Recommended
PDF
PPTX
分散ファイルシステムGfarm上でのHadoop MapReduce
PDF
PDF
Hadoop, NoSQL, GlusterFSの概要
PDF
20170310_InDatabaseAnalytics_#1
PDF
PDF
PDF
PDF
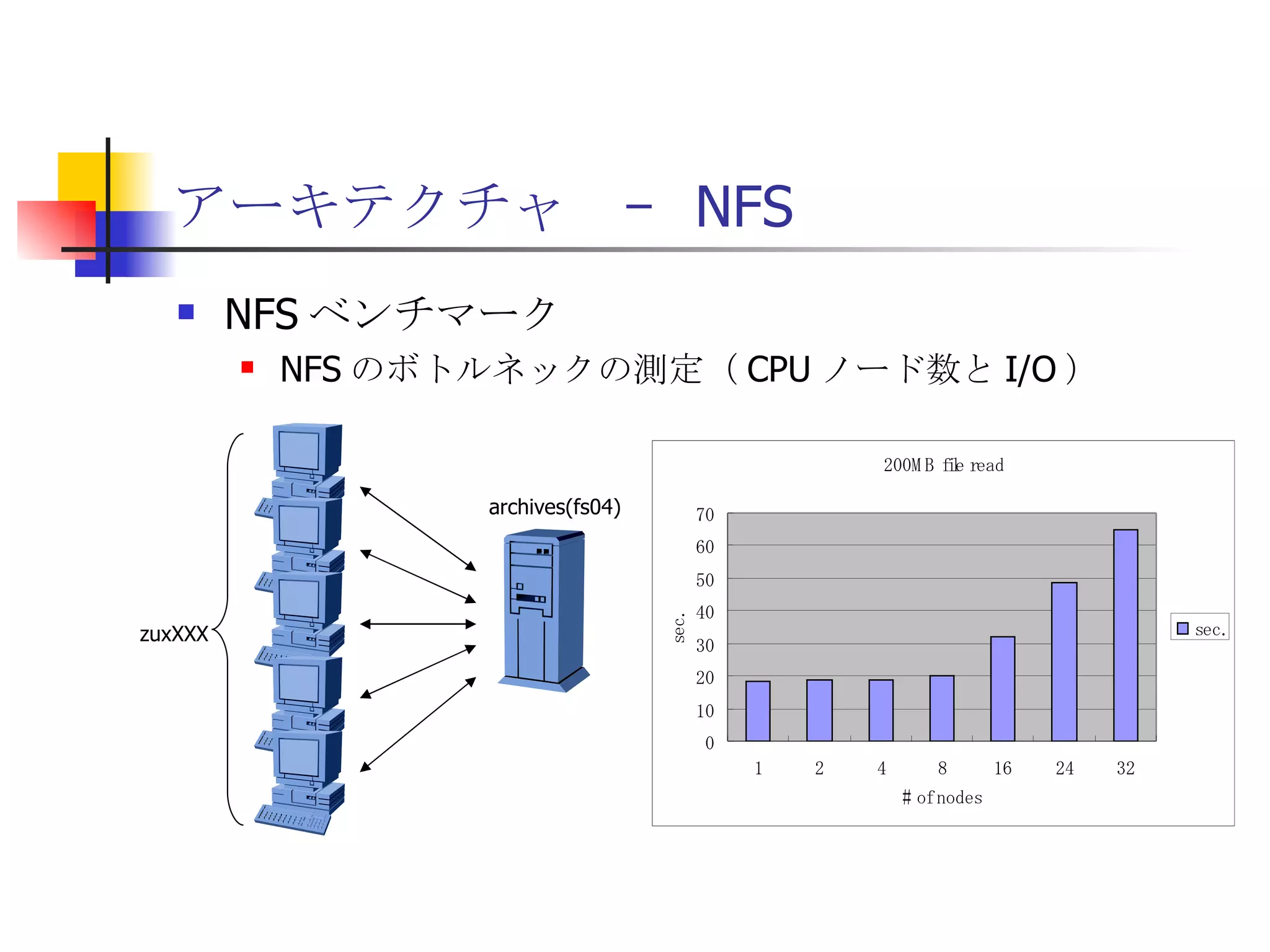
PPTX
Hadoop Troubleshooting 101 - Japanese Version
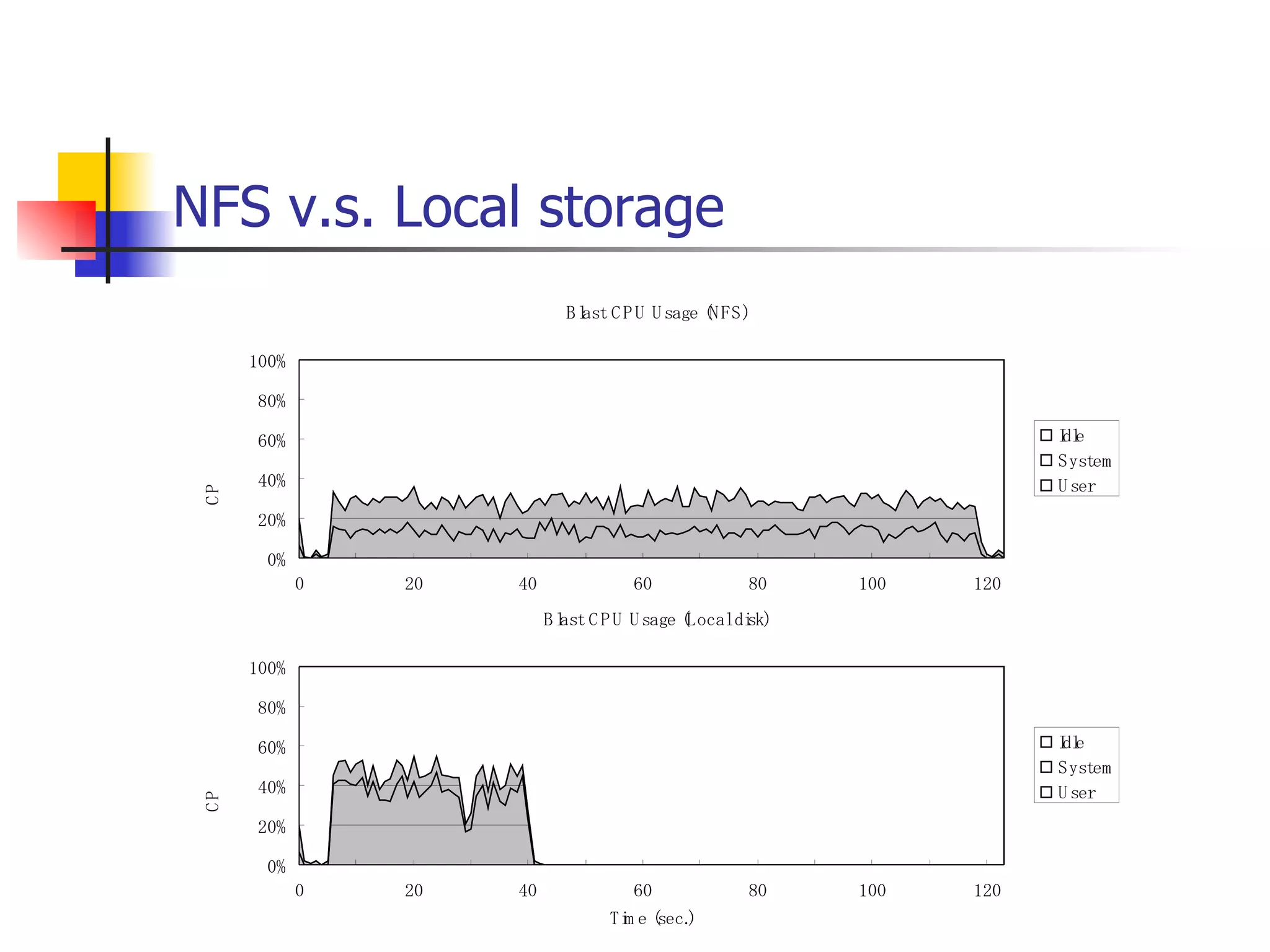
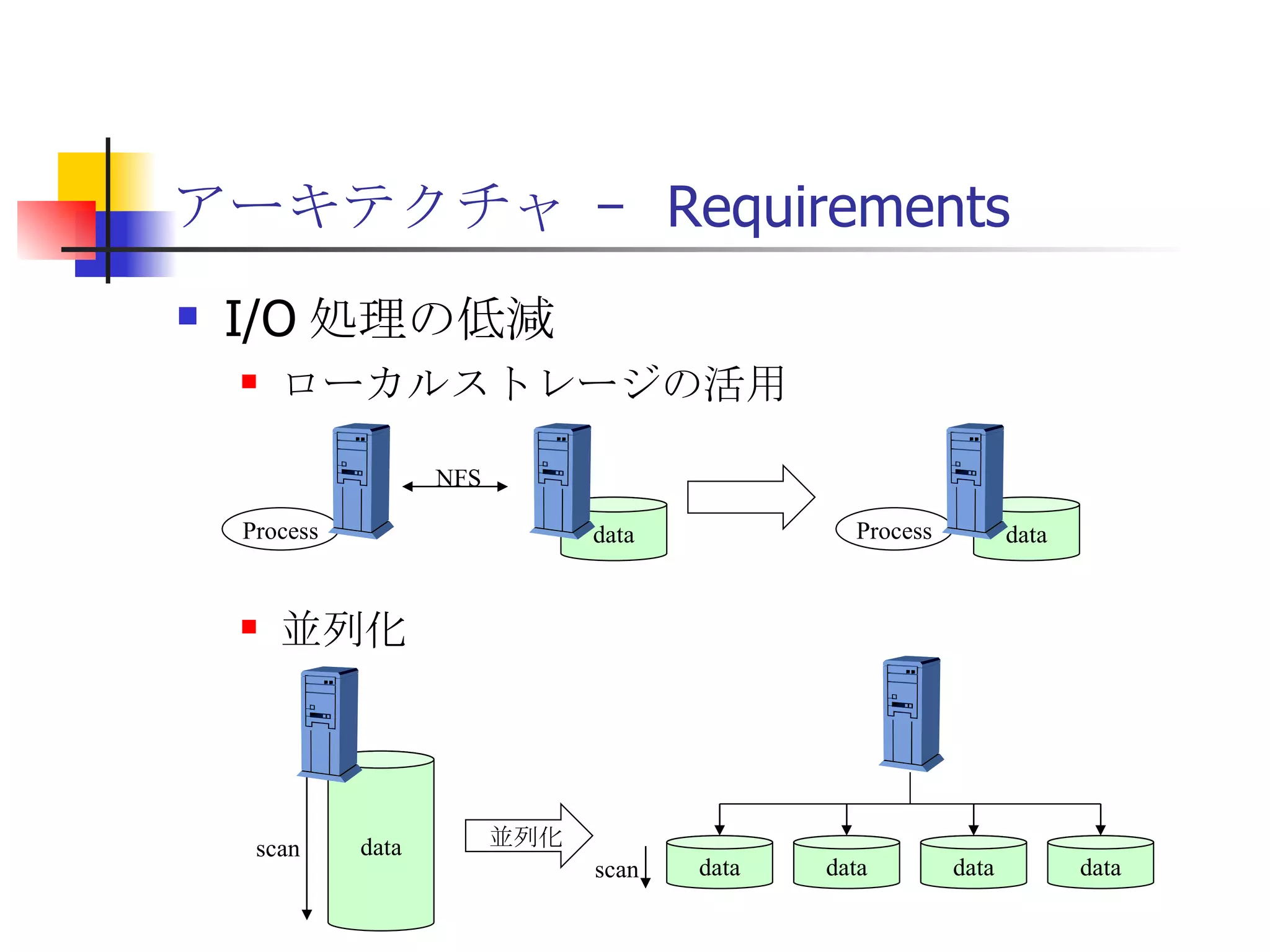
PDF
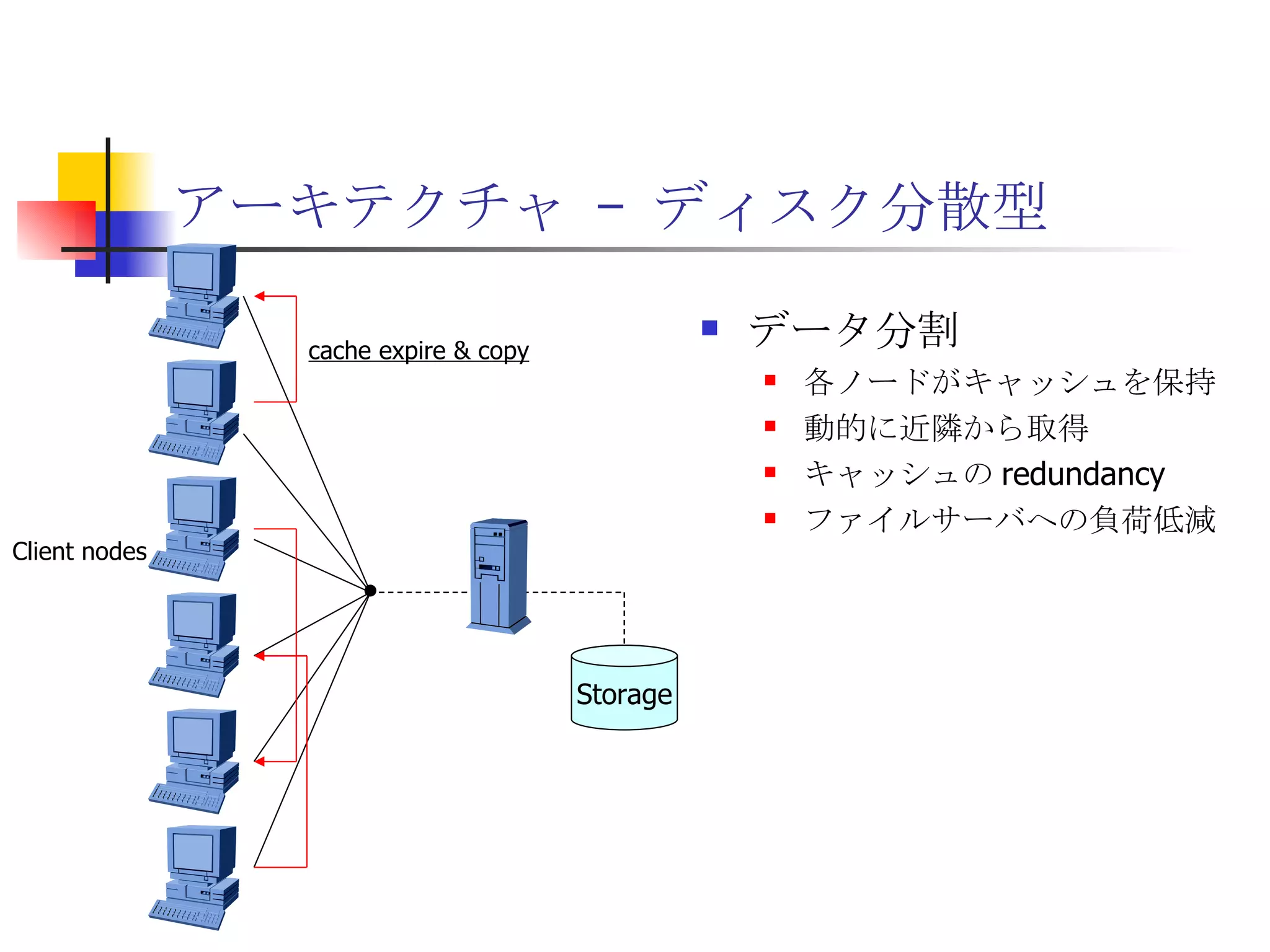
コンテナーによるIT基盤変革 - IT infrastructure transformation -
PPTX
PDF
PPTX
PDF
Fluentdでログを集めてGlusterFSに保存してMapReduceで集計
PDF
PDF
Hadoop/AI基盤における考慮点、PoCの進め方、基盤構成例
PDF
PDF
