Recommended
PDF
Convolutional Neural Network @ CV勉強会関東
PDF
PPTX
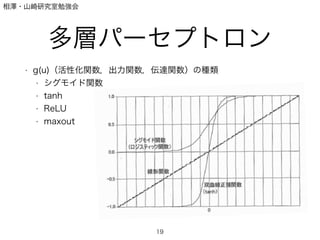
多層NNの教師なし学習� コンピュータビジョン勉強会@関東 2014/5/26
PPTX
Cvim saisentan-6-4-tomoaki
PDF
Overcoming Catastrophic Forgetting in Neural Networks読んだ
PPTX
DLフレームワークChainerの紹介と分散深層強化学習によるロボット制御
PDF
PPTX
PPT
PDF
PythonによるDeep Learningの実装
PPTX
PPTX
MIRU2014 tutorial deeplearning
PDF
Learning to forget continual prediction with lstm
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
PPTX
PDF
LSTM (Long short-term memory) 概要
PDF
PPTX
[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions
PDF
Deep Learningと画像認識� �~歴史・理論・実践~
PDF
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
PDF
再帰型ニューラルネット in 機械学習プロフェッショナルシリーズ輪読会
PPTX
NIPS2015読み会: Ladder Networks
PDF
Introduction to Deep Compression
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
PDF
PDF
PDF
PDF
Building High-level Features Using Large Scale Unsupervised Learning
PDF
More Related Content
PDF
Convolutional Neural Network @ CV勉強会関東
PDF
PPTX
多層NNの教師なし学習� コンピュータビジョン勉強会@関東 2014/5/26
PPTX
Cvim saisentan-6-4-tomoaki
PDF
Overcoming Catastrophic Forgetting in Neural Networks読んだ
PPTX
DLフレームワークChainerの紹介と分散深層強化学習によるロボット制御
PDF
PPTX
What's hot
PPT
PDF
PythonによるDeep Learningの実装
PPTX
PPTX
MIRU2014 tutorial deeplearning
PDF
Learning to forget continual prediction with lstm
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
PPTX
PDF
LSTM (Long short-term memory) 概要
PDF
PPTX
[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions
PDF
Deep Learningと画像認識� �~歴史・理論・実践~
PDF
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
PDF
再帰型ニューラルネット in 機械学習プロフェッショナルシリーズ輪読会
PPTX
NIPS2015読み会: Ladder Networks
PDF
Introduction to Deep Compression
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
PDF
PDF
PDF
Similar to 2014/5/29 東大相澤山崎研勉強会:パターン認識とニューラルネットワーク,Deep Learningまで
PDF
Building High-level Features Using Large Scale Unsupervised Learning
PDF
PPTX
PDF
(2022年3月版)深層学習によるImage Classificaitonの発展
PPTX
深層学習の数理:カーネル法, スパース推定との接点
PDF
PDF
NVIDIA Seminar ディープラーニングによる画像認識と応用事例
PDF
PDF
Convolutional Neural Networks のトレンド @WBAFLカジュアルトーク#2
PDF
NN, CNN, and Image Analysis
PDF
PDF
(2021年8月版)深層学習によるImage Classificaitonの発展
PDF
PPTX
PPTX
Image net classification with Deep Convolutional Neural Networks
PDF
Deep learningの概要とドメインモデルの変遷
PPTX
PRML 5.5.6-5.6 畳み込みネットワーク(CNN)・ソフト重み共有・混合密度ネットワーク
PDF
PDF
PDF
2014/5/29 東大相澤山崎研勉強会:パターン認識とニューラルネットワーク,Deep Learningまで 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 相澤・山崎研究室勉強会
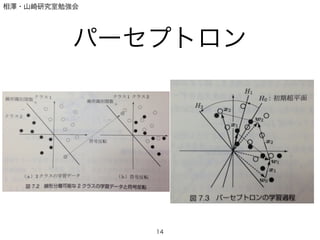
Back propagation
• Case 1 最小二乗誤差を誤差関数に取る場合(回帰問題に使うことが
多い)
22
E(w) =
1
2
N
n=1
K
k=1
(tn
k yn
k )2
tn
k は教師信号,yn
k は MLP の出力.
