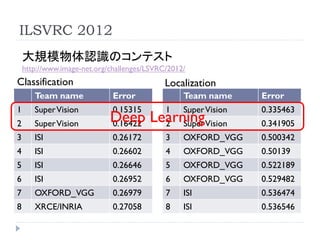
ILSVRC 2012
大規模物体認識のコンテスト
http://www.image-net.org/challenges/LSVRC/2012/
Classification Localization
Team name Error Team name Error
1 Super Vision 0.15315 1 Super Vision 0.335463
2 Super Vision Deep LearningVision
0.16422 2 Super 0.341905
3 ISI 0.26172 3 OXFORD_VGG 0.500342
4 ISI 0.26602 4 OXFORD_VGG 0.50139
5 ISI 0.26646 5 OXFORD_VGG 0.522189
6 ISI 0.26952 6 OXFORD_VGG 0.529482
7 OXFORD_VGG 0.26979 7 ISI 0.536474
8 XRCE/INRIA 0.27058 8 ISI 0.536546
4.
Super Vision
Our model is a large, deep convolutional neural
network trained on raw RGB pixel values. The neural
network, which has 60 million parameters and 650,000
neurons, consists of five convolutional layers, some of
which are followed by max-pooling layers, and three
globally-connected layers with a final 1000-way softmax. It
was trained on two NVIDIA GPUs for about a week. To
make training faster, we used non-saturating neurons and
a very efficient GPU implementation of convolutional nets.
To reduce overfitting in the globally-connected layers we
employed hidden-unit "dropout", a recently-developed
regularization method that proved to be very effective.
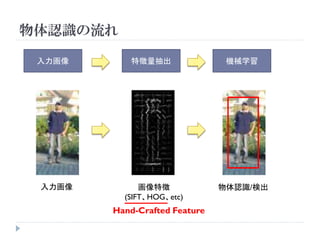
Deep Learning
Hand-craftedな特徴量を
用いず、特徴量を画素か
ら統計的に学習する。
低レベル特徴から高レベ
ル特徴までの階層構造。
低レベルな特徴ほど、
様々なタスクで共有可能
主な手法
Deep Belief Networks
Deep Bolzmann Machines
Deep Neural Networks
Super Vision
(Image from Lee. H in CVPR2012 Tutorial)
紹介する論文
Building High-level Features Using Large Scale
Unsupervised Learning
International Conference on Machine Learning
(ICML) 2012
Quac V. Le (Stanford)
Marc’ Aurelio Ranzato (Google)
Rajat Monga (Google)
Matthieu Devin (Google)
Kai Chen (Google)
Greg S. Corrado (Google)
Jeff Dean (Google)
Andrew Y. Ng (Stanford)
12.
紹介する論文
Building High-level Features Using Large Scale
Unsupervised Learning
ラベルがついていない画像だけを使って、特定
の種類の物体に反応する、高レベルの特徴検出
器を生成できないか?
例:顔認識
「おばあさんニューロン」
Deep Learningは莫大な時間がかかる
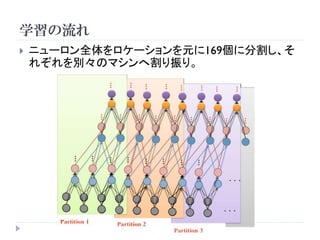
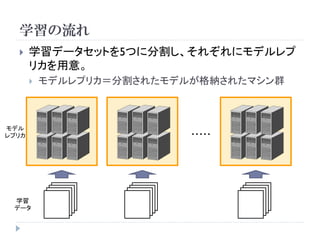
1000万枚の画像を16コアのマシン1000台で学習
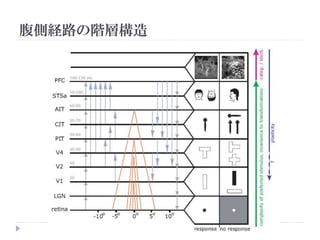
Deep Neural Network
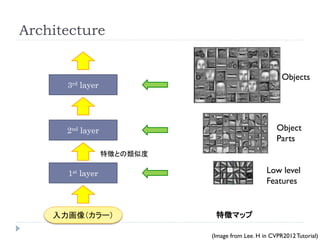
Architecture
Objects
3rd layer
2nd layer Object
Parts
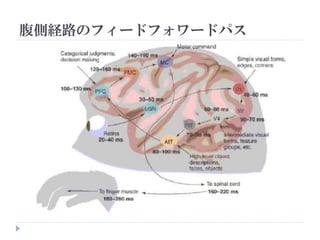
特徴との類似度
1st layer Low level
Features
入力画像(カラー) 特徴マップ
(Image from Lee. H in CVPR2012 Tutorial)
15.