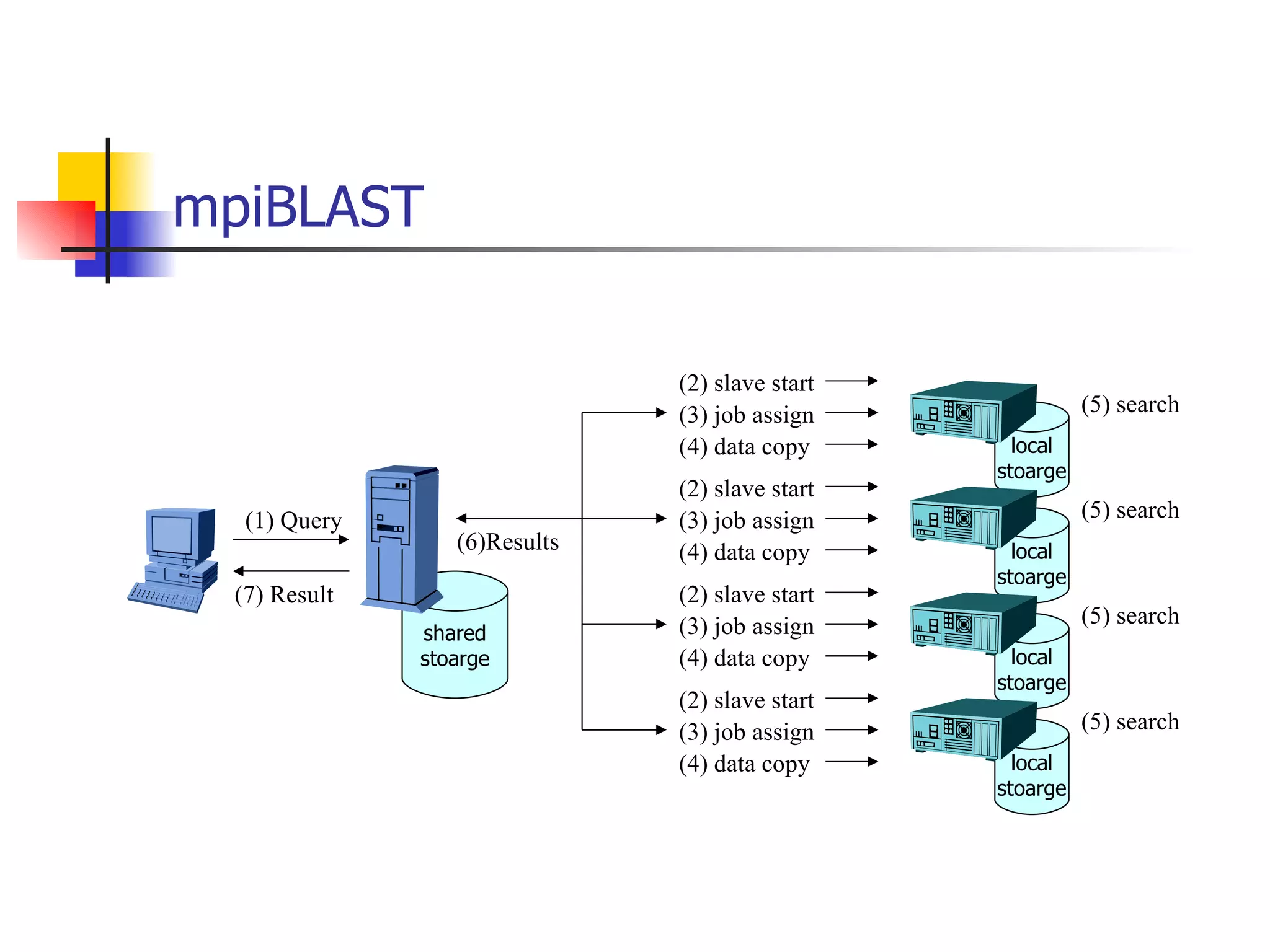
PDF
pgconfasia2016 lt ssd2gpu
PPT
PPTX
PDF
PDF
KEY
Hadoop splittable-lzo-compression
PDF
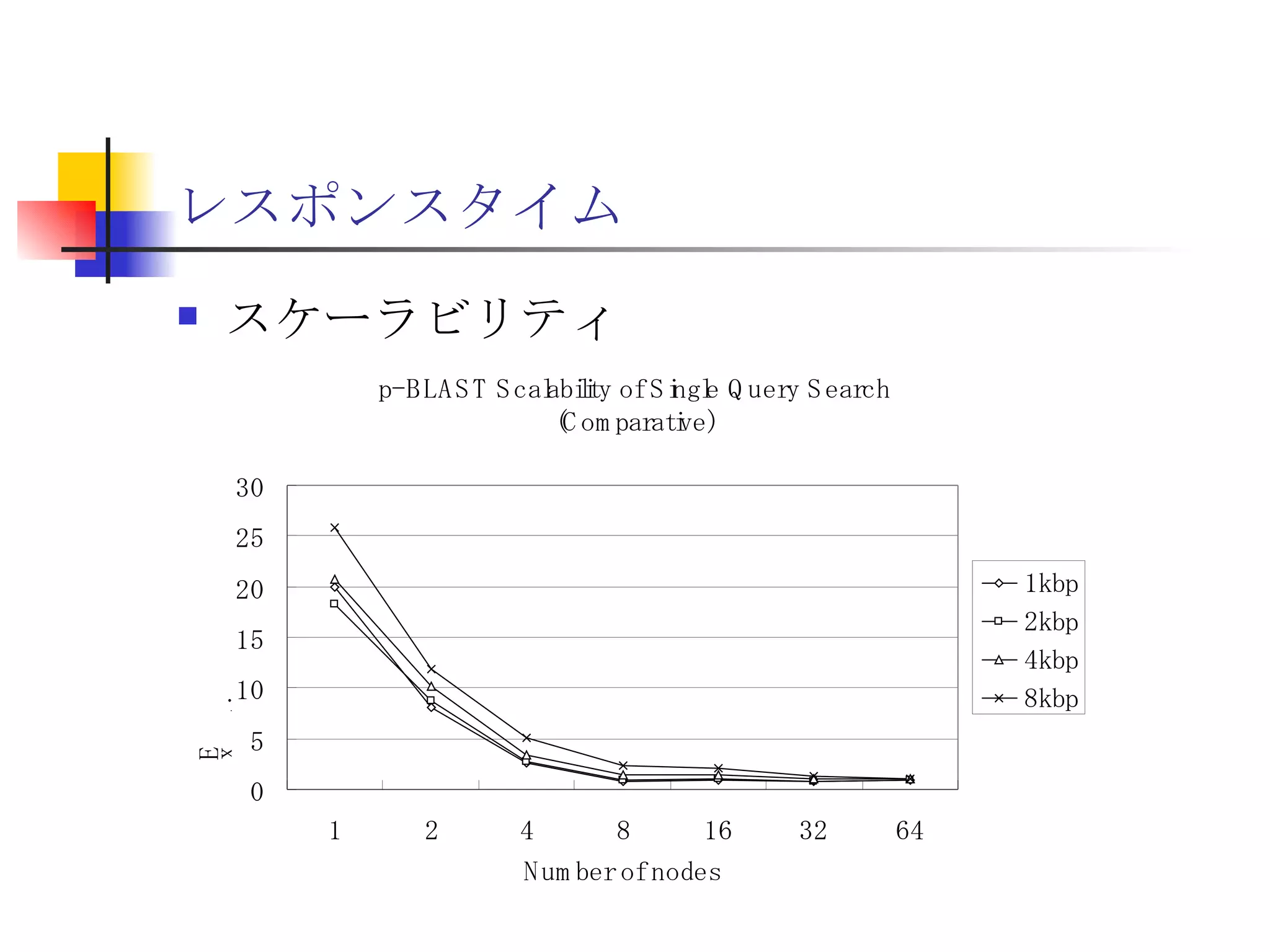
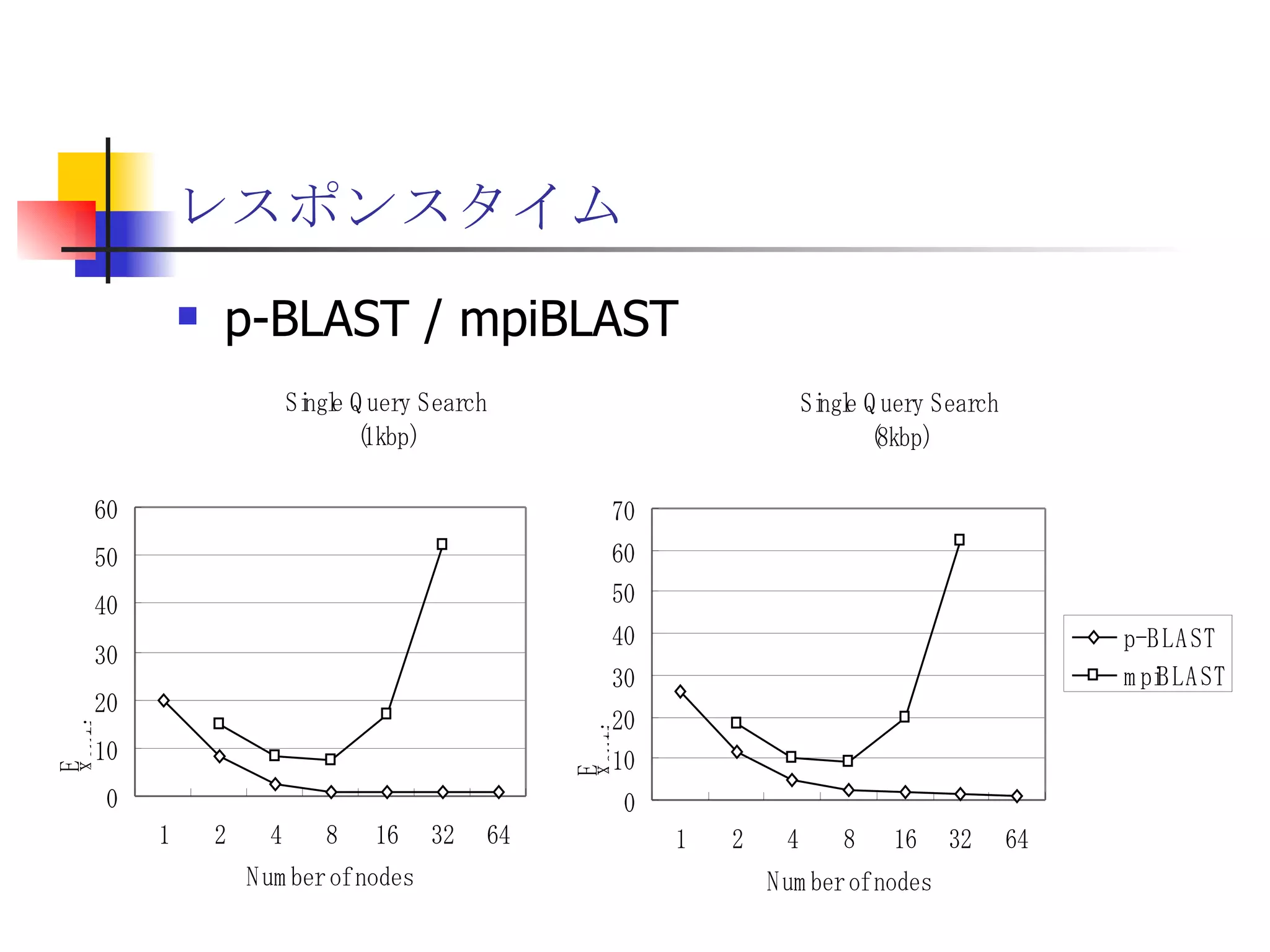
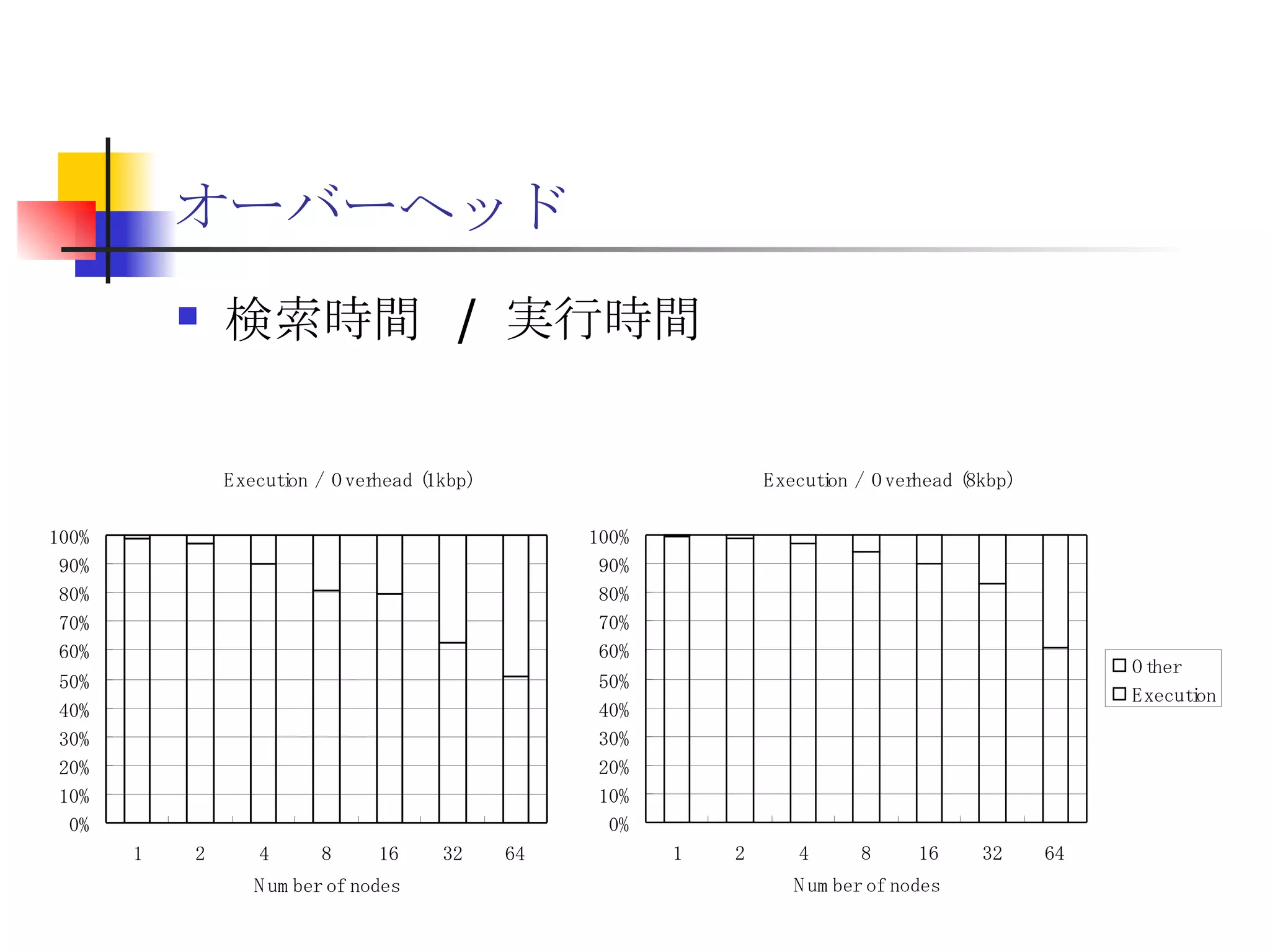
20190926_Try_RHEL8_NVMEoF_Beta
PDF
[db tech showcase Tokyo 2014] B23: SSDとHDDの混在環境でのOracleの超効率的利用方法 by 株式会社日立製作...
PDF
PDF
PDF
More Related Content
PDF
PPTX
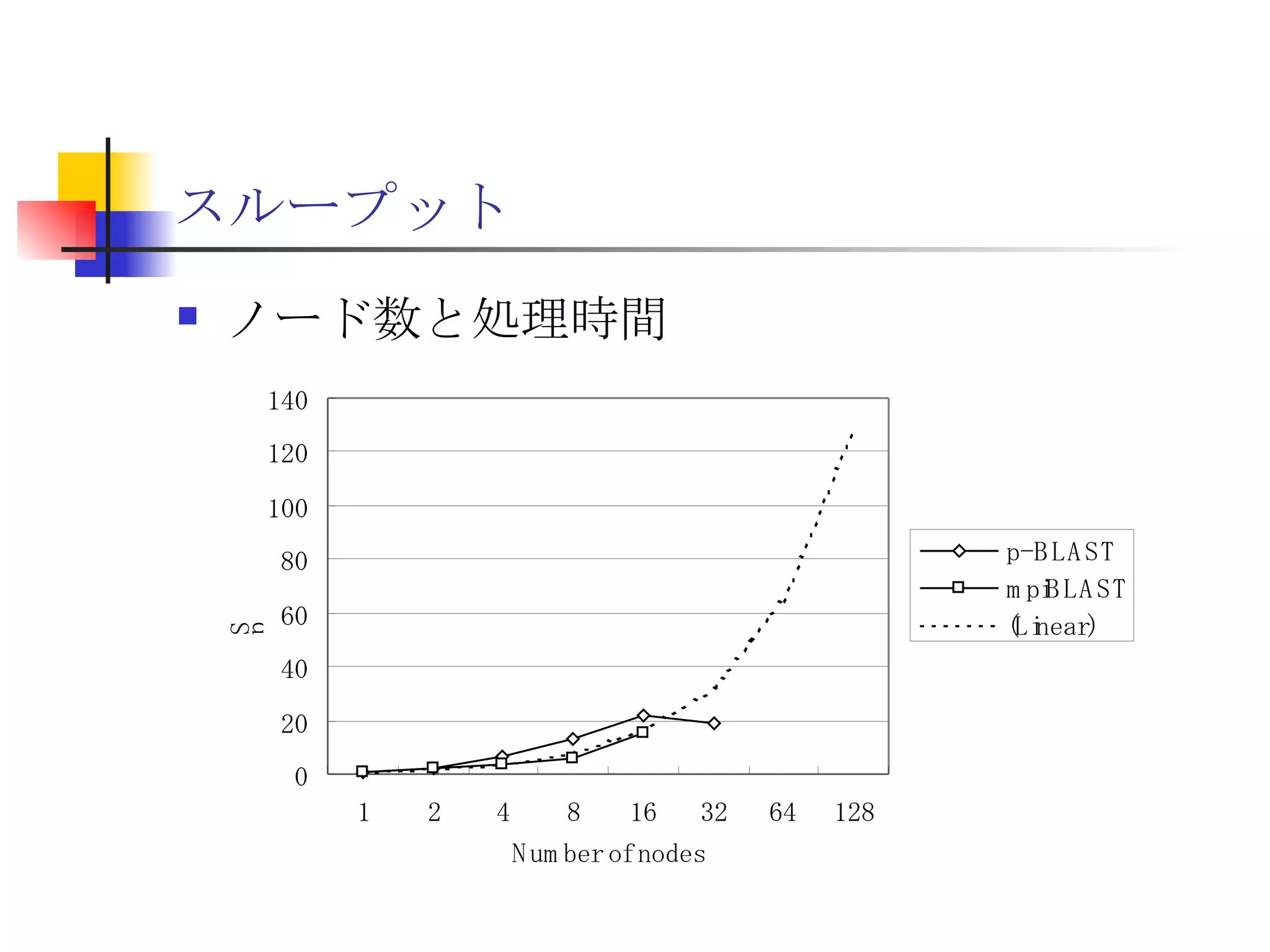
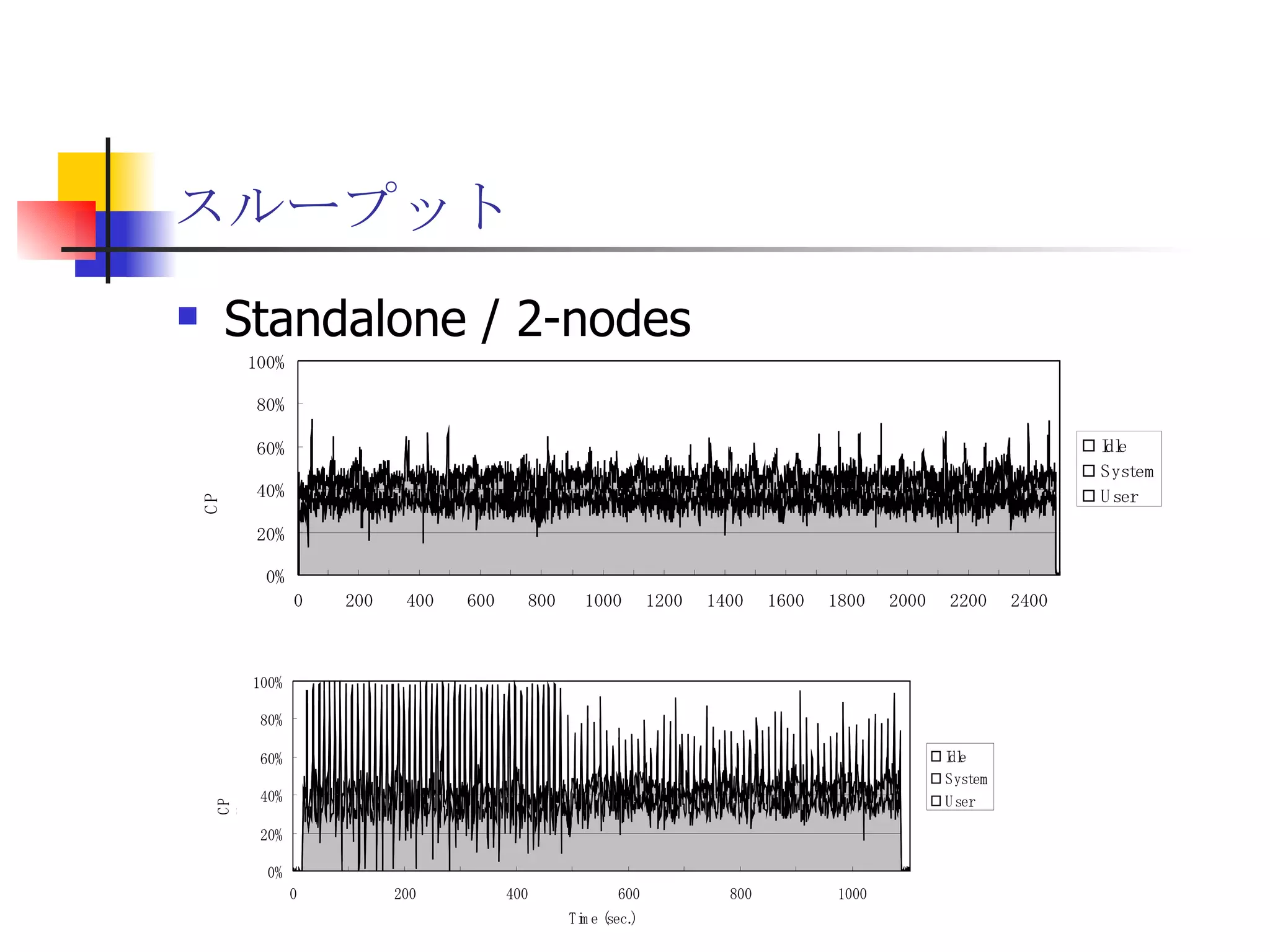
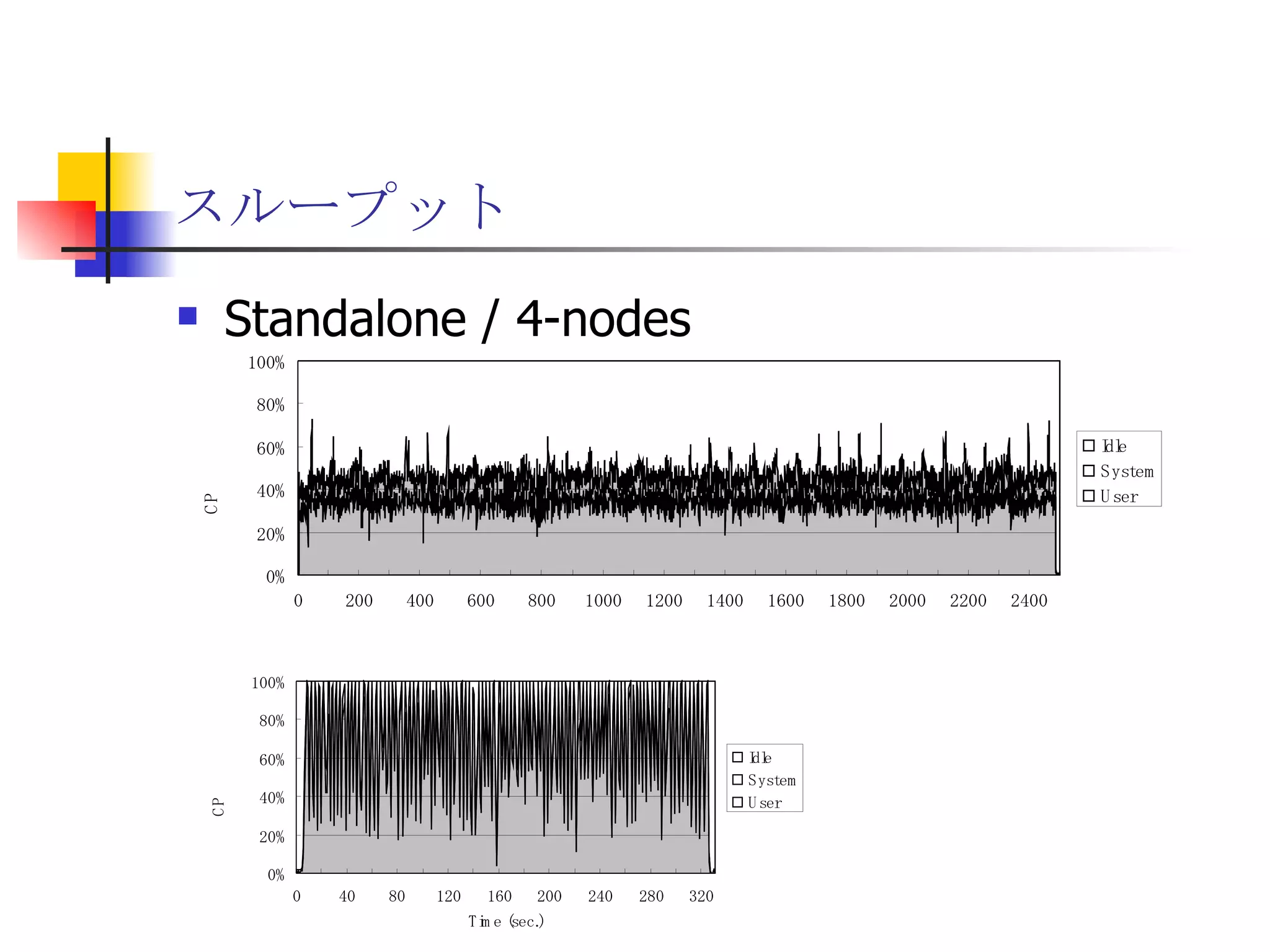
分散ファイルシステムGfarm上でのHadoop MapReduce
PDF
PDF
Hadoop, NoSQL, GlusterFSの概要
PDF
20170310_InDatabaseAnalytics_#1
PDF
PDF
PDF
What's hot
PDF
PPTX
Hadoop Troubleshooting 101 - Japanese Version
PDF
コンテナーによるIT基盤変革 - IT infrastructure transformation -
PPTX
PDF
PPTX
PDF
Fluentdでログを集めてGlusterFSに保存してMapReduceで集計
PDF
PDF
Hadoop/AI基盤における考慮点、PoCの進め方、基盤構成例
PDF
PDF
PDF
pgconfasia2016 lt ssd2gpu
PPT
PPTX
PDF
PDF
KEY
Hadoop splittable-lzo-compression
PDF
20190926_Try_RHEL8_NVMEoF_Beta
PDF
[db tech showcase Tokyo 2014] B23: SSDとHDDの混在環境でのOracleの超効率的利用方法 by 株式会社日立製作...
