

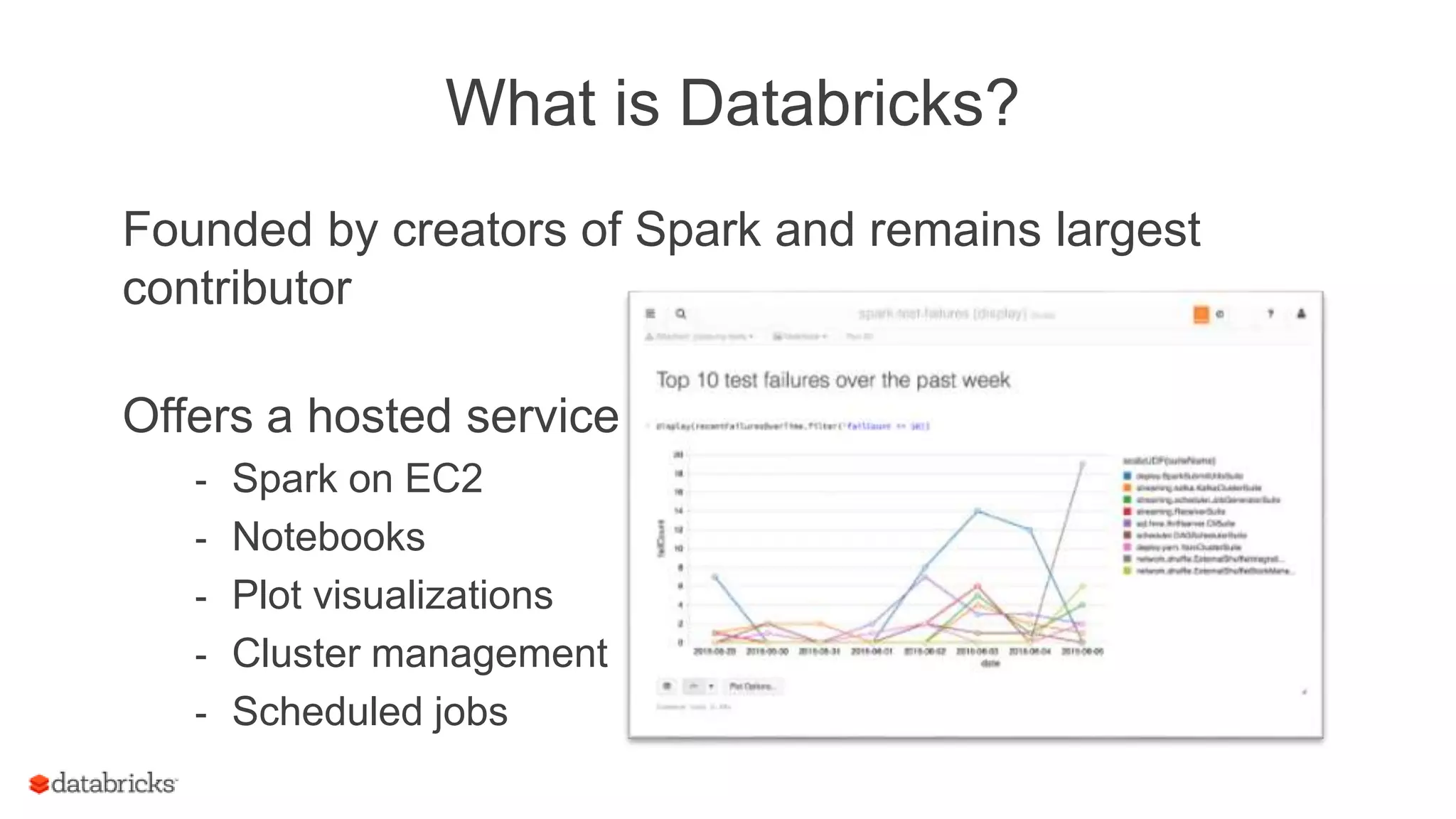









![WordCount with Kafka
object WordCount {
def main(args: Array[String]) {
val context = new StreamingContext(new SparkConf(), Seconds(1))
val lines = KafkaUtils.createStream(context, ...)