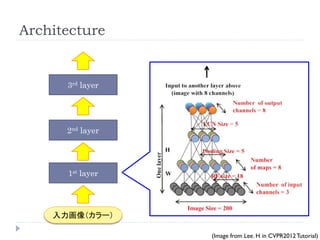
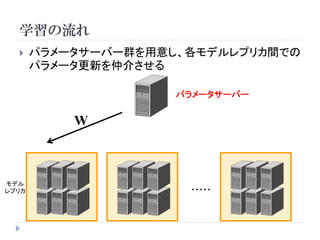
Architecture
3rd layer
2nd layer
1st layer
入力画像(カラー)
(Image from Lee. H in CVPR2012 Tutorial)
16.
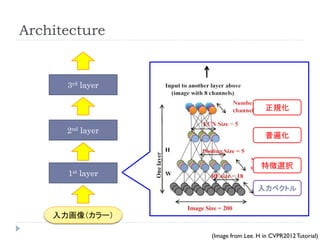
Architecture
3rd layer
正規化
2nd layer
普遍化
特徴選択
1st layer
入力ベクトル
入力画像(カラー)
(Image from Lee. H in CVPR2012 Tutorial)
17.
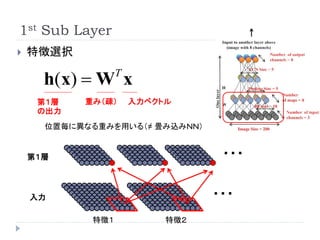
1st Sub Layer
特徴選択
h(x) W x T
第1層 重み(疎) 入力ベクトル
の出力
位置毎に異なる重みを用いる(≠ 畳み込みNN)
第1層 ・・・
入力 ・・・
特徴1 特徴2
18.
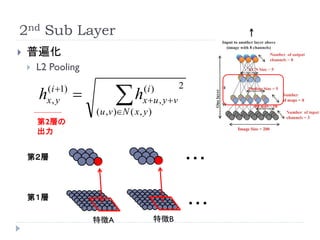
2nd Sub Layer
普遍化
L2 Pooling
h
( i 1) 2
h x, y (i )
x u , y v
( u ,v )N ( x , y )
第2層の
出力
第2層 ・・・
第1層
・・・
特徴A 特徴B
19.
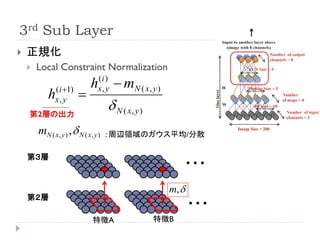
3rd Sub Layer
正規化
Local Constraint Normalization
( i 1)
h (i )
mN ( x , y )
x, y
h
N ( x, y )
x, y
第2層の出力
mN ( x, y ) , N ( x, y ) : 周辺領域のガウス平均/分散
第3層
・・・
m,
第2層
・・・
特徴A 特徴B
20.
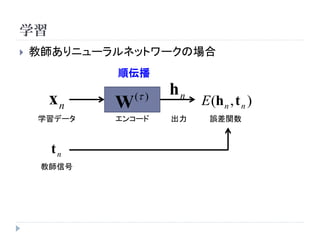
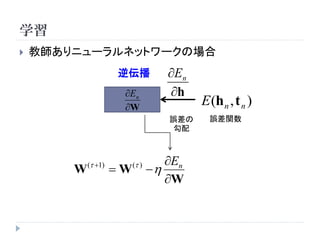
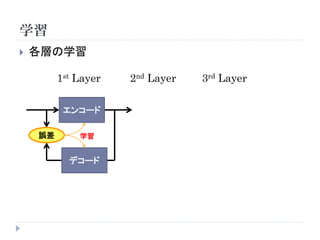
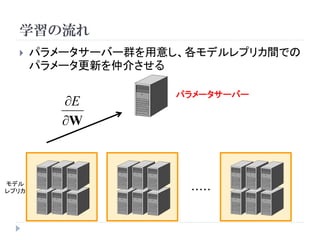
学習
教師ありニューラルネットワークの場合
順伝播
( ) hn
xn W E (h n , t n )
学習データ エンコード 出力 誤差関数
tn
教師信号
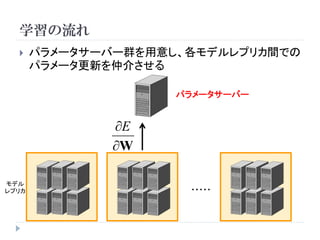
21.
学習
教師ありニューラルネットワークの場合
逆伝播 En
( ) h
W E (h n , t n )
誤差の 誤差関数
勾配
22.
学習
教師ありニューラルネットワークの場合
逆伝播 En
En h
W
E (h n , t n )
誤差の 誤差関数
勾配
( 1) ( ) En
W W
W
23.
学習
教師ありニューラルネットワークの場合
逆伝播 En
( 1) h
W E (h n , t n )
誤差の 誤差関数
勾配
( 1) ( ) En
W W
W
24.
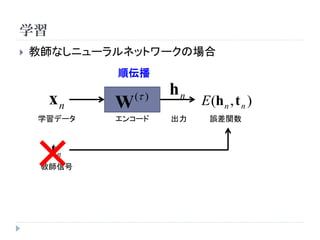
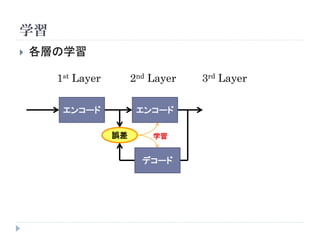
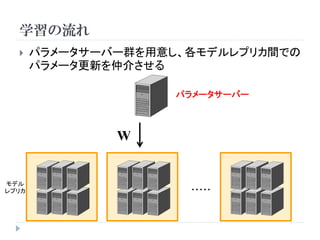
学習
教師なしニューラルネットワークの場合
順伝播
( ) hn
xn W E (h n , t n )
学習データ エンコード 出力 誤差関数
× tn
教師信号
25.
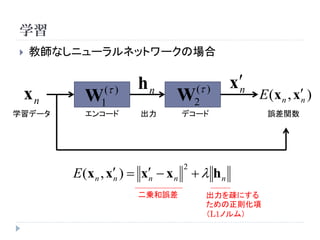
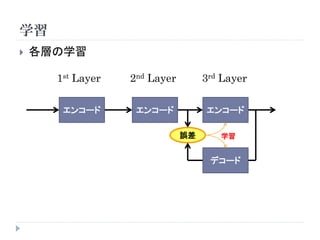
学習
教師なしニューラルネットワークの場合
( ) hn ( ) xn
xn W 1 W 2
E (x n , xn )
学習データ エンコード 出力 デコード 誤差関数
E (x n , x ) x x n h n
2
n n
二乗和誤差 出力を疎にする
ための正則化項
(L1ノルム)
26.
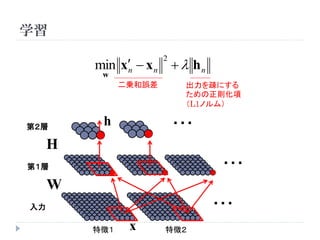
学習
min x x n h n
2
n
w
二乗和誤差 出力を疎にする
ための正則化項
(L1ノルム)
第2層
h ・・・
H
第1層 ・・・
W
入力 ・・・
特徴1 x 特徴2
27.