Viewers also liked
PDF
PDF
PDF
PPTX
海外の技術カンファレンスに行こう! Let’s go tech conferences overseas!
PDF
PostgreSQL 9.4, 9.5 and Beyond @ COSCUP 2015 Taipei
PDF
PostgreSQL Community in Japan
PDF
PDF
10 Reasons to Start Your Analytics Project with PostgreSQL
PDF
PDF
NTT DATA と PostgreSQL が挑んだ総力戦
PDF
PostgreSQLの運用・監視にまつわるエトセトラ
PDF
In-Database Analyticsの必要性と可能性
Similar to 遊休リソースを用いた�相同性検索処理の並列化とその評価
PDF
第4回 配信講義 計算科学技術特論A (2021)
PDF
PCCC23:Pacific Teck Japan テーマ1「データがデータを生む時代に即したストレージソリューション」
PPTX
PPTX
PDF
InfiniBandをPCIパススルーで用いるHPC仮想化クラスタの性能評価
PDF
PDF
20180723 PFNの研究基盤 / PFN research system infrastructure
PDF
PDF
Pacemaker + PostgreSQL レプリケーション構成(PG-REX)のフェイルオーバー高速化
PDF
PDF
[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する
PPTX
PPTX
Windows HPC Server 講習会 第2回 開発編
PDF
Hadoop operation chaper 4
PDF
Aws st 20130522-piop_sbench
PDF
CMSI計算科学技術特論A(4) Hybrid並列化技法
PDF
ASPLOS2017: Building Durable Transactions with Decoupling for Persistent Memory
PDF
PPTX
PPTX
More from Satoshi Nagayasu
PDF
データウェアハウスモデリング入門(ダイジェスト版)(事前公開版)
PDF
Oracle対応アプリケーションのDockerize事始め
PDF
アナリティクスをPostgreSQLで始めるべき10の理由@第6回 関西DB勉強会
PDF
PDF
A Story Behind the Conference, or How pgDay Asia was born
PDF
データベースエンジニアがデータヘルスの2年間で見たもの(仮)
PDF
PostgreSQL 9.4 and Beyond @ FOSSASIA 2015 Singapore
PPTX
Django/Celeyを用いたデータ分析Webアプリケーションにおける非同期処理の設計と実装
PDF
PDF
PostgreSQL Internals - Buffer Management
PDF
PostgreSQL� - C言語によるユーザ定義関数の作り方
PDF
Recently uploaded
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
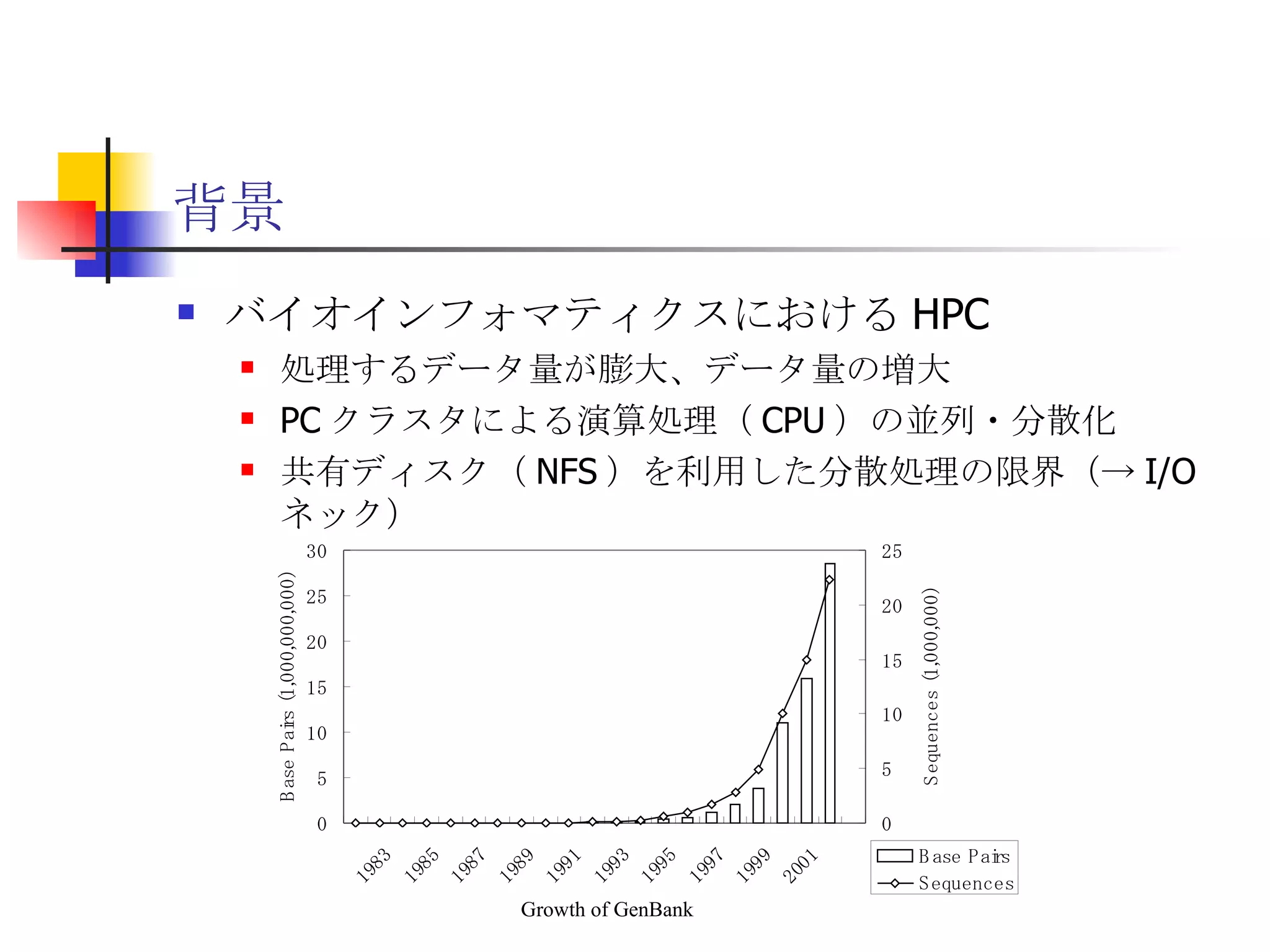
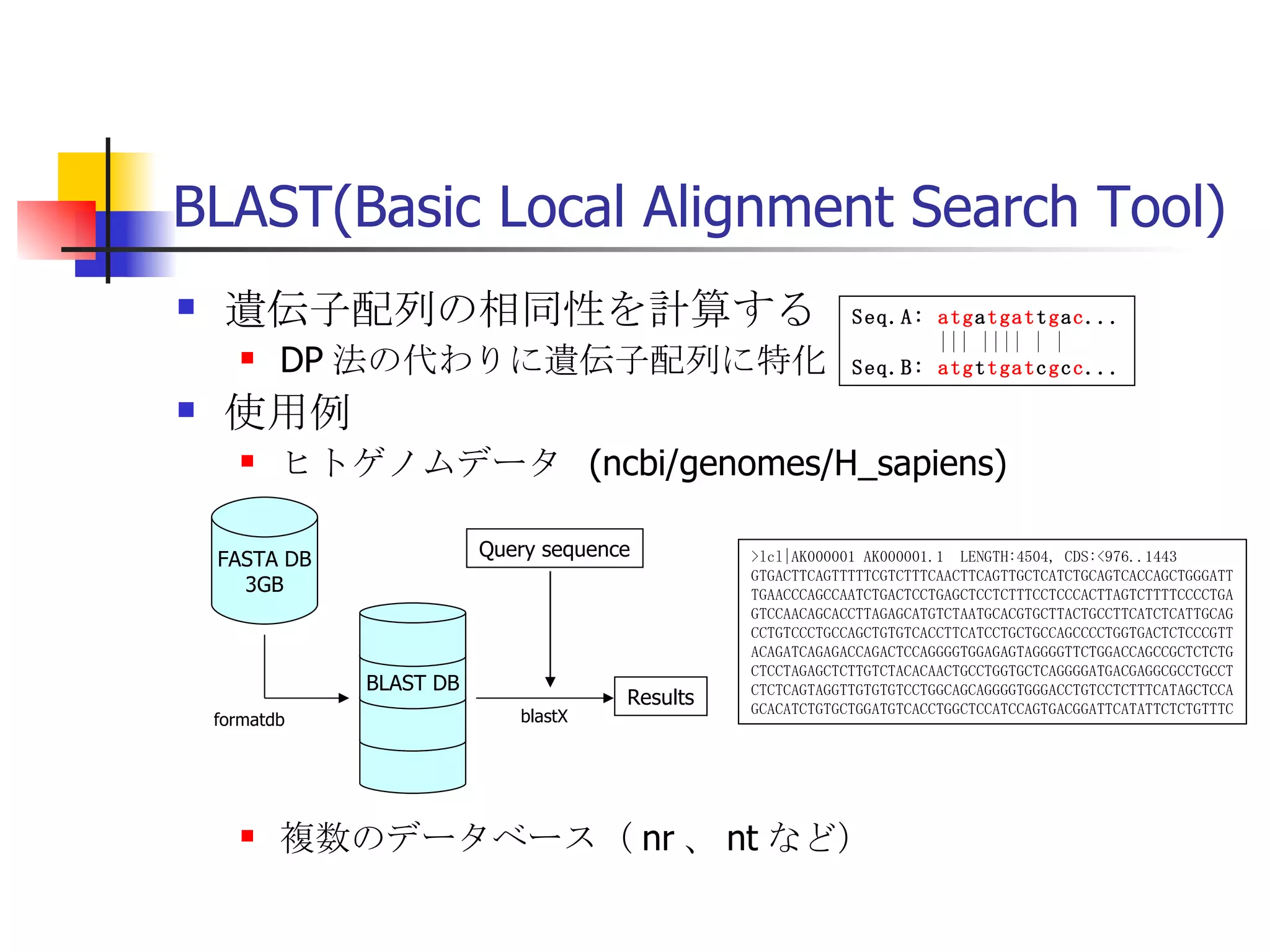
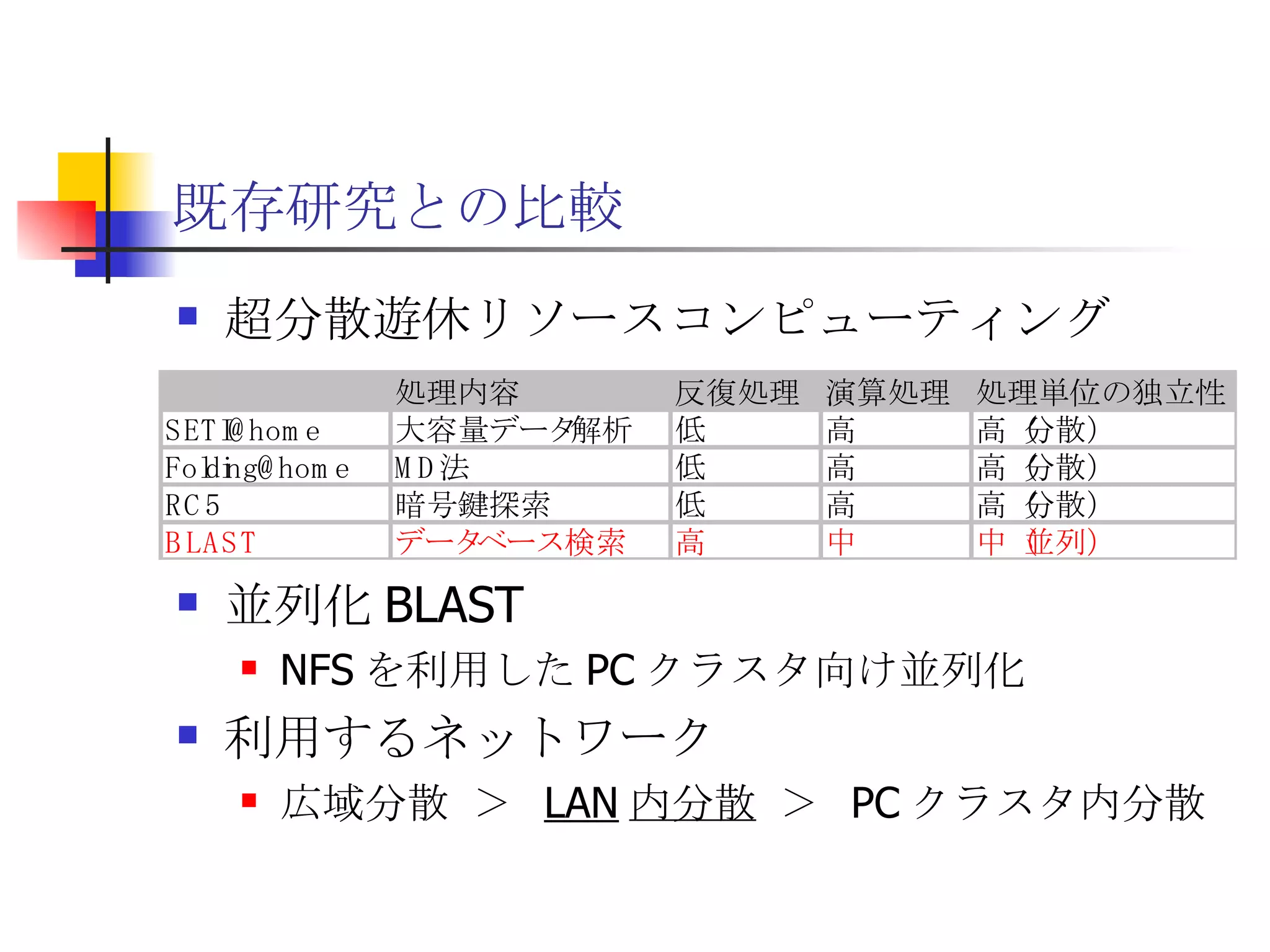
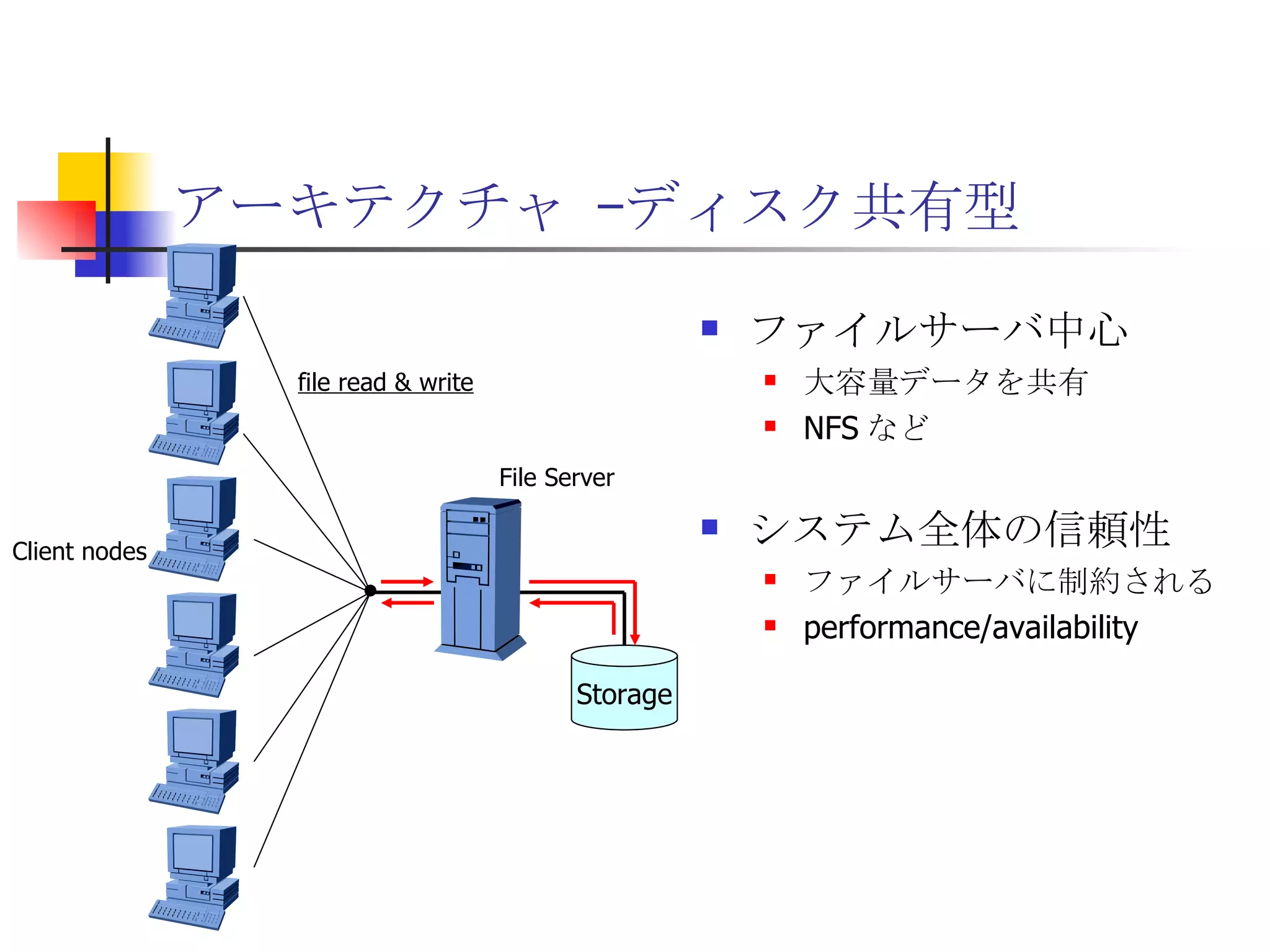
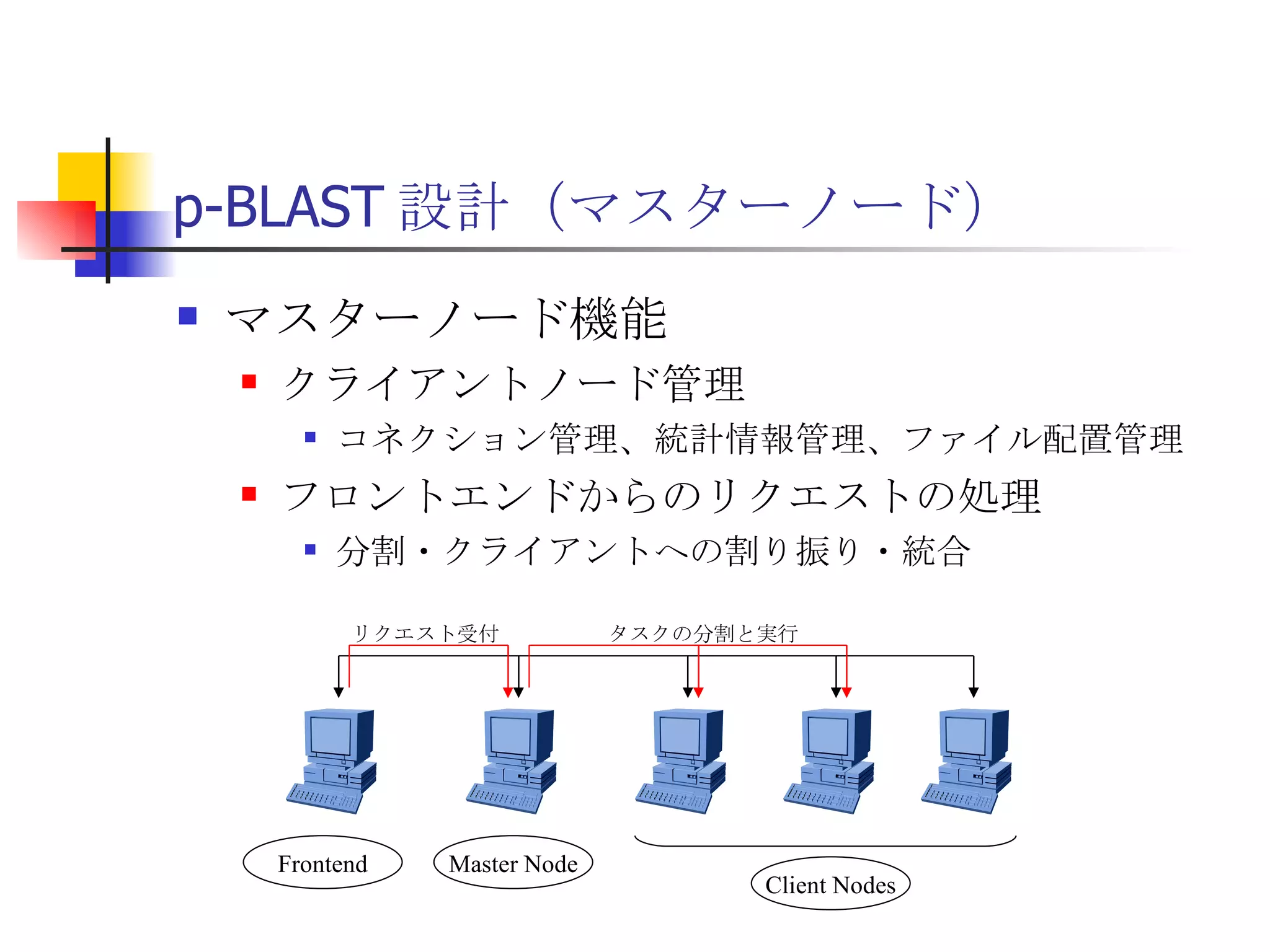
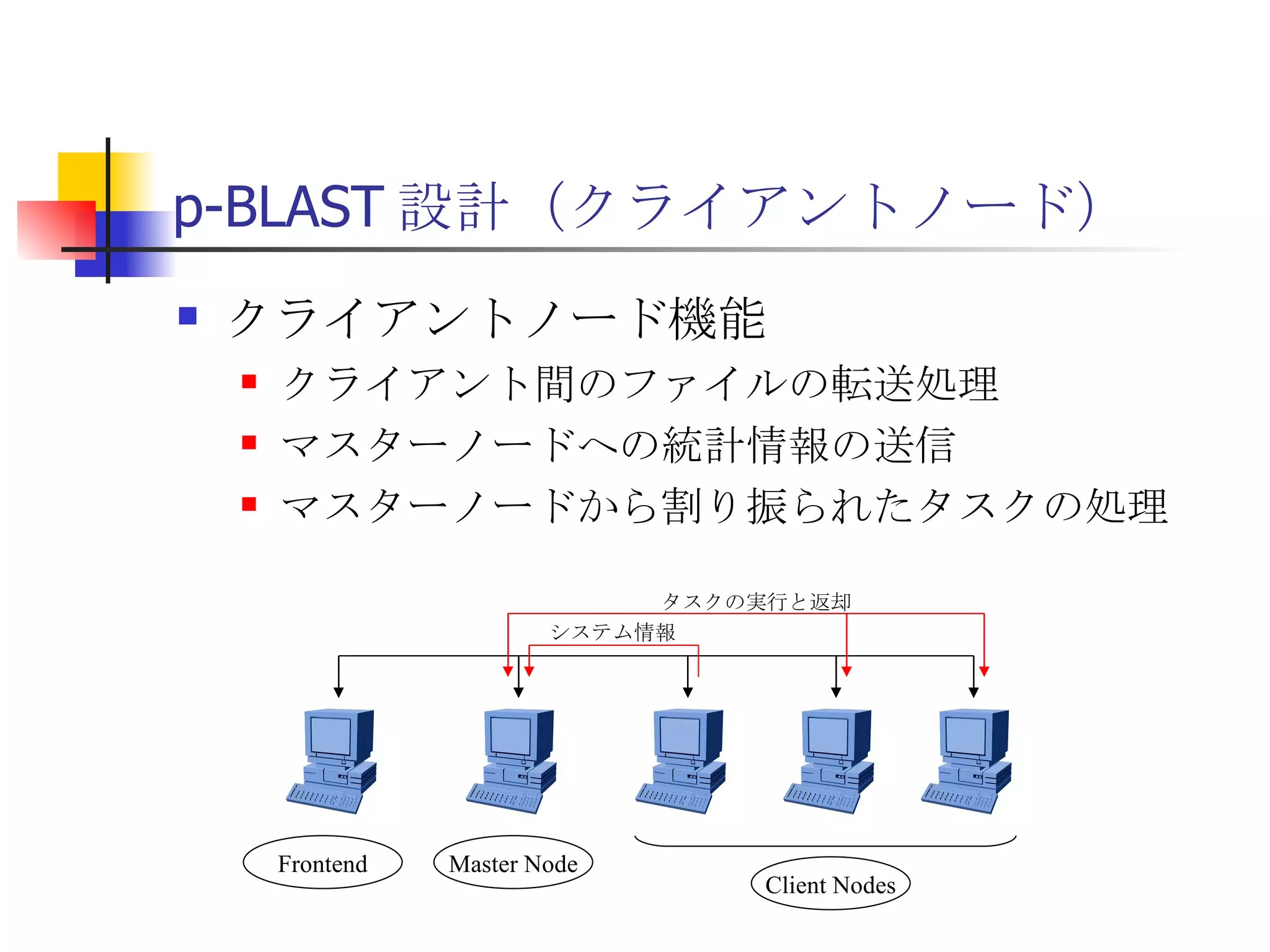
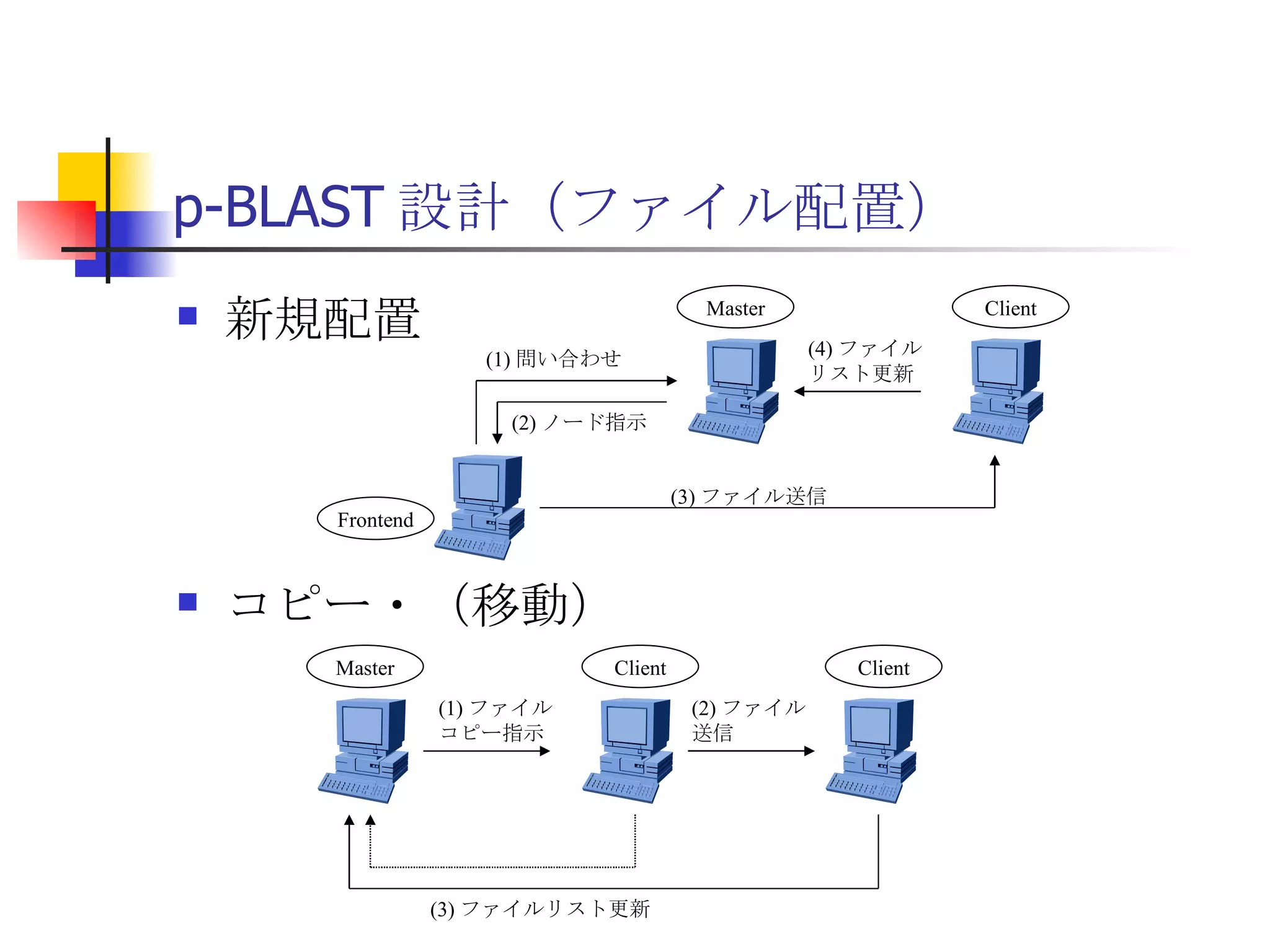
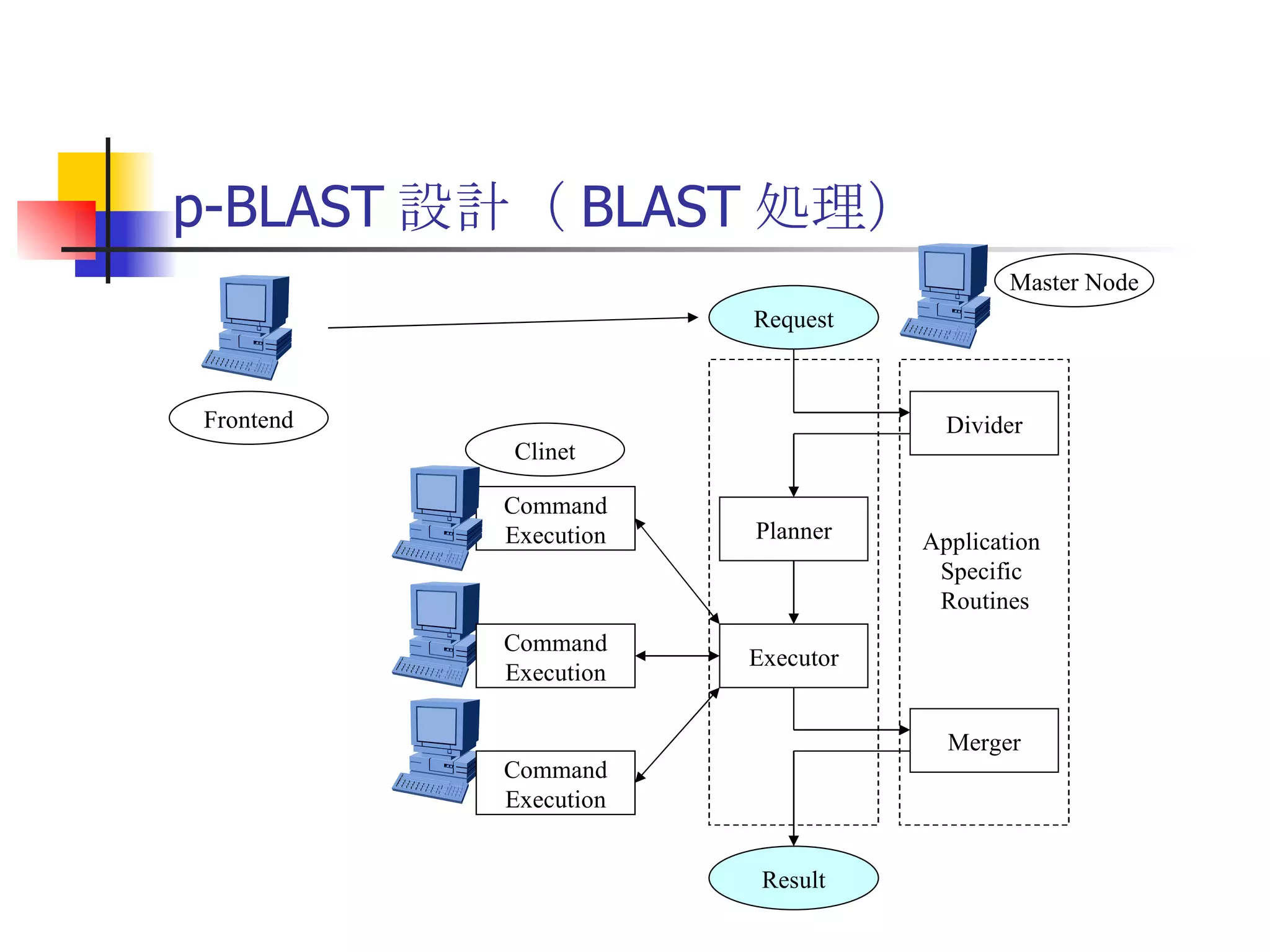
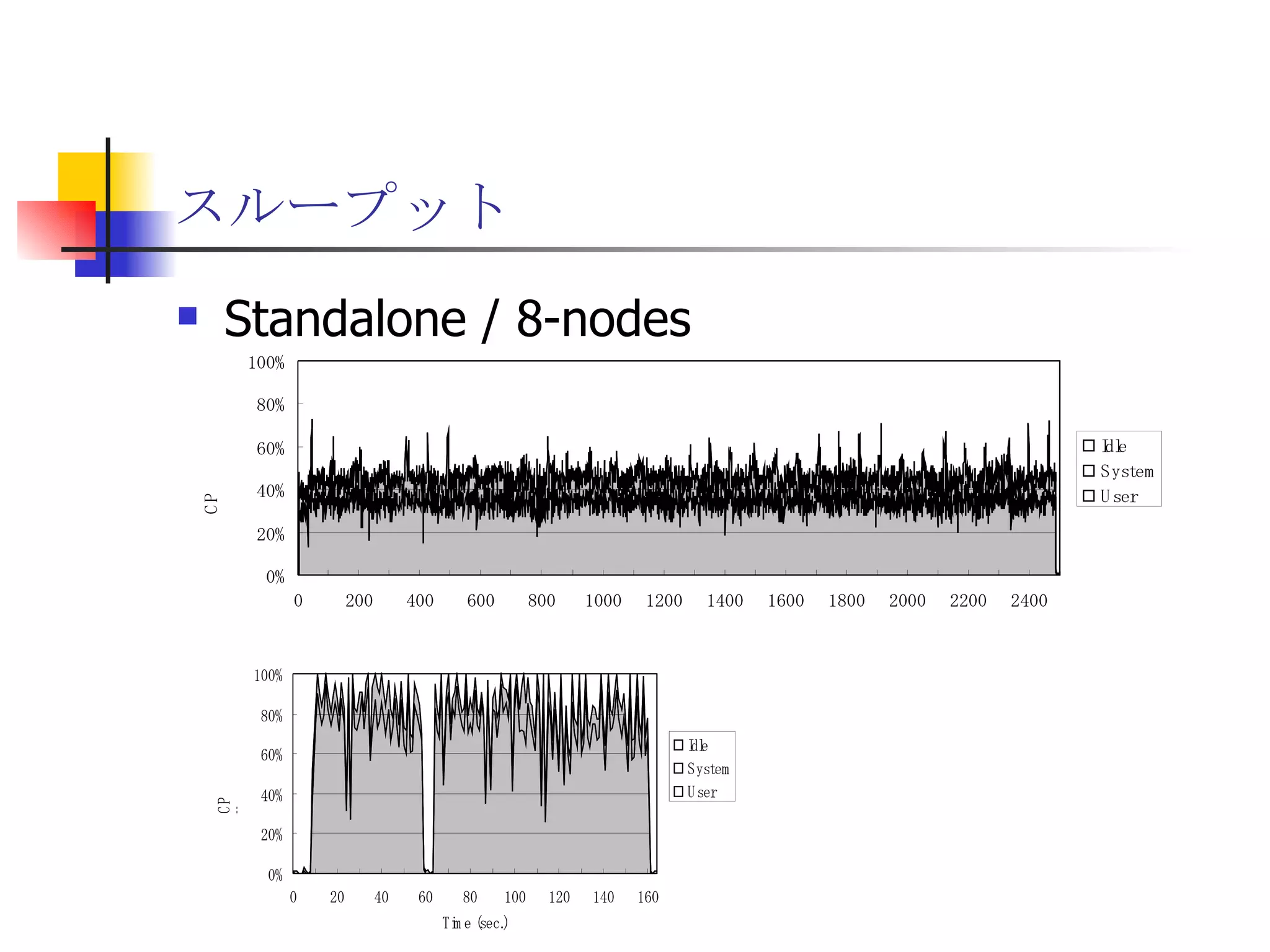
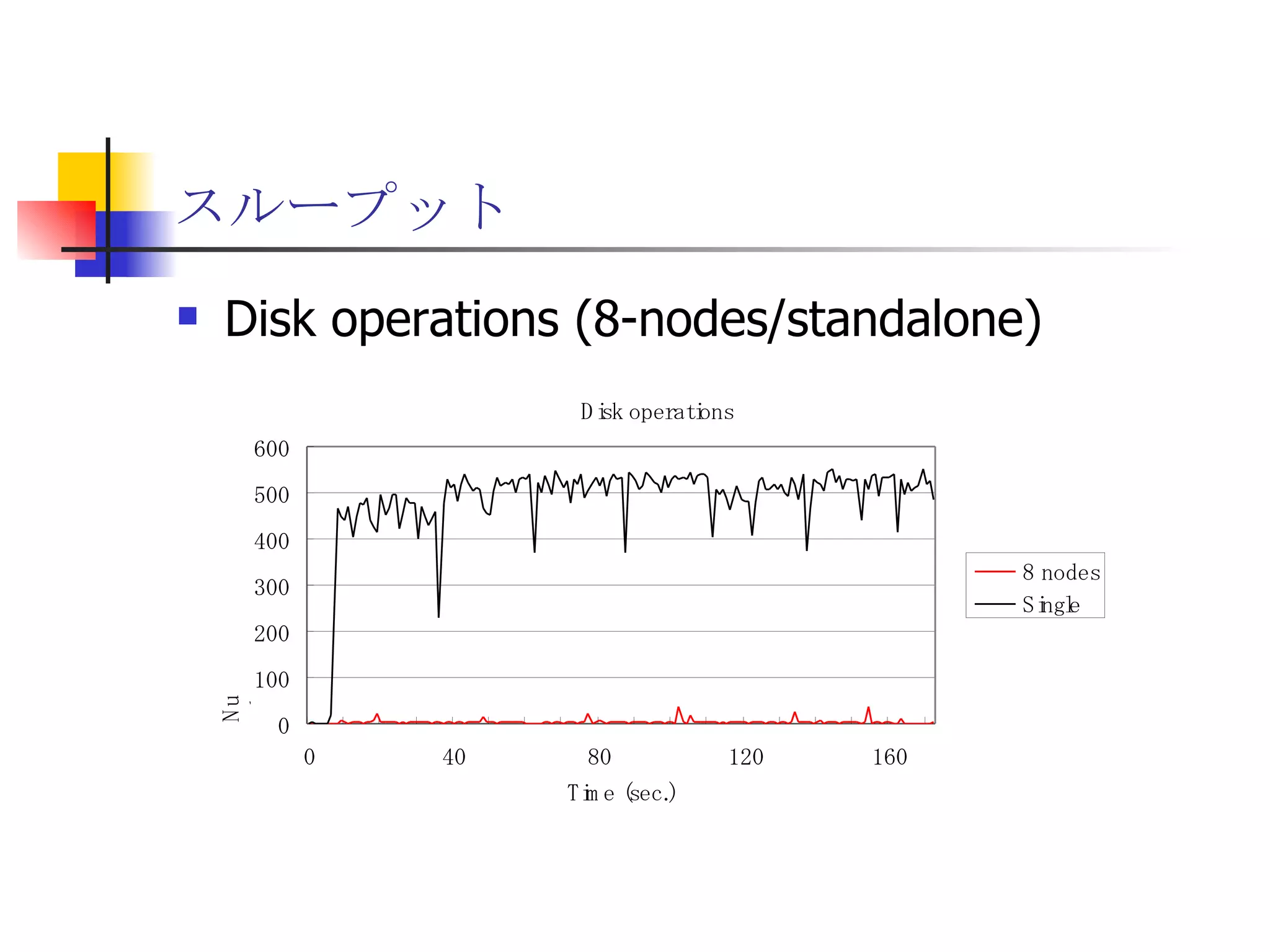
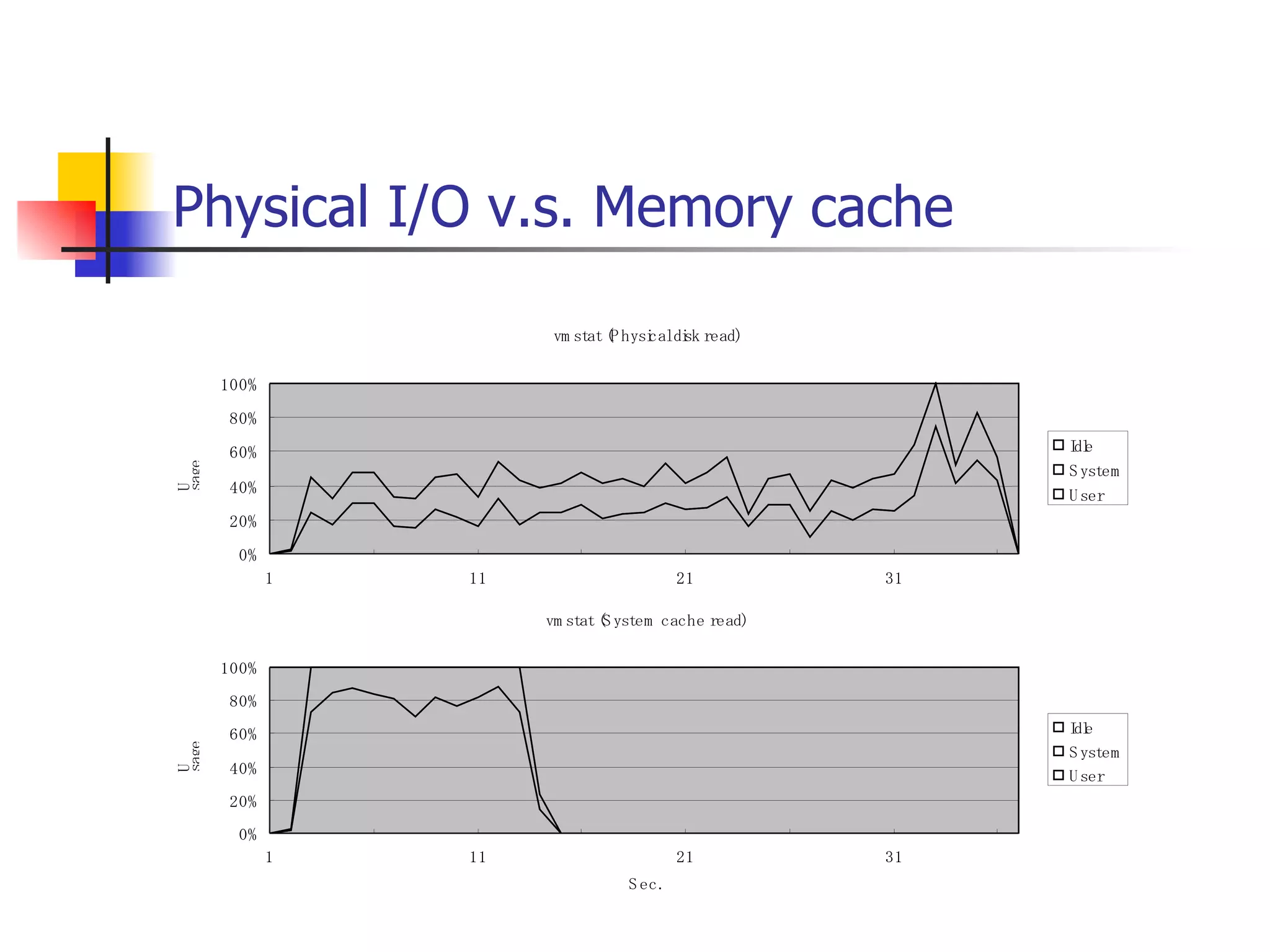
遊休リソースを用いた�相同性検索処理の並列化とその評価 1. 2. 背景 PC ・ WS のパフォーマンス向上 CPU 、メモリ、ネットワーク、ストレージ ハイパフォーマンスなハードウェアのコモディティ化 個々の PC ・ WS のリソースは余剰気味 遊休リソースコンピューティング PC クラスタを用いた HPC PC クラスタのコストパフォーマンス 高度 and/or 高価なハードウェア / ソフトウェアの管理コスト 3. 背景 バイオインフォマティクスにおける HPC 処理するデータ量が膨大、データ量の増大 PC クラスタによる演算処理( CPU )の並列・分散化 共有ディスク( NFS )を利用した分散処理の限界(-> I/O ネック) Growth of GenBank 4. 5. 目的 遊休リソースコンピューティングの HPC アプリケーション への適用とその実証評価 パフォーマンス、スケーラビリティの評価 既存の分散技術との比較 遊休リソースコンピューティング PC ・ WS などのコモディティハードウェアを用いる 既存の遊休資源を用いる バイオインフォマティクスの HPC アプリケーション 処理するデータサイズが大きい アプリケーションが比較的シンプル 6. 