


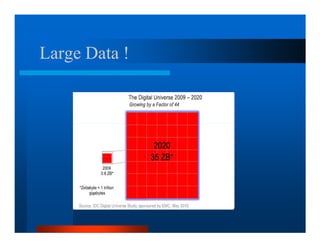
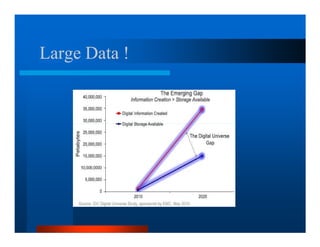
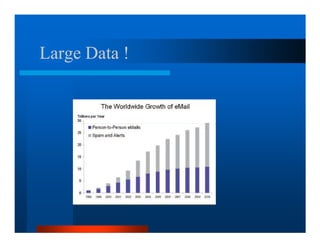
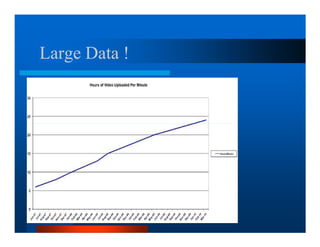


































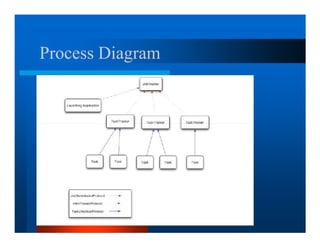

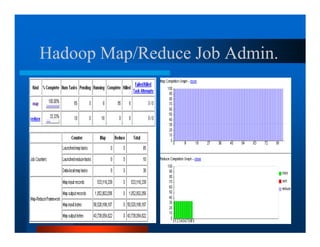
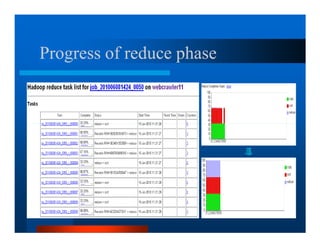
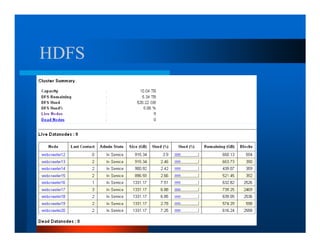



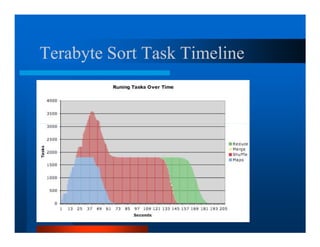
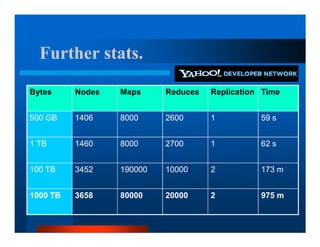
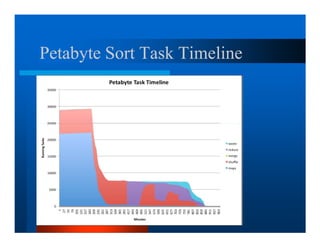










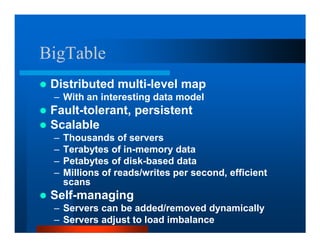

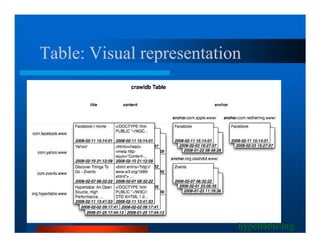
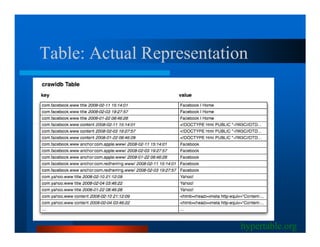
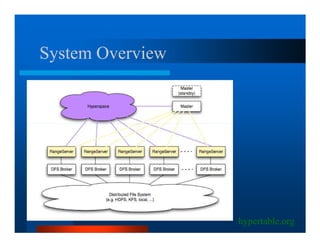








This document provides an overview of large scale data processing and storage. It introduces MapReduce programming model and how it is implemented in Hadoop. It discusses using MapReduce for web mining tasks. It also describes the Hadoop Distributed File System and how data is stored and accessed in HDFS. It explains benchmarking of Hadoop using terabyte and petabyte sorting. It discusses cloud computing with Elastic MapReduce on AWS. Finally, it summarizes BigTable, a distributed storage system from Google.



































































![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