それを出力ユニット分足しあわせたものを,全データ分足す
wkj( + 1) = wkj( ) + wkj( )
一般にこの修正を何度も繰り返すので, はイテレーション回数を示す.
23. 相澤・山崎研究室勉強会
Back propagation
• Case 1 最小二乗誤差を誤差関数に取る場合(回帰問題に使うことが
多い)
23
wkj( ) =
N
n=1
En(w)
wkj
=
N
n=1
En(w)
yn
k
yn
k
wkj
=
N
n=1
(tn
k yn
k )˜g (yn
k,in)V n
j,out
where En(w) =
1
2
K
k=1
(tn
k yn
k )2
24. 相澤・山崎研究室勉強会
Back propagation
• Case 1 最小二乗誤差を誤差関数に取る場合(回帰問題に使うことが
多い)
24
ここで, n
k = (tn
k yn
k )˜g (yn
k,in) とおくと
N
n=1
(tn
k yn
k )˜g (yn
k,in)V n
j,out =
N
n=1
n
k V n
j,out
※これで出力層終わり
25. 26. 27. 28. 相澤・山崎研究室勉強会
MLP w/ BP+GDの問題
• 1. 初期値依存性
• 局所最適解が大量に含まれる誤差関数を最適化するので,初期値
によって り着く局所解が違う
!
• 2. 過学習
• 隠れ素子の数が多くなったり,活性化関数がサチったりでノイズ
に適合し始めると,過学習が起こる
• 対策として,early stoppingやL2正則化などが行われているが,
一番効くのはデータ数を増やすこと
28
29. 30. 31. 相澤・山崎研究室勉強会
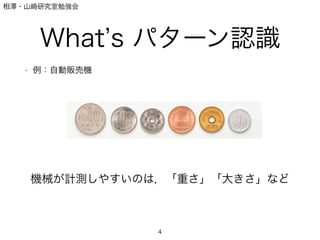
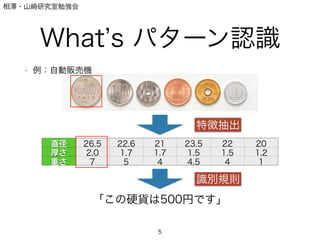
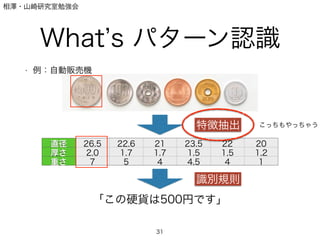
What s パターン認識
• 例:自動販売機
31
直径 26.5 22.6 21 23.5 22 20
厚さ 2.0 1.7 1.7 1.5 1,5 1,2
重さ 7 5 4 4.5 4 1
「この硬貨は500円です」
特徴抽出
識別規則
こっちもやっちゃう
32. 相澤・山崎研究室勉強会
Deep Learning
• Full-Connected + Pre-traning系
• ネットで探してDeep Learningって言われがちなのはこっち
• フル接続の多層NNは誤差が分散してしまって性能が上がらなかっ
たが,事前学習を取り入れることでそれを回避
• Deep Belief NetsやStacked Denoising Autoencodersなどが
知られている
!
• CNN系
• 事前学習なし,局所受容野の考え方を取り入れることで過学習の
回避
• 画像に向いている(らしい)
32
33. 34. 35. 36. 相澤・山崎研究室勉強会
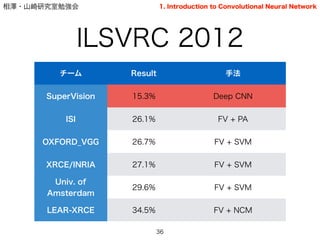
ILSVRC 2012
36
チーム Result 手法
SuperVision 15.3% Deep CNN
ISI 26.1% FV + PA
OXFORD_VGG 26.7% FV + SVM
XRCE/INRIA 27.1% FV + SVM
Univ. of
Amsterdam
29.6% FV + SVM
LEAR-XRCE 34.5% FV + NCM
1. Introduction to Convolutional Neural Network
37. 相澤・山崎研究室勉強会
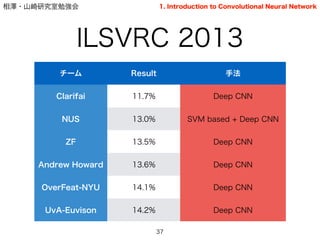
ILSVRC 2013
37
チーム Result 手法
Clarifai 11.7% Deep CNN
NUS 13.0% SVM based + Deep CNN
ZF 13.5% Deep CNN
Andrew Howard 13.6% Deep CNN
OverFeat-NYU 14.1% Deep CNN
UvA-Euvison 14.2% Deep CNN
1. Introduction to Convolutional Neural Network
38. 39. 相澤・山崎研究室勉強会
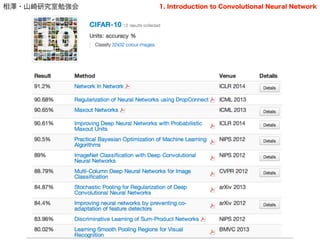
Other dataset..
• CIFAR-10
• CIFAR-100
• Network in Network , ICLR 2014
!
• MNIST
• Regularization of Neural Networks using DropConnect ,
ICML, 2013
39
全てCNN
(が基にある)
1. Introduction to Convolutional Neural Network
40. 相澤・山崎研究室勉強会
知識の流れ
Hubel and Wiesel [1962]
(単純細胞,複雑細胞,局所受容野)
!
!
Fukushima [1980]
(Neocognitron)
!
!
LeCun [1989, 1998]
(Convolutional Neural Network→手書き文字認識への応用)
40
1. Introduction to Convolutional Neural Network
41. 相澤・山崎研究室勉強会
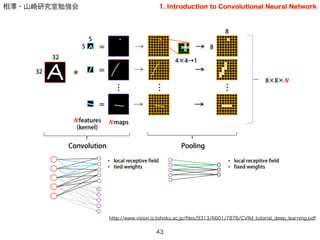
基本構造
41
2 3 5
6 7 4
1 7 3
Convolution(畳み込み)
2 3 5
6 7 4
1 7 3
2 3 5
6 7 4
1 7 3
Pooling(プーリング,適切な日本語訳なし?)
※画像はイメージです
2 3 5
6 7 4
1 7 3
1. Introduction to Convolutional Neural Network
※画像はイメージです
いわゆる移動フィルタの形で,画像を移動しながら注目画素の周
辺の画素値を用いて計算.このフィルタをたくさん用意する
(フィルタ=重み行列が局所的)
42. 43. 44. 45. 46. 47. 48. 49. 50. 相澤・山崎研究室勉強会
Pooling
50
2. The Detail of Conventional CNN Techniques
• Max pooling
!
!
!
• Avg. pooling (平均プーリング)
!
!
!
• (一般の) Pooling
hi,k+1 = max
j2Pi,k
hj
hi,k+1 =
1
|Pi|
X
j2Pi
hj
hi,k+1 =
✓
1
|Pi|
X
j2Pi
hp
j
◆1
p
p=1 avg
p= max
※実際にはavg∼maxのつなぎ方は他にもあり,詳細は[Boureau, ICML 2010]を参照
51. 相澤・山崎研究室勉強会
Pooling
51
2. The Detail of Conventional CNN Techniques
• 結局どれがいいのか
• [Boureau, CVPR 2010及びICML 2010]に詳しい議論
• Cardinality(プーリングサイズ)による
• 直感的には・・
• 元画像に対し,広い部分を扱うときは平均プーリング,小さい部分
の時はmaxの方が良い?
52. 53. 相澤・山崎研究室勉強会
局所コントラスト正規化
53
2. The Detail of Conventional CNN Techniques
• 発端は?:計算神経科学(哺乳類の初期視覚野のモデル)
• 脳のニュートンによる情報伝達はパルス数によって制限(有限)
• どうやってやる?:減算初期化と除算初期化
• どちらかというと除算が重要か(?)
!
• 意味は?:
• ①上記の脳の初期視覚野のモデルを表現
• ②複雑視覚野におけるニュ―ロンの選択性がコントラストに非
依存であることの説明
54. 相澤・山崎研究室勉強会
局所コントラスト正規化
54
2. The Detail of Conventional CNN Techniques
• 減算正規化
!
!
!
!
• 除算正規化
¯hi,j,k = hj,k
X
i,p,q
wp,qhi,j+p,k+q
h : 前層の出力
j, k : 画素
i : フィルタ番号
w : 平均を調整するための重み
c : 定数
h0
i,j,k =
¯hi,j,k
q
c +
P
i,p,q wp,q
¯h2
i,j+p,k+q
文献によっては,減算をしていないもの [Krizhevsky 2012]もある
また,いくつかのフィルタにまたがる場合(across map)とまたがらない場合がある
55. 56. 57. 相澤・山崎研究室勉強会
なぜ学習がうまくいくのか?
• Bengio「Although deep supervised neural networks were generally found
too difficult to train before the use of unsupervised pre-training, there is one
notable exception: convolutional neural networks.」[Bengio, 2009]
!
• 一般に多層のNNは過学習を起こす
• なぜCNNはOK?
!
• One untested hypothesis by Bengio
• 入力数(fan-in)が少ないと誤差なく勾配伝搬する?
• 局所的に接続された階層構造は認識タスクに向いている?
• FULL < Random CNN < Supervised CNN
57
3. Other Topic
58. 相澤・山崎研究室勉強会
DropOut
• DropOut [Hinton et al., 2012]
• 学習時に,中間層の出力の50%をrandomに0にする
• 一時的に依存関係を大幅に減らすことで,強い正則化の効果があ
る
• 一般化→DropConnect [Wan et al., 2013]
• 50% -> (1-p)%
• Sparseな接続の重み行列に
58
3. Other Topic
59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 相澤・山崎研究室勉強会
後半の参考資料(updated)
• 論文
• Krizhevsky et al., ImageNet Classification with Deep Convolutional Neural Networks, NIPS, 2012
• LeCun et al., Gradient-Based Learning Applied to Document Recognition, Proc. of IEEE, 1998
• [20][21][22]
!
• 日本語スライド
• http://www.slideshare.net/koji_matsuda/practical-recommendation-fordeeplearning
• http://www.slideshare.net/kazoo04/deep-learning-15097274
• http://www.slideshare.net/yurieoka37/ss-28152060 (実装に詳しい)
• http://www.slideshare.net/mokemokechicken/pythondeep-learning (実際にアプリケーション
を作成した例)
!
• 海外チュートリアル
• CVPR 2013のTutorialはCNNに焦点があたっている(GoogleのRanzato氏)
• ICML 2013, CVPR 2012等も参考になる
68
69.





























![相澤・山崎研究室勉強会
知識の流れ
Hubel and Wiesel [1962]
(単純細胞,複雑細胞,局所受容野)
!
!
Fukushima [1980]
(Neocognitron)
!
!
LeCun [1989, 1998]
(Convolutional Neural Network→手書き文字認識への応用)
40
1. Introduction to Convolutional Neural Network](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-40-320.jpg)

![相澤・山崎研究室勉強会
全体構造
• 基本的にはこの2層を繰り返すことで成り立つ.
• 最終層は出力層として,ソフトマックス関数を置くことが多い(分類
問題の場合)
• そこにいたるいくつかの層はフル接続とすることが多い.
44
1. Introduction to Convolutional Neural Network
LeNet-5 [LeCun, 1998]](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-44-320.jpg)


![相澤・山崎研究室勉強会
全体構造(再掲)
• 基本的にはこの2層を繰り返すことで成り立つ.
• 最終層は出力層として,ソフトマックス関数を置くことが多い(分類
問題の場合)
• そこにいたるいくつかの層はフル接続とすることが多い.
47
1. Introduction to Convolutional Neural Network
LeNet-5 [LeCun, 1998]](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-47-320.jpg)
![相澤・山崎研究室勉強会
Convolutionは先ほど説明したとおりだが…
!
☆いくつカーネル(フィルタ)を用意する?
☆カーネルのサイズは?
☆「端っこ」の扱いは?
☆活性化関数は?
☆重みやバイアスの決定は?
☆フィルタの動かし方は?
Convolution
48
2. The Detail of Conventional CNN Techniques
[conv]
type=conv
inputs=data
channels=3
filters=32
padding=4
stride=1
filterSize=9
neuron=logistic
initW=0.00001
initB=0.5](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-48-320.jpg)
![相澤・山崎研究室勉強会
• 直感的にはある程度の領域を「まとめる」ことで位置情報を捨て,
変化に対してロバストにする作業のこと.
• 広義では,抽出した生の特徴表現を,認識に必要な部分だけ残す
ような新たな表現に変換すること.
!
!
• 無意識に多く使われている
• 「最大値をとる」「平均をとる」「(語弊あるが)まとめる」
• 要素技術しかり,アルゴリズム全体然り
• ex)
SIFT[Lowe 99], Bag of Features[], Spatial Pyramid[],
Object Bank[2010],
Pooling
49
2. The Detail of Conventional CNN Techniques](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-49-320.jpg)
![相澤・山崎研究室勉強会
Pooling
50
2. The Detail of Conventional CNN Techniques
• Max pooling
!
!
!
• Avg. pooling (平均プーリング)
!
!
!
• (一般の) Pooling
hi,k+1 = max
j2Pi,k
hj
hi,k+1 =
1
|Pi|
X
j2Pi
hj
hi,k+1 =
✓
1
|Pi|
X
j2Pi
hp
j
◆1
p
p=1 avg
p= max
※実際にはavg∼maxのつなぎ方は他にもあり,詳細は[Boureau, ICML 2010]を参照](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-50-320.jpg)
![相澤・山崎研究室勉強会
Pooling
51
2. The Detail of Conventional CNN Techniques
• 結局どれがいいのか
• [Boureau, CVPR 2010及びICML 2010]に詳しい議論
• Cardinality(プーリングサイズ)による
• 直感的には・・
• 元画像に対し,広い部分を扱うときは平均プーリング,小さい部分
の時はmaxの方が良い?](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-51-320.jpg)
![相澤・山崎研究室勉強会
☆プーリング開始画素は?
☆プーリングサイズは?(Overlap)
☆動かす幅は?(Overlap)
☆活性化関数は?
☆プーリングの種類は?
Pooling
52
2. The Detail of Conventional CNN Techniques
[pool]
type=pool
pool=max
inputs=local32
start=0
sizeX=4
stride=2
outputsX=0
channels=32
neuron=relu](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-52-320.jpg)

![相澤・山崎研究室勉強会
局所コントラスト正規化
54
2. The Detail of Conventional CNN Techniques
• 減算正規化
!
!
!
!
• 除算正規化
¯hi,j,k = hj,k
X
i,p,q
wp,qhi,j+p,k+q
h : 前層の出力
j, k : 画素
i : フィルタ番号
w : 平均を調整するための重み
c : 定数
h0
i,j,k =
¯hi,j,k
q
c +
P
i,p,q wp,q
¯h2
i,j+p,k+q
文献によっては,減算をしていないもの [Krizhevsky 2012]もある
また,いくつかのフィルタにまたがる場合(across map)とまたがらない場合がある](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-54-320.jpg)
![相澤・山崎研究室勉強会
局所コントラスト正規化
55
2. The Detail of Conventional CNN Techniques
• 具体的な効果は?:
• improves invariance
• improves optimization
• increase sparsity [以上,Ranzato, CVPR 2013 Tutorial]](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-55-320.jpg)

![相澤・山崎研究室勉強会
なぜ学習がうまくいくのか?
