紹介する論文
7
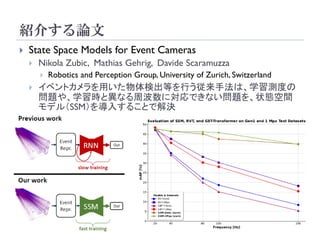
State SpaceModels for Event Cameras
Nikola Zubic, Mathias Gehrig, Davide Scaramuzza
Robotics and Perception Group, University of Zurich, Switzerland
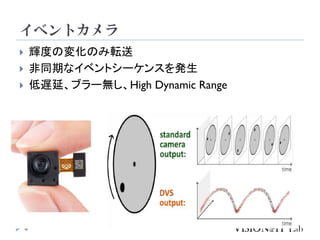
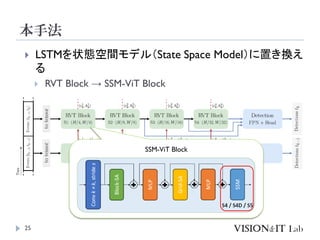
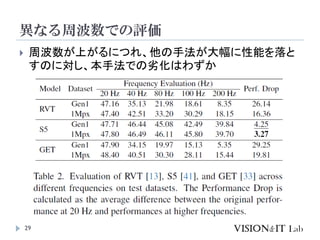
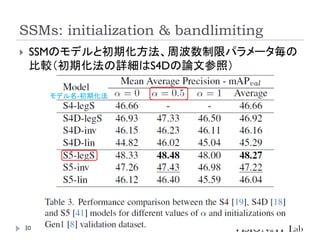
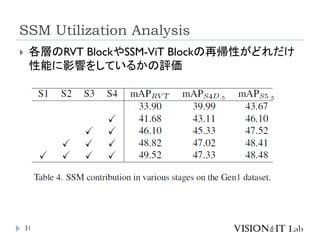
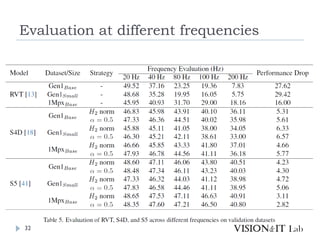
イベントカメラを用いた物体検出等を行う従来手法は、学習測度の
問題や、学習時と異なる周波数に対応できない問題を、状態空間
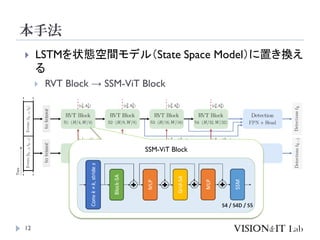
モデル(SSM)を導入することで解決
Related Work
9
Gehrig,M., & Scaramuzza, D. (2023). RecurrentVisionTransformers for
Object Detection with Event Cameras. Proceedings of the IEEE Computer
Society Conference on ComputerVision and Pattern Recognition (CVPR)
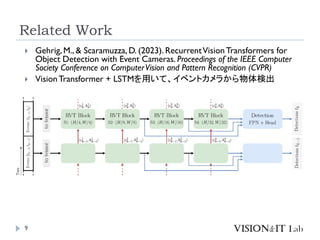
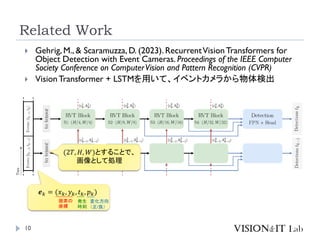
VisionTransformer + LSTMを用いて、イベントカメラから物体検出
9.
Related Work
10
Gehrig,M., & Scaramuzza, D. (2023). RecurrentVisionTransformers for
Object Detection with Event Cameras. Proceedings of the IEEE Computer
Society Conference on ComputerVision and Pattern Recognition (CVPR)
VisionTransformer + LSTMを用いて、イベントカメラから物体検出
𝒆𝑘 = (𝑥𝑘, 𝑦𝑘, 𝑡𝑘, 𝑝𝑘)
画素の
座標
発生
時刻
変化方向
(正/負)
(2𝑇, 𝐻, 𝑊)とすることで、
画像として処理
10.