手法 サンプルアプリケーション⇒ BLAST Basic Local Alignment Search Tools 遺伝子データにおける類似配列の検索 比較評価できる並列分散の実装( mpiBLAST ) 遊休ワークステーション ( ~ 160 台)を使用 評価項目 スケーラビリティ(ノード数、データ量) レスポンスタイム スループット 7. BLAST(Basic Local Alignment Search Tool) 遺伝子配列の相同性を計算する DP 法の代わりに遺伝子配列に特化 使用例 ヒトゲノムデータ (ncbi/genomes/H_sapiens) 複数のデータベース( nr 、 nt など) >lcl|AK000001 AK000001.1 LENGTH:4504, CDS:<976..1443 GTGACTTCAGTTTTTCGTCTTTCAACTTCAGTTGCTCATCTGCAGTCACCAGCTGGGATT TGAACCCAGCCAATCTGACTCCTGAGCTCCTCTTTCCTCCCACTTAGTCTTTTCCCCTGA GTCCAACAGCACCTTAGAGCATGTCTAATGCACGTGCTTACTGCCTTCATCTCATTGCAG CCTGTCCCTGCCAGCTGTGTCACCTTCATCCTGCTGCCAGCCCCTGGTGACTCTCCCGTT ACAGATCAGAGACCAGACTCCAGGGGTGGAGAGTAGGGGTTCTGGACCAGCCGCTCTCTG CTCCTAGAGCTCTTGTCTACACAACTGCCTGGTGCTCAGGGGATGACGAGGCGCCTGCCT CTCTCAGTAGGTTGTGTGTCCTGGCAGCAGGGGTGGGACCTGTCCTCTTTCATAGCTCCA GCACATCTGTGCTGGATGTCACCTGGCTCCATCCAGTGACGGATTCATATTCTCTGTTTC Seq.A: atg a tgat t g a c ... ||| |||| | | Seq.B: atg t tgat c g c c ... FASTA DB 3GB formatdb BLAST DB Query sequence blastX Results 8. 9. 10. 11. 12. アーキテクチャ –ディスク共有型 ファイルサーバ中心 大容量データを共有 NFS など システム全体の信頼性 ファイルサーバに制約される performance/availability Storage File Server Client nodes file read & write 13. アーキテクチャ – NFS NFS ベンチマーク NFS のボトルネックの測定( CPU ノード数と I/O ) archives(fs04) zuxXXX 14. 15. アーキテクチャ – Requirements I/O 処理の低減 ローカルストレージの活用 並列化 Process data data data data scan data NFS Process data data scan 並列化 16. アーキテクチャ – ディスク分散型 データ分割 各ノードがキャッシュを保持 動的に近隣から取得 キャッシュの redundancy ファイルサーバへの負荷低減 Storage Client nodes cache expire & copy 17. アーキテクチャ – コンセプト(まとめ) ストレージ共有型 多数の計算ノードから負荷が集中 ファイルサーバにボトルネック ストレージ分散型 I/O 処理を分散することが可能 ファイルサーバのボトルネック、 SPF を解消 ※ SPF=Single Point of Failure 18. 19. p-BLAST 設計(概要) p-BLAST 構成 フロントエンド、マスターノード、クライアントノード フロントエンド:マスターノードへの処理要求 マスターノード:処理の分割・統合。クライアントの管理 クライアント:ファイルの保持・管理。分割されたタスクの実行 フラットなネットワーク Client Nodes Master Node Frontend 20. p-BLAST 設計(マスターノード) マスターノード機能 クライアントノード管理 コネクション管理、統計情報管理、ファイル配置管理 フロントエンドからのリクエストの処理 分割・クライアントへの割り振り・統合 Client Nodes Master Node Frontend タスクの分割と実行 リクエスト受付 21. 22. p-BLAST 設計(ファイル配置) 新規配置 コピー・(移動) Master Client Frontend (1) 問い合わせ (2) ノード指示 (3) ファイル送信 (4) ファイル リスト更新 Master Client (1) ファイル コピー指示 Client (2) ファイル 送信 (3) ファイルリスト更新 23. p-BLAST 設計( BLAST 処理) Command Execution Master Node Frontend Clinet Command Execution Command Execution Planner Executor Request Divider Merger Result Application Specific Routines 24. p-BLAST 設計(メッセージング) ノード間のメッセージには XML を利用 <?xml version="1.0"?> <submitJob> <executeCommand> <executable path="PATH" args="STRING" cwd="PATH"> <input> <stdin>STANDARD INPUT CONTENT</stdin> <file name="FILENAME" size="SIZE">FILE CONTENTS</file> </input> </executable> </executeCommand> </submitJob> <?xml version="1.0"?> <resultJob> <commandResult host="HOSTNAME"> <output> <stdout>STDOUT CONTENT</stdout> <stderr/> <hostname>HOSTNAME</hostname> <execTime>EXEC_TIME</execTime> </output> </commandResult> 25. 26. 