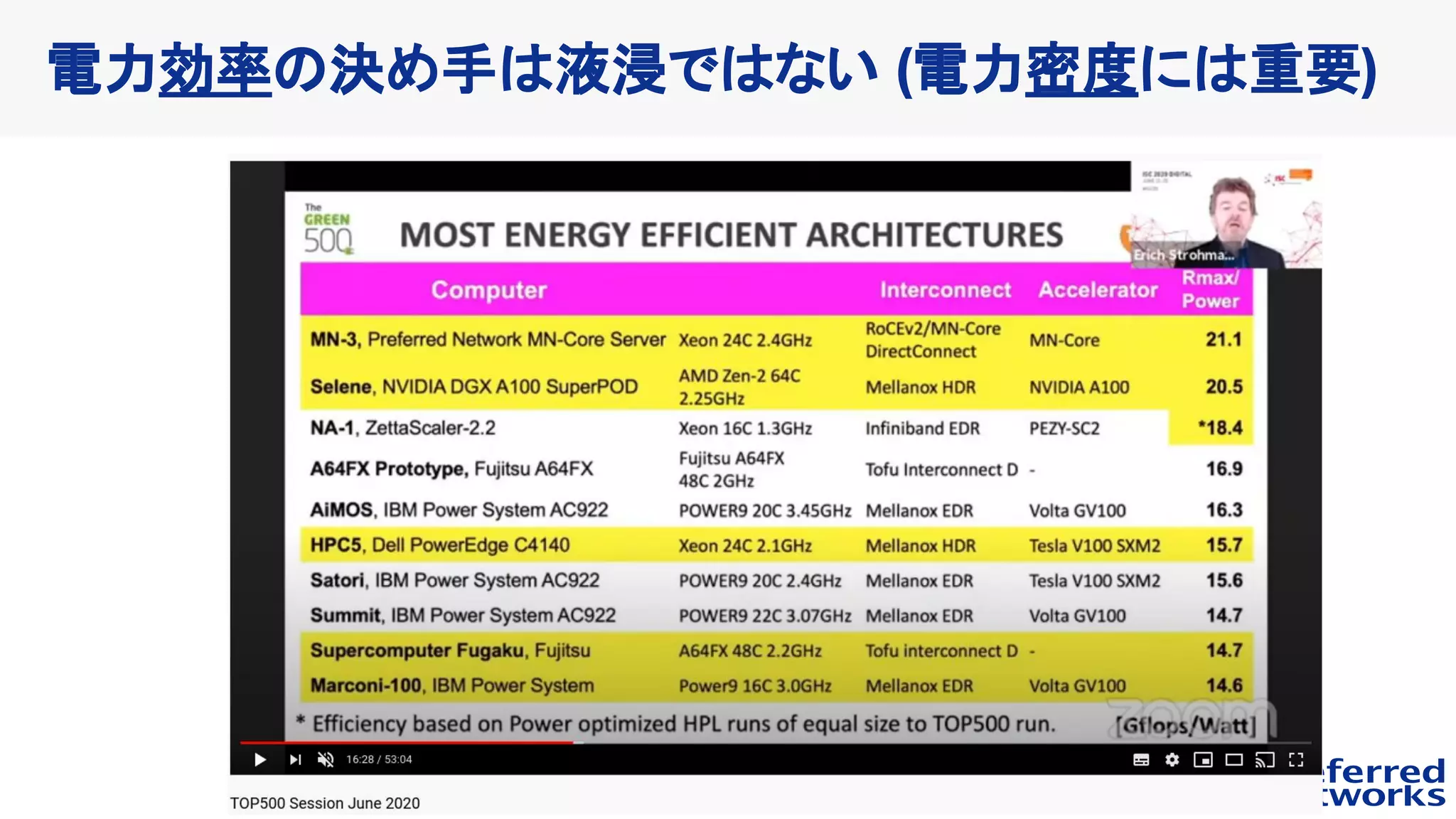
Power Efficiency: 21.10GFlops/W
Rmax: 1.62e+6 GFlops
Power consumption: 76808W average
Rpeak: 3.92e+6 GFlops
41% efficiency -- note that our system is designed
for deep learning workload (not optimal for HPC
applications in general)