Related Work
11
Gehrig,M., & Scaramuzza, D. (2023). RecurrentVisionTransformers for
Object Detection with Event Cameras. Proceedings of the IEEE Computer
Society Conference on ComputerVision and Pattern Recognition (CVPR)
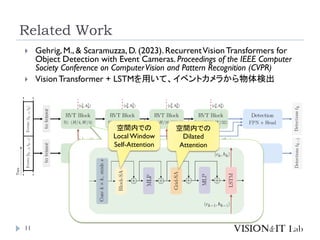
VisionTransformer + LSTMを用いて、イベントカメラから物体検出
空間内での
Local Window
Self-Attention
空間内での
Dilated
Attention
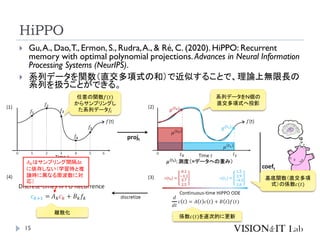
HiPPO
14
Gu,A., Dao,T.,Ermon, S., Rudra,A., & Ré, C. (2020). HiPPO: Recurrent
memory with optimal polynomial projections.Advances in Neural Information
Processing Systems (NeurIPS).
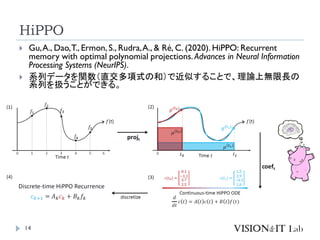
系列データを関数(直交多項式の和)で近似することで、理論上無限長の
系列を扱うことができる。
14.
HiPPO
15
Gu,A., Dao,T.,Ermon, S., Rudra,A., & Ré, C. (2020). HiPPO: Recurrent
memory with optimal polynomial projections.Advances in Neural Information
Processing Systems (NeurIPS).
系列データを関数(直交多項式の和)で近似することで、理論上無限長の
系列を扱うことができる。
任意の関数𝑓(𝑡)
からサンプリングし
た系列データ𝑓𝑖
系列データをN個の
直交多項式へ投影
𝜇(𝑡𝑖)
: 測度(=データへの重み)
基底関数(直交多項
式)の係数𝑐(𝑡)
係数𝑐(𝑡)を逐次的に更新
離散化
𝐴𝑘はサンプリング間隔∆t
に依存しない(学習時と推
論時に異なる周波数に対
応)
15.
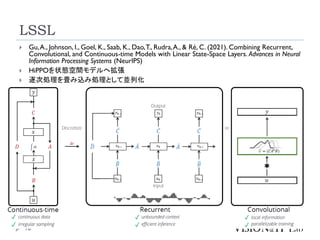
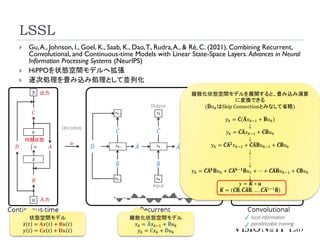
LSSL
16
Gu,A., Johnson,I., Goel, K., Saab, K., Dao,T., Rudra,A., & Ré, C. (2021). Combining Recurrent,
Convolutional, and Continuous-time Models with Linear State-Space Layers. Advances in Neural
Information Processing Systems (NeurIPS)
HiPPOを状態空間モデルへ拡張
逐次処理を畳み込み処理として並列化
16.
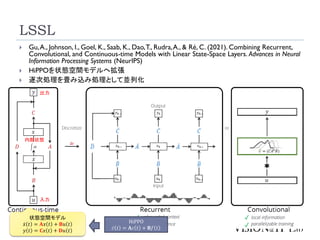
LSSL
17
Gu,A., Johnson,I., Goel, K., Saab, K., Dao,T., Rudra,A., & Ré, C. (2021). Combining Recurrent,
Convolutional, and Continuous-time Models with Linear State-Space Layers. Advances in Neural
Information Processing Systems (NeurIPS)
HiPPOを状態空間モデルへ拡張
逐次処理を畳み込み処理として並列化
状態空間モデル
ሶ
𝑥 𝑡 = 𝐀𝑥 𝑡 + 𝐁𝑢 𝑡
𝑦 𝑡 = 𝐂𝑥 𝑡 + 𝐃𝑢 𝑡
入力
内部状態
出力
HiPPO
ሶ
𝑐 𝑡 = 𝐀𝑐 𝑡 + 𝐁𝑓 𝑡
17.