評価 p-BLAST と mpiBLAST との比較 評価項目 単一リクエストの処理時間(レスポンスタイム) 多重リクエストの処理能力(スループット) I/O 処理量 パラメータ ノード数 クエリサイズ クエリ数 27. mpiBLAST local stoarge local stoarge local stoarge local stoarge shared stoarge (2) slave start (2) slave start (2) slave start (2) slave start (3) job assign (3) job assign (3) job assign (3) job assign (5) search (5) search (5) search (5) search (4) data copy (4) data copy (4) data copy (4) data copy (1) Query (7) Result (6)Results 28. 実験 実験内容 レスポンスタイム計測 スループット性能計測 対象データベース nr 、約 1.5GB formatdb による分割( 2/4/8/16/32/64/128 分割) 実験環境(ノード) Pentium4/1.6GHz 、 256MB RAM 、 40GB IDE 、 100BaseTX 、 FreeBSD 4.7 29. 30. 31. 32. 33. 34. 35. 36. 考察(レスポンスタイム) p-BLAST 32 ノード前後までリニアにスケール 64 ノードにおいてオーバーヘッドと検索時間が拮抗 長いクエリの検索ほど並列化メリットが大 mpiBLAST slave プロセスを起動するオーバーヘッドが大きい rsh 経由、ノード数に比例して増大 ノード数に比例してエラー発生が増加 37. 38. 39. 40. 41. 42. 43. 44. 45. 考察(スループット) p-BLAST 4 、 8 ノード前後から CPU 利用率が向上 データの分割によるオンメモリ処理(物理 I/O の低減) Super-linear なスケーラビリティ ( 32 ノード以降は実装に難あり) mpiBLAST 16 ノード前後までリニアにスケールアップ Long-running な処理では MPI に強み ( Super-linear にならない理由を補完) ノード数が増えるとエラーが頻発し実行不可 通常のデスクトップ PC という環境が原因 46. 考察(まとめ) mpiBLAST MPI はレスポンスタイムの向上には寄与しない ノード増加に比例したオーバーヘッド 不安定な環境に弱い 遊休リソースコンピューティングには不向き p-BLAST レスポンス・スループット向上に有効 十分なスケーラビリティ 不安定な環境に強い データの冗長性、短い接続時間 47. まとめ 遊休リソースコンピューティングと HPC アプリケーションのハイブリッド化は有効である ストレージが大きなボトルネックになっていたことを示し、その解決方法を示した データ分割による並列度向上とオンメモリ処理化 短時間のコネクション 細かなノード管理 今後、増加を続ける計算需要に適用可能 48. 49. 関連文献・研究 Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ.; Basic local alignment search tool.; J Mol Biol; 1990 Oct 5; pp.403-10. Aaron E. Darling, Lucas Carey, Wu-chun Feng; The Design, Implementation, and Evaluation of mpiBLAST; ClusterWorld conference 2003 Ian Korf, Mark Yandell, Joseph Bedell; BLAST; O'Reilly & Associates, Inc.; 2003 Growth of GenBank; Feb.2002; http://www.ncbi.nih.gov/Genbank/genbankstats.html Hong-Song Kim, Hae-Jin Kim, and Dong-Soo Han; Hyper-BLAST: A Parallelized BLAST for Speedup of Similarity Search; Akira Naruse, Naoki Nishinomiya, Kouichi Kumon, Masahito Yamaguchi; Hi-per BLAST: High Performance BLAST on PC Cluster System; Genome Informatics 13; pp.254-255; 2002 R.D.Bjornson, A.H.Sherman, S.B.Weston, N.Willard, J.Wing; TurboBLAST: A Parallel Implemetation of BLAST Built on the TurboHub; HiCOMB 2002 IBM; IBM Redbooks; Benchmark and Performance Analysis of TurboBLAST on IBM xSeries Server Cluster; 2002 永松 秀人 , 廣安 知之 , 三木 光範 ; 相同性検索プログラム FASTA と BLAST に関する調査報告 ; ISDL Report No.20030608006; 2003 年 9 月 8 日 50. Editor's Notes #2 遊休リソースを用いた相同性検索処理の並列化とその評価ということで発表させていただきます。政策メディア研究科二年の永安悟史です。 #3 最初に本研究の背景について簡単に述べさせていただきます。 近年、CPUやメモリ、ネットワークやストレージなど、PCやワークステーションを構成する要素のパフォーマンス向上が目覚しく、その結果、極めて性能のよい計算資源がコモディティ化してきています。 その結果、従来はスーパーコンピュータなどを用いて計算していた自然科学や工学などにおける大規模な演算処理、こういった演算処理のことをハイパフォーマンスコンピューティング、略してHPCと呼びますが、これら性能の向上したPC向けのパーツや、あるいはPCそのものを用いたクラスタシステムを用いて行うケースが増えてきています。 #4 一方、近年バイオサイエンスの分野でも特に注目を集めている、遺伝子情報解析や細胞シミュレーションなどを行うバイオインフォマティクスの分野では、データ量の増大に伴って、膨大な計算資源を必要としています。 そのため、PCクラスタなど、従来と比べるとコストパフォーマンスの高いハードウェアを用いた計算を行うわけですが、特に扱うデータ量が多くなればなるほど、ストレージなどにおけるI/Oにボトルネックが集中する形となってしまいます。このことによって、ハードウェアの性能を十分に引き出せない、という状況が発生しています。これに関しては、また後ほど詳しく述べたいと思います。 #5 そこで、本研究におけるモチベーションですが、現在存在している計算資源、PCやワークステーションなどを、もっと有効に利用できるのではないか、バイオインフォマティクスなどにおける大量データ処理などに有効に使えるのではないか、と考えました。 具体的には、ユーザーが利用していないデスクトップ PC などの CPU 時間を使って分散処理をさせる「遊休リソースコンピューティング」の手法と、 PC クラスタなど、比較的密な環境において利用されている PC クラスタ用 HPC アプリケーションをハイブリッド化することで、計算処理専用に設計された PC クラスタなどではない、デスクトップ PC から、大規模な演算処理の性能を引き出せるのではないかと考えました。 そして、実際に、そのようなシステムでどの程度のパフォーマンスを得ることができるのか、また、どのような制約があって、何を考慮する必要があるのか、といったことを明らかにしたいと考えました。 #6 そこで具体的な本研究の目的ですが、遊休リソースコンピューティングと、 PC クラスタなどの HPC アプリケーションをハイブリッド化したシステムを設計、実装し、パフォーマンス、スケーラビリティの評価を、既存の分散技術と比較することとしました。 利用するアプリケーションに関しては、バイオインフォマティクスで利用されているアプリケーションを用います。その理由は、処理するデータサイズが大きいこと、またアプリケーションが比較的シンプルであることが挙げられます。 これらの実証や評価を行うことによって、遊休リソースを用いたコンピューティング、つまりコモディティ化したハードウェア資源のパフォーマンスを最大限有効に利用するための、パフォーマンスやスケーラビリティについての知見が得られるものと考えております。 #7 実証実験の手法ですが、今回はサンプルアプリケーションとして、バイオインフォマティクスの分野でもっともよく使われているアプリケーションのひとつである BLAST を用いることにしました。理由としましては、非常によく使われているということに加えて、比較評価することができる並列分散の実装、 mpiBLAST が存在していることが挙げられます。 BLAST および mpiBLAST につきましては、このあと説明させていただきます。 実験には、特別教室の FreeBSD マシンを使用する予定です。遊休リソースを用いる実験ですので、基本的には使っているユーザーには影響はなく、日中や夜間など、使われているマシンの数などによって、パフォーマンスがどのように変わってくるのかなどを検証したいと考えています。 実験の評価ポイントですが、スケーラビリティ、ノード数やデータ量などを増やした場合にどの程度パフォーマンスが上がるのか、レスポンスタイムやスループットなどを評価しようと考えています。 #8 実際に BLAST ではどのような処理を行っているかについてですが、遺伝子データベースでは標準的な FASTA 形式、これはスライドの右側にあるようなフラットテキストのファイルですが、これを formatdb というコマンドを使って、 BLAST 形式のデータ形式に変換します。 そして、そのデータを用いて、ユーザーの検索したいクエリを検索し、ある一定以上のスコアを持つものを結果として出力します。 このデータベースは、ヒトゲノムデータの場合は 3GB 程度、さまざまな生物種のデータを統合したファイルの場合、現在のところ 10GB 程度となっています。 処理時間に関しましては、検索するクエリのサイズや数、データベースのサイズにもよりますが、バイオインフォマティシャンが網羅的な解析を行うような場合には、数時間から数日以上かかるような場合があります。ですから、この時間を何とか短縮したいというモチベーションがあるわけです。 #9 コンピュータシステムとして BLAST の処理内容を見てみると、検索するクエリが長い場合には、先ほどの類似度の計算などに時間がかかりますから、比較的 CPU を多く使う処理となります。 一方、検索するためのクエリの数が多い場合には、同じデータベースに何度も何度も少しずつ違うデータで検索をかけたりしますので、比較的 I/O 処理が多くなります。 このような特徴があるため、分散処理の評価サンプルとして適していると判断しました。 #10 遊休リソースコンピューティング、あるいは並列化 BLAST という観点から関連研究が存在します。遊休リソースコンピューティングとしては、 [email_address] や [email_address] 、並列化 BLAST としては、 mpiBLAST や HyperBLAST といった実装が存在しています。 #11 次に、既存の研究と、本研究の相違点について述べます。 インターネット上で分散して処理を行うものを、超分散遊休リソースコンピューティングとここでは呼びますが、既存のデータ解析を行うプロジェクトと比べて、 BLAST の場合にはデータベース検索ですので、反復処理、あるいは I/O 処理が非常に多く、分散化あるいは並列化した処理の独立性がさほど高くないという点が違いとなっています。 また、既存の並列化 BLAST は、すべて密に設計された PC クラスタを対象としており、 NFS などの技術を使っています。 よって、本研究では、従来広域分散で処理されていた遊休コンピューティングの手法を使い、 PC クラスタで実行されていたアプリケーションを、 LAN 内で分散して行わせ、その評価を行う、という点が、既存研究と違ってくることになります。 #12 次に、このような大規模なデータ処理を要するアプリケーションの分散処理を実装するにあたって、どのような方式があるのかについて簡単に解説いたします。 #13 まずは、ディスク共有型です。