Downloaded 102 times





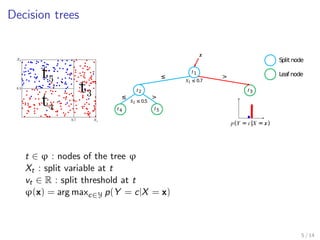

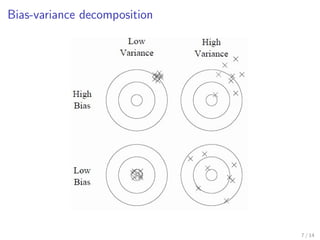

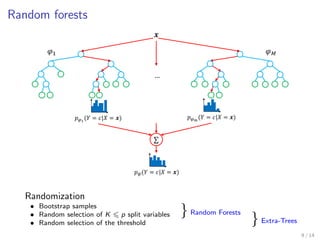






This document discusses bias-variance decomposition in random forests. It explains that combining predictions from multiple randomized models can achieve better results than a single model by reducing variance. Random forests work by constructing decision trees on randomly selected subsets of data and features, averaging their predictions. This randomization increases bias but reduces variance, providing an effective bias-variance tradeoff. The document provides theorems on how the expected generalization error of random forests and individual trees can be decomposed into noise, bias, and variance components.



































