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x,1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
18
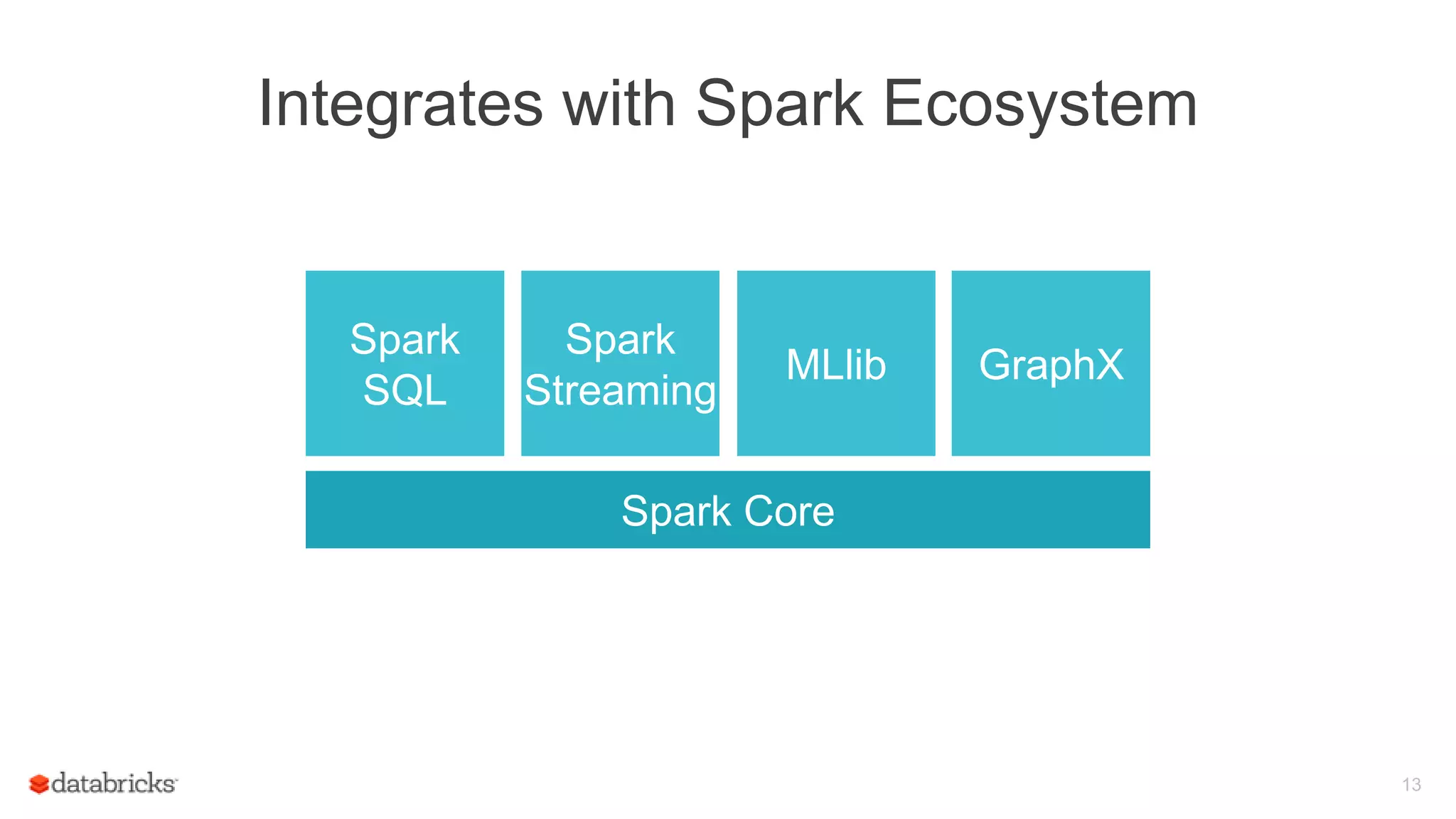
Got it working on a small
Spark cluster on little data