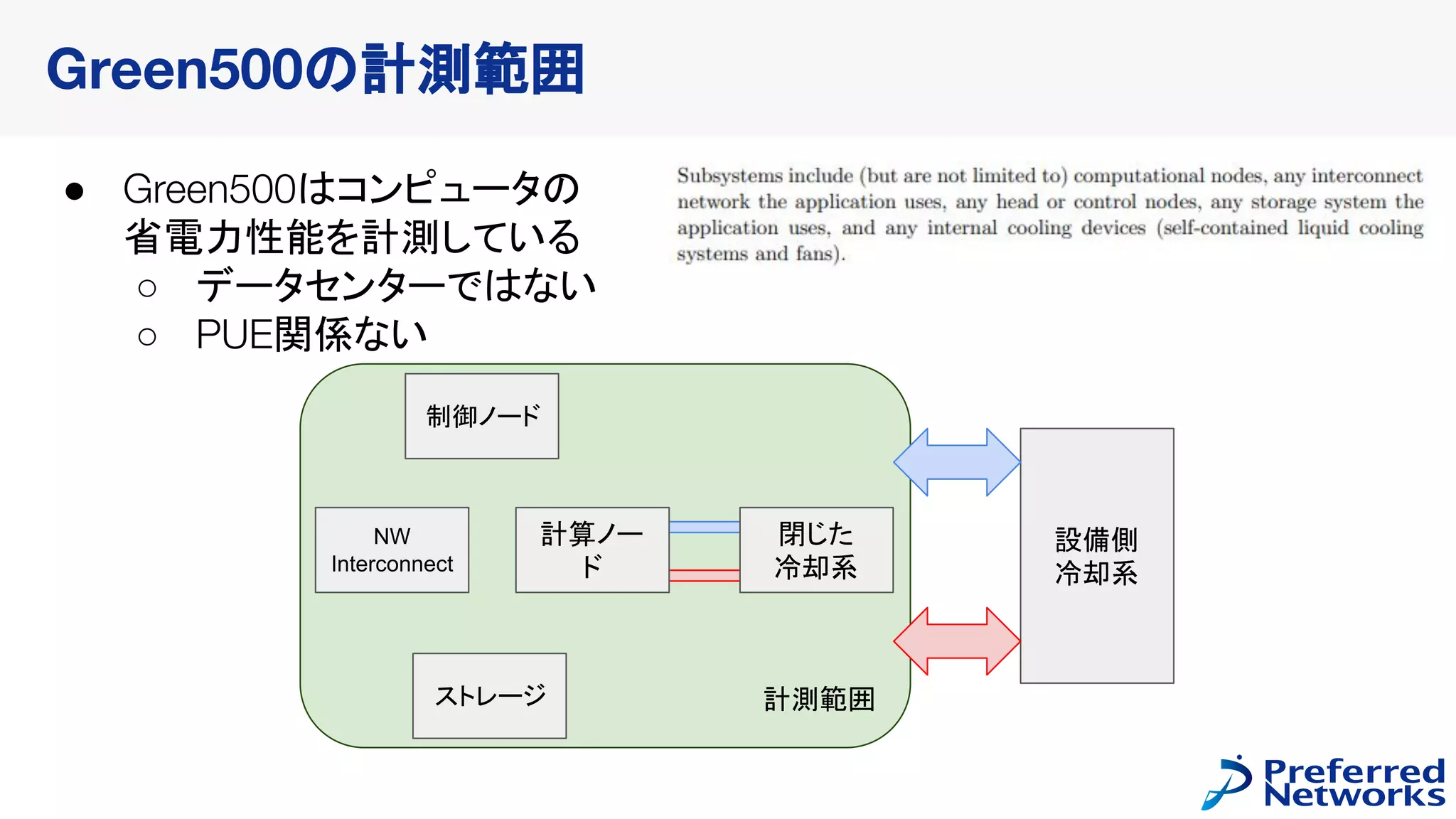
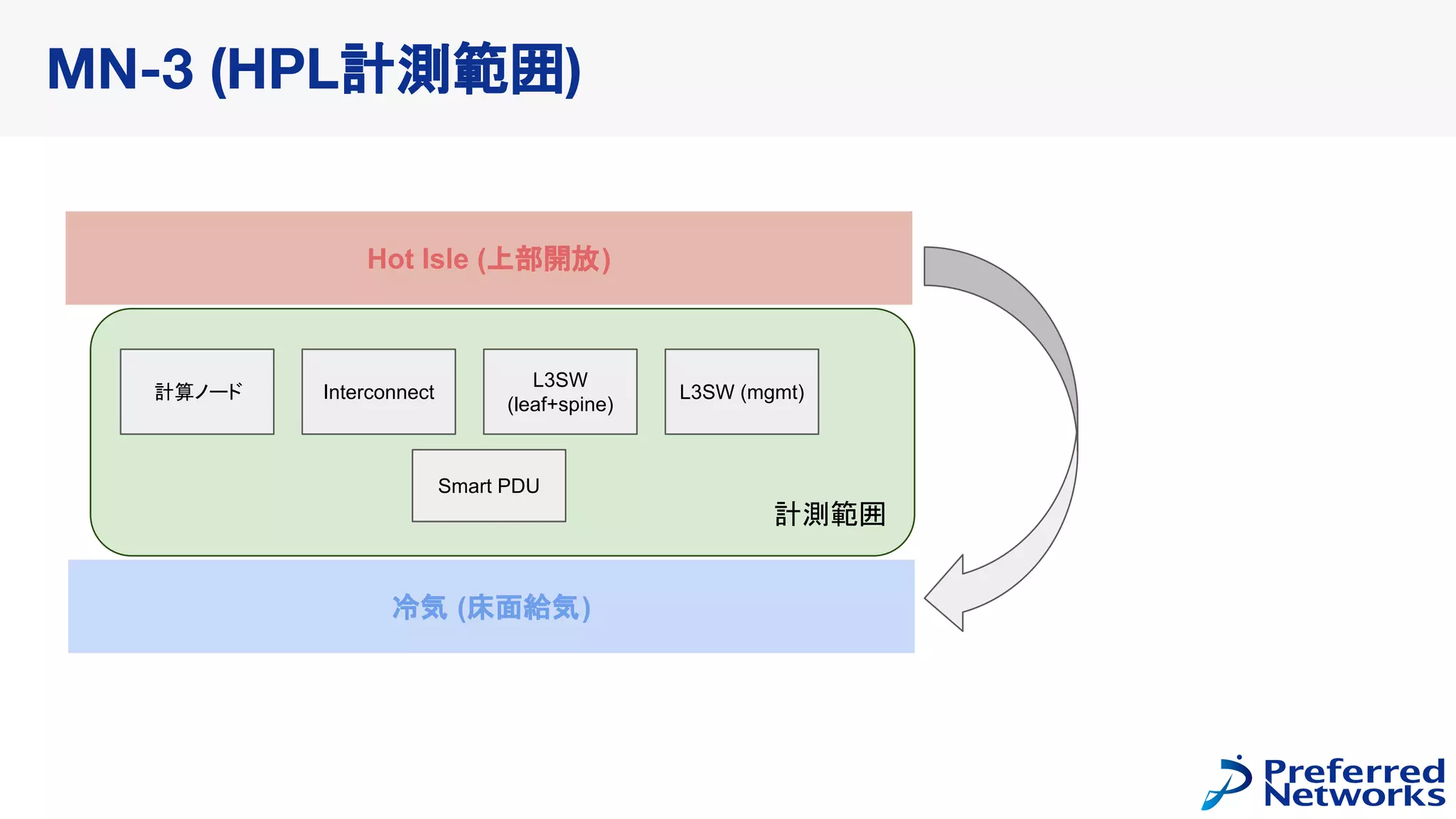
HPL Result



















































![[Dl輪読会]dl hacks輪読](https://cdn.slidesharecdn.com/ss_thumbnails/dldlhacks-161125051944-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する](https://cdn.slidesharecdn.com/ss_thumbnails/31ddbjingohta-150626022623-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)






![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)








