• Bengio「Although deep supervised neural networks were generally found
too difficult to train before the use of unsupervised pre-training, there is one
notable exception: convolutional neural networks.」[Bengio, 2009]
!
• 一般に多層のNNは過学習を起こす
• なぜCNNはOK?
!
• One untested hypothesis by Bengio
• 入力数(fan-in)が少ないと誤差なく勾配伝搬する?
• 局所的に接続された階層構造は認識タスクに向いている?
• FULL < Random CNN < Supervised CNN
57
3. Other Topic](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-57-320.jpg)
![相澤・山崎研究室勉強会
DropOut
• DropOut [Hinton et al., 2012]
• 学習時に,中間層の出力の50%をrandomに0にする
• 一時的に依存関係を大幅に減らすことで,強い正則化の効果があ
る
• 一般化→DropConnect [Wan et al., 2013]
• 50% -> (1-p)%
• Sparseな接続の重み行列に
58
3. Other Topic](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-58-320.jpg)


![相澤・山崎研究室勉強会
Convolutionは先ほど説明したとおりだが…
!
☆いくつカーネル(フィルタ)を用意する?
☆カーネルのサイズは?
☆「端っこ」の扱いは?
☆活性化関数は?
☆重みやバイアスの決定は?
Convolution(再掲)
61
[conv]
type=conv
inputs=data
channels=3
filters=32
padding=4
stride=1
filterSize=9
neuron=logistic
initW=0.00001
initB=0.5
3. Other Topic](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-61-320.jpg)
![相澤・山崎研究室勉強会
☆プーリング開始画素は?
☆プーリングサイズは?(Overlap)
☆動かす幅は?(Overlap)
☆活性化関数は?
☆プーリングの種類は?
Pooling(再掲)
62
[pool]
type=pool
pool=max
inputs=local32
start=0
sizeX=4
stride=2
outputsX=0
channels=32
neuron=relu
3. Other Topic](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-62-320.jpg)
![相澤・山崎研究室勉強会
いわゆるハイパパラメータ
• いくつかの決定手法は提案されてはいる
• ランダムサーチのほうが性能がいい?[Bergstra, 2012]
• 基本的には層は多くあるべき? [Bengio, 2013]
• http://www.slideshare.net/koji_matsuda/practical-
recommendation-fordeeplearning
!
!
• しかし基本的に問題依存とされる
• 経験則しか頼りづらいBlack-box tool
63
3. Other Topic](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-63-320.jpg)



![相澤・山崎研究室勉強会
後半の参考資料(updated)
• 論文
• Krizhevsky et al., ImageNet Classification with Deep Convolutional Neural Networks, NIPS, 2012
• LeCun et al., Gradient-Based Learning Applied to Document Recognition, Proc. of IEEE, 1998
• [20][21][22]
!
• 日本語スライド
• http://www.slideshare.net/koji_matsuda/practical-recommendation-fordeeplearning
• http://www.slideshare.net/kazoo04/deep-learning-15097274
• http://www.slideshare.net/yurieoka37/ss-28152060 (実装に詳しい)
• http://www.slideshare.net/mokemokechicken/pythondeep-learning (実際にアプリケーション
を作成した例)
!
• 海外チュートリアル
• CVPR 2013のTutorialはCNNに焦点があたっている(GoogleのRanzato氏)
• ICML 2013, CVPR 2012等も参考になる
68](https://image.slidesharecdn.com/150529slideshare-140603034406-phpapp01/85/2014-5-29-Deep-Learning-68-320.jpg)















![[ICLR2016] 採録論文の個人的まとめ](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2016-acceptedpapers-160209033749-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Xception: Deep Learning with Depthwise Separable Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/2017-06-22-170623004409-thumbnail.jpg?width=640&height=640&fit=bounds)





