What’s next??](https://image.slidesharecdn.com/june101205pmdatabricksdas-150619213533-lva1-app6891/75/Modus-operandi-of-Spark-Streaming-Recipes-for-Running-your-Streaming-Application-in-Production-18-2048.jpg)


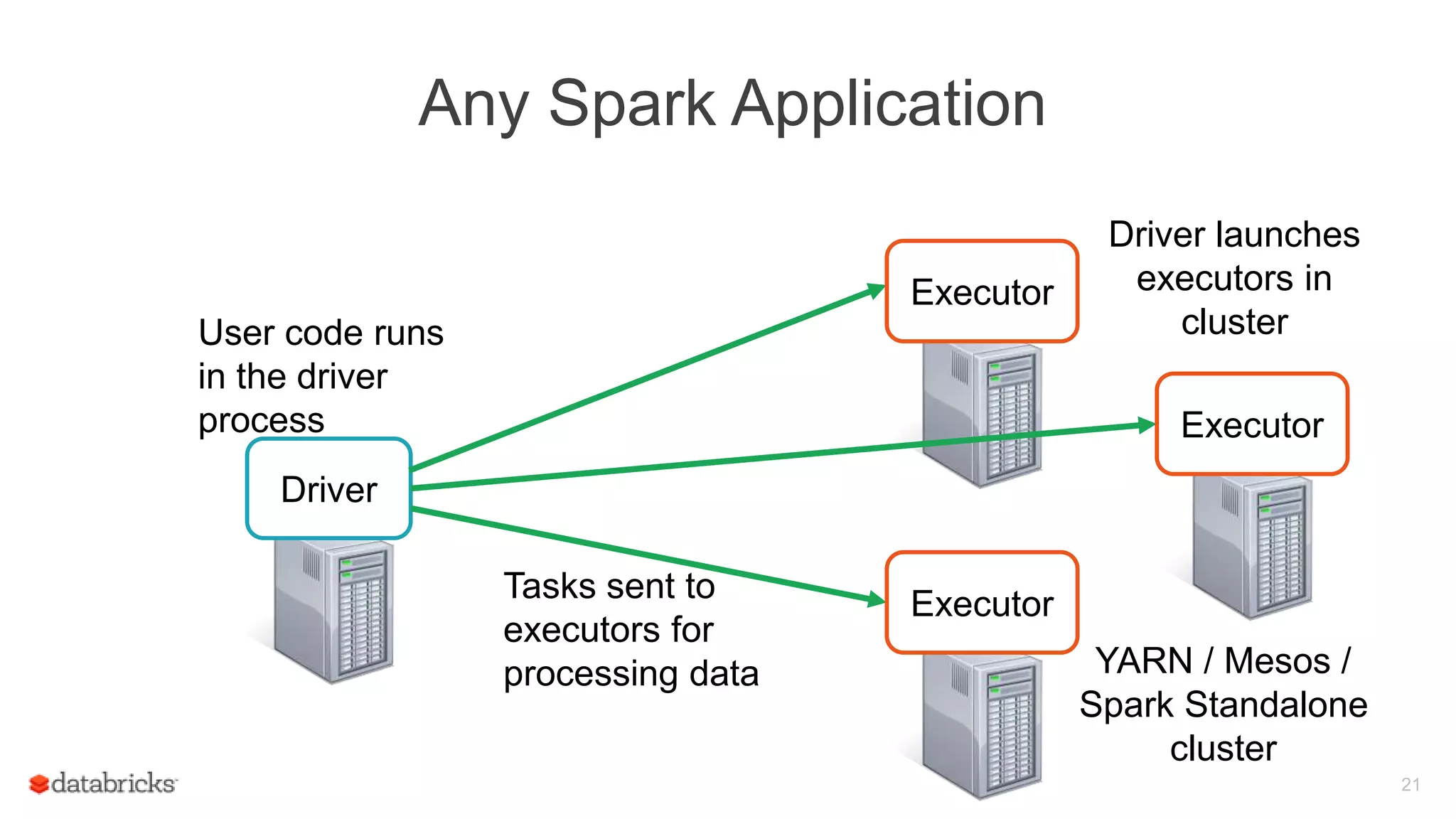
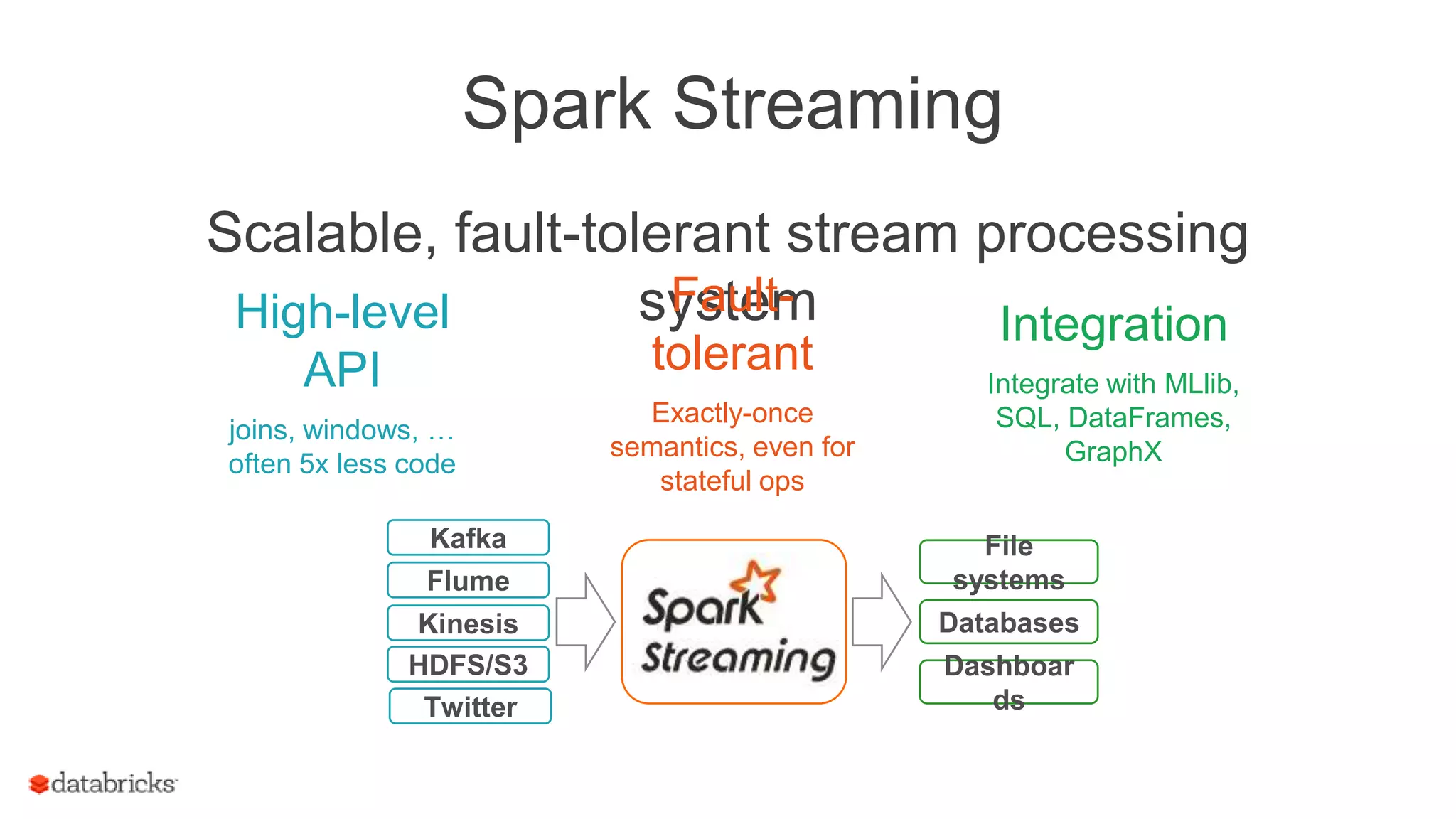
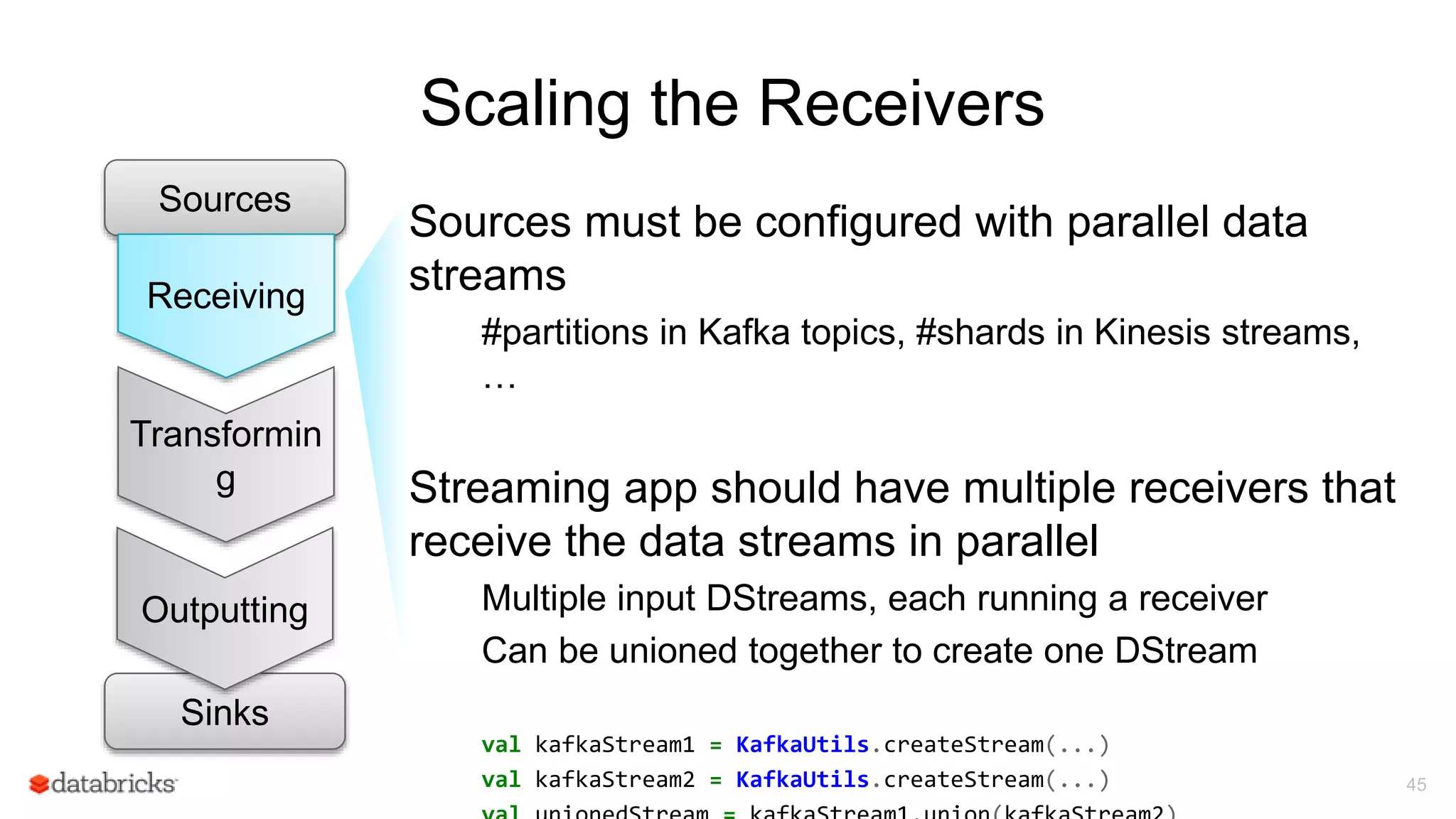
![Spark Streaming Application: Receive data
22
Executo
r
Executo
r
Driver runs
receivers as
long running
tasks