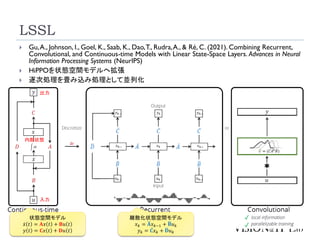
LSSL
18
Gu,A., Johnson,I., Goel, K., Saab, K., Dao,T., Rudra,A., & Ré, C. (2021). Combining Recurrent,
Convolutional, and Continuous-time Models with Linear State-Space Layers. Advances in Neural
Information Processing Systems (NeurIPS)
HiPPOを状態空間モデルへ拡張
逐次処理を畳み込み処理として並列化
状態空間モデル
ሶ
𝑥 𝑡 = 𝐀𝑥 𝑡 + 𝐁𝑢 𝑡
𝑦 𝑡 = 𝐂𝑥 𝑡 + 𝐃𝑢 𝑡
入力
内部状態
出力
離散化状態空間モデル
𝑥𝑘 = ഥ
𝐀𝑥𝑘−1 + ഥ
𝐁𝑢𝑘
𝑦𝑘 = ҧ
𝐂𝑥𝑘 + ഥ
𝐃𝑢𝑘
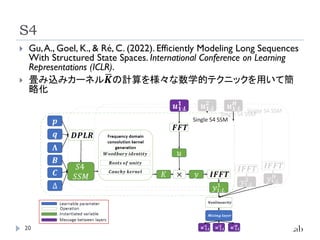
S4
20
Gu,A., Goel,K., & Ré, C. (2022). Efficiently Modeling Long Sequences
With Structured State Spaces. International Conference on Learning
Representations (ICLR).
畳み込みカーネルഥ
𝑲の計算を様々な数学的テクニックを用いて簡
略化
20.
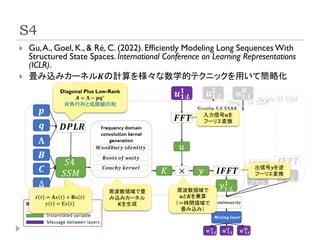
S4
21
Gu,A., Goel,K., & Ré, C. (2022). Efficiently Modeling Long SequencesWith
Structured State Spaces. International Conference on Learning Representations
(ICLR).
畳み込みカーネル𝑲の計算を様々な数学的テクニックを用いて簡略化
Diagonal Plus Low-Rank
𝑨 = 𝚲 − 𝒑𝒒∗
対角行列と低階級の和
ሶ
𝑥 𝑡 = 𝐀𝑥 𝑡 + 𝐁𝑢 𝑡
𝑦 𝑡 = 𝐂𝑥 𝑡
周波数領域で畳
み込みカーネル
𝑲を生成
周波数領域で
𝒖と𝑲を乗算
(=時間領域で
畳み込み)
入力信号𝒖を
フーリエ変換
出信号𝒚を逆
フーリエ変換
21.
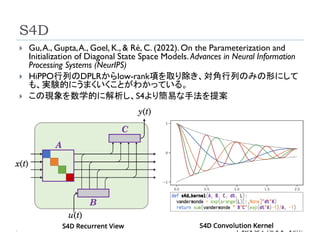
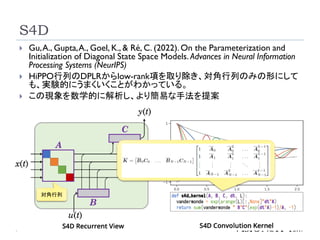
S4D
22
Gu,A., Gupta,A.,Goel, K., & Ré, C. (2022). On the Parameterization and
Initialization of Diagonal State Space Models. Advances in Neural Information
Processing Systems (NeurIPS)
HiPPO行列のDPLRからlow-rank項を取り除き、対角行列のみの形にして
も、実験的にうまくいくことがわかっている。
この現象を数学的に解析し、S4より簡易な手法を提案
22.
S4D
23
Gu,A., Gupta,A.,Goel, K., & Ré, C. (2022). On the Parameterization and
Initialization of Diagonal State Space Models. Advances in Neural Information
Processing Systems (NeurIPS)
HiPPO行列のDPLRからlow-rank項を取り除き、対角行列のみの形にして
も、実験的にうまくいくことがわかっている。
この現象を数学的に解析し、より簡易な手法を提案
対角行列
23.
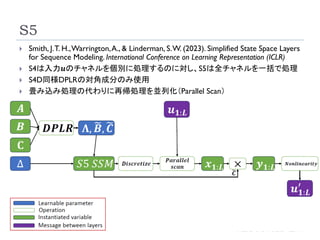
S5
24
Smith, J.T.H.,Warrington,A., & Linderman, S.W. (2023). Simplified State Space Layers
for Sequence Modeling. International Conference on Learning Representation (ICLR)
S4は入力𝒖のチャネルを個別に処理するのに対し、S5は全チャネルを一括で処理
S4D同様DPLRの対角成分のみ使用
畳み込み処理の代わりに再帰処理を並列化(Parallel Scan)





















![[DL輪読会] Learning Finite State Representations of Recurrent Policy Networks (I...](https://cdn.slidesharecdn.com/ss_thumbnails/20190830kaitosuzuki-190902060756-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)


