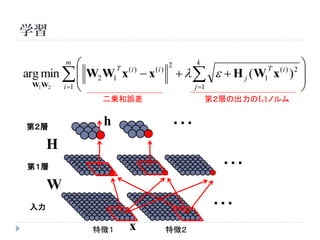
学習
m k
T (i ) 2
arg min W2 W1 x x H j ( W1 x )
T (i ) 2
(i )
W1W2 i 1 j 1
二乗和誤差 第2層の出力のL1ノルム
第2層
h ・・・
H
第1層 ・・・
W
入力 ・・・
特徴1 x 特徴2
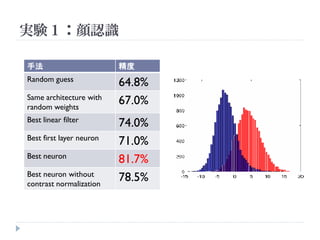
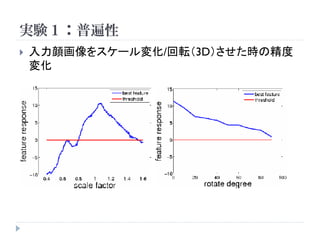
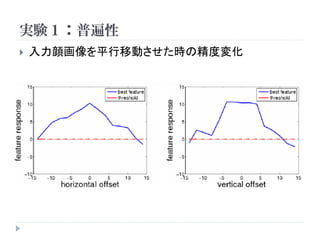
実験1:顔認識
手法 精度
Random guess
64.8%
Same architecture with
random weights
67.0%
Best linear filter
74.0%
Best first layer neuron
71.0%
Best neuron
81.7%
Best neuron without
contrast normalization
78.5%
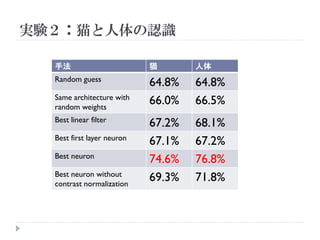
実験2:猫と人体の認識
猫と人の映像はYouTubeでも一般的なため、ニューロン
がこれらを学習していないかを調べる
猫の顔画像データセット
Zhang et al., “Cat head detection – how to effectively exploit shape
and texture features”, ECCV2008
10,000枚の正解画像、18,409枚の非正解画像
人体データセット
Keller et al., “A new bench-mark for stereo-based pedestrian
detection”, the IEEE Intelligent Vehicles Symposium 2009
上記データセットのサブセットを使用
13,026枚の正解画像、23,974枚の非正解画像
実験方法は顔と同じ
47.
実験2:猫と人体の認識
手法 猫 人体
Random guess
64.8% 64.8%
Same architecture with
random weights
66.0% 66.5%
Best linear filter
67.2% 68.1%
Best first layer neuron
67.1% 67.2%
Best neuron
74.6% 76.8%
Best neuron without
contrast normalization
69.3% 71.8%
参考資料
R. Fergus et al., “Deep Learning Methods for Vision”,
CVPR2012 Tutorial
http://cs.nyu.edu/~fergus/tutorials/deep_learning_cvpr12/
T. Serre, “Learning a Dictionary of Shape-Components in
Visual Cortex: Comparison with Neurons, Humans and
Machines”, Brain and Cognitive Science, 2006



































































![[DL輪読会]"Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10,0...](https://cdn.slidesharecdn.com/ss_thumbnails/wakasugi-180824003300-thumbnail.jpg?width=640&height=640&fit=bounds)




