Receiver Data stream
Driver
object WordCount {
def main(args: Array[String]) {
val context = new StreamingContext(…)
val lines = KafkaUtils.createStream(...)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x,1))
.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
Receiver divides
stream into blocks
and keeps in
memory
Data
Blocks
Blocks also
replicated to
another
executor
Data
Blocks](https://image.slidesharecdn.com/june101205pmdatabricksdas-150619213533-lva1-app6891/75/Modus-operandi-of-Spark-Streaming-Recipes-for-Running-your-Streaming-Application-in-Production-22-2048.jpg)
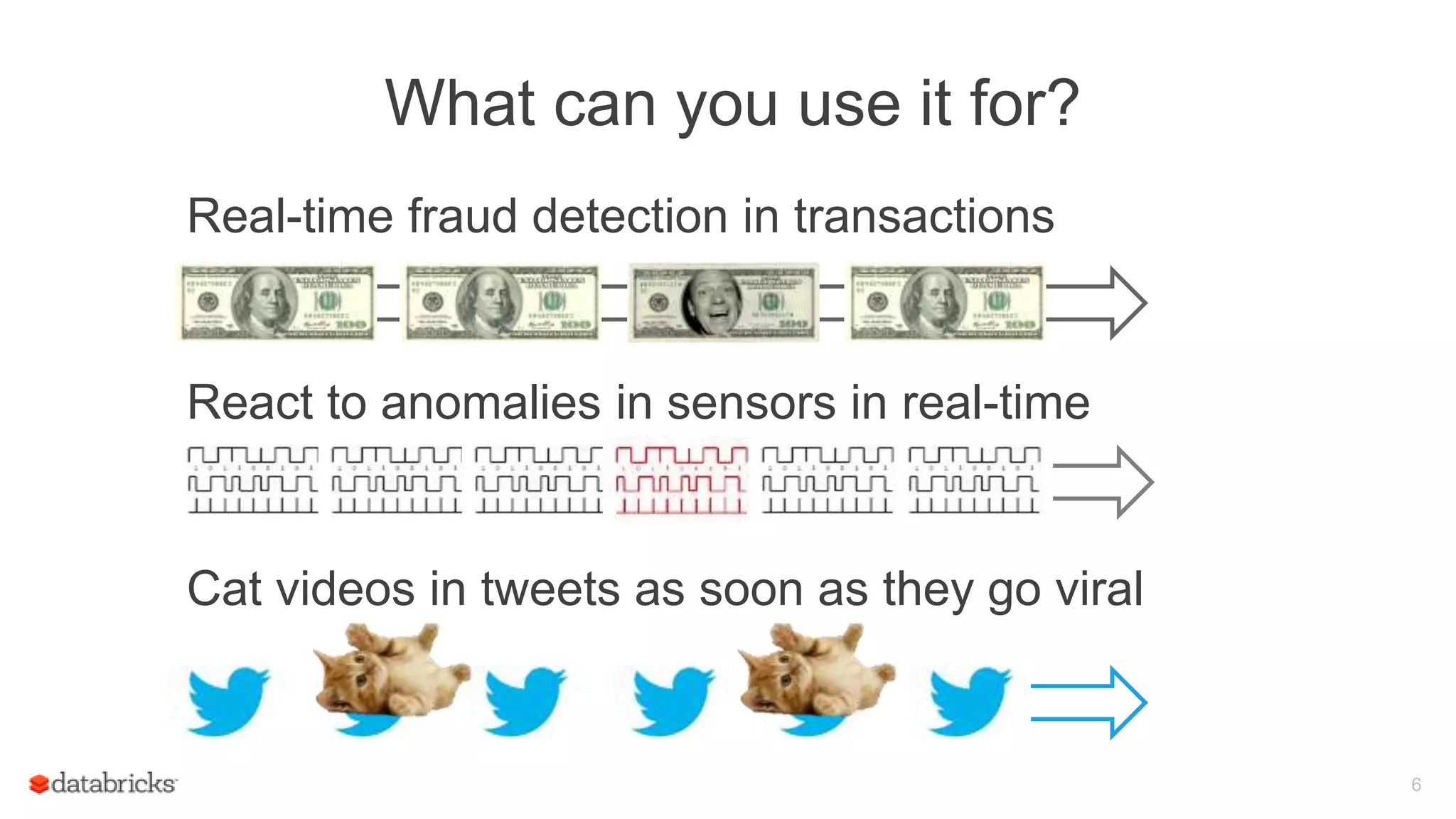
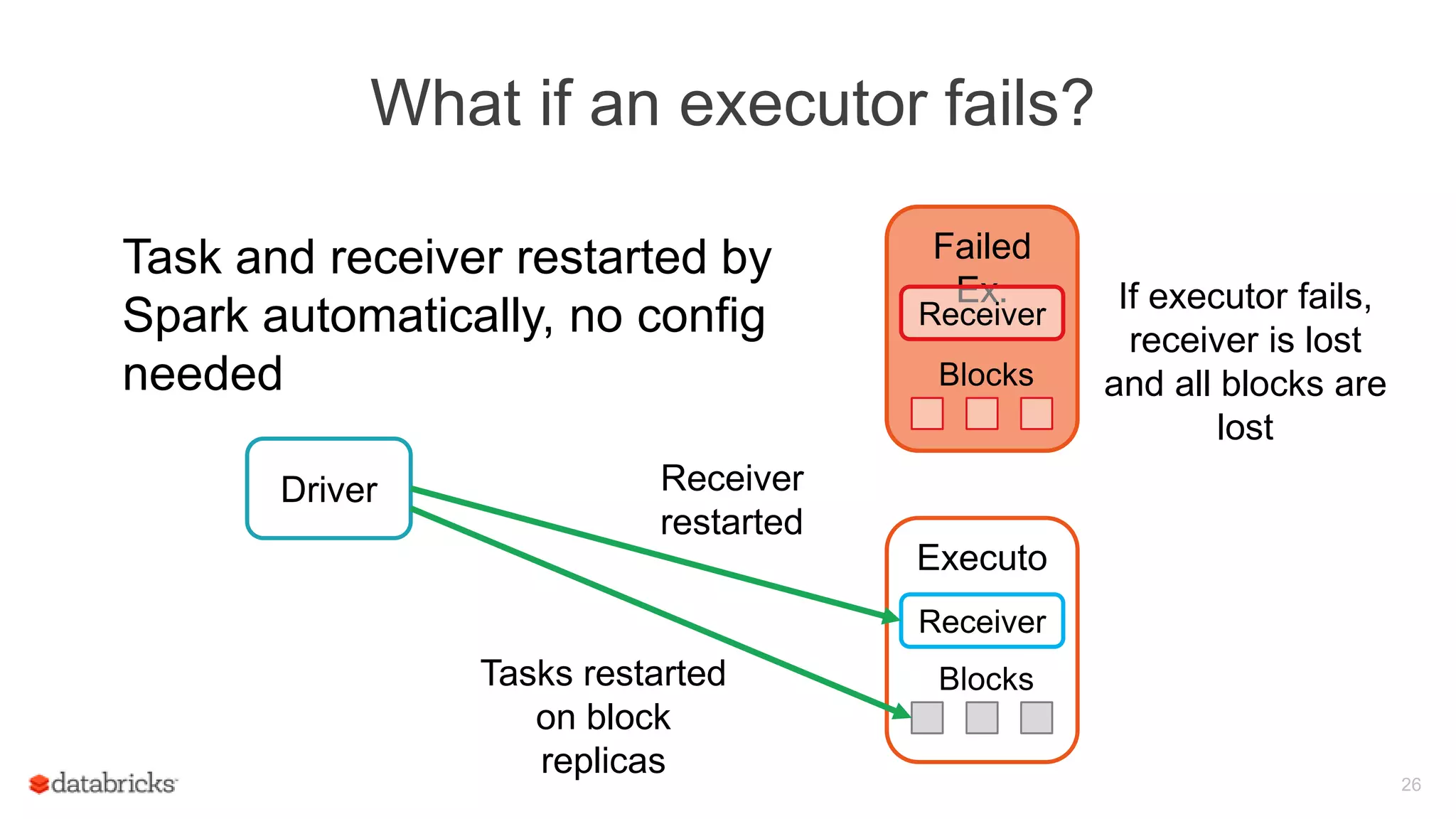