これは、 NFS などの I/O サービスを提供するファイルサーバを設置し、各計算用のノードは、このファイルサーバを通してデータの読み書きを行います。 この方式のメリットは、比較的簡単に構築できることですが、反面、計算用ノードを増やすとファイルサーバに負荷が集中するため、より高価な機材へのリプレースや、管理コストの上昇、あるいはファイルサーバに問題が発生すれば、クラスタシステム全体の性能や信頼性の低下といった状況を招くことになります。 #14 例えば、簡単なベンチマークを行ってみますと、ファイルサーバに置いてあるファイルをクライアントから一斉に読み出すといった場合、ノード数が増えるに従ってパフォーマンスが大きく低下します。この例ですと、 10 ノードを越えたあたりから急激にパフォーマンスが低下しているのが分かります。つまり、ファイルサーバの処理能力の限界まで達したため、これ以上計算用のノードを増やしたとしてもトータルとしてのパフォーマンスの向上はあまり見込めないということになります。 #15 お示ししているスライドは、 NFS 上で BLAST 処理を実行した場合、およびローカルディスク上で BLAST を実行した場合の、 CPU 利用率および実行時間の計測結果です。 比較すると歴然としているように、 NFS を用いた場合、ローカルディスク上で BLAST を実行するのに比べて、このケースですと 3 倍程度の時間がかかっています。 ローカルディスク上で BLAST を実行した場合と比べて、 CPU 利用率、ユーザーの利用率ですが、これが 1/3 程度となっており、 I/O 、つまり NFS が BLAST 処理に対して大きくボトルネックになっていることがうかがえます。 #16 これらのことから、 BLAST 処理のパフォーマンスを十分に引き出すためには、従来の PC クラスタなどにおける「 CPU 、演算処理の並列化」だけではなく、 I/O 処理を並列化し、その処理時間を低減する必要があります。 そのためには、従来の NFS に依存したアーキテクチャではなく、ローカルのストレージを活用すること、また検索処理の並列化、つまり I/O 処理の並列化によって、検索処理全体の実行時間を低減することが求められます。 #17 そこで考えたのが、ディスク分散型のアプローチです。 ディスク分散型の手法では、大容量のデータを細かく分割した上で、複数の計算ノード上のディスクに配置します。また、それぞれの計算ノードで必要となるデータについては、近隣のノードから peer to peer で転送する形を取ります。 このようなアーキテクチャを取ることによって、計算用のノードを増やしても、ファイルサーバに対して過大な負荷がかかるという事態を避けられ、またキャッシュの配置に冗長性を持たせることによって、同じデータに対するリクエストの負荷も分散することが可能になります。 今回は遊休リソースを用いる形になりますので、単に分割配置するだけではなく、ロードアベレージの把握、管理や、負荷の高い計算ノードから低いノードへのキャッシュの転送などといったことも考慮する必要が出てきます。 #18 次に、このような大規模なデータ処理を要するアプリケーションの分散処理を実装するにあたって、どのような方式があるのかについて簡単に解説いたします。 #19 このディスク分散のアプローチを用いて、並列化 BLAST 、 p-BLAST を設計しました。 #20 p-BLAST では、フラットなネットワークにおいて、フロントエンド、マスターノード、および複数のクライアントノードから構成されます。 フロントエンドは、実際にユーザーがプログラムを操作する端末で、マスターノードへリクエストを送ります。 マスターノードは、フロントエンドからの要求を処理し、必要に応じて分割してクライアントへ渡し、その結果をマージしてフロントエンドに返します。 クライアントノードでは、マスターノードから受け取ったタスクの処理や、およびクライアントノード同士のファイルの転送、クライアントノードの状態変化をマスターノードへの通知などを行います。 #27 最後に、具体的な評価項目ですが、分散処理ですので、ノード数やデータベースサイズとスケーラビリティ、またクエリ配列のサイズによるパフォーマンスの評価、ファイルサーバの I/O 処理量や、単一リクエストのレスポンスタイム、複数のリクエストの多重処理能力、スループットなどを評価ポイントとする予定です。







![関連研究 遊休リソースコンピューティング [email_address] RC5 [email_address] 並列化 BLAST mpiBLAST HyperBLAST Hi-per BLAST TurboBLAST](https://image.slidesharecdn.com/20040204slides-091101094643-phpapp02/75/slide-9-2048.jpg)














































![[db tech showcase Tokyo 2014] B23: SSDとHDDの混在環境でのOracleの超効率的利用方法 by 株式会社日立製作...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b23ssdhddoracle-141127184658-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[WIP] pgDay Asia 2016](https://cdn.slidesharecdn.com/ss_thumbnails/pgdayasia-150619125004-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DDBJing31] 軽量仮想環境を用いてNGSデータの解析再現性を担保する](https://cdn.slidesharecdn.com/ss_thumbnails/31ddbjingohta-150626022623-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


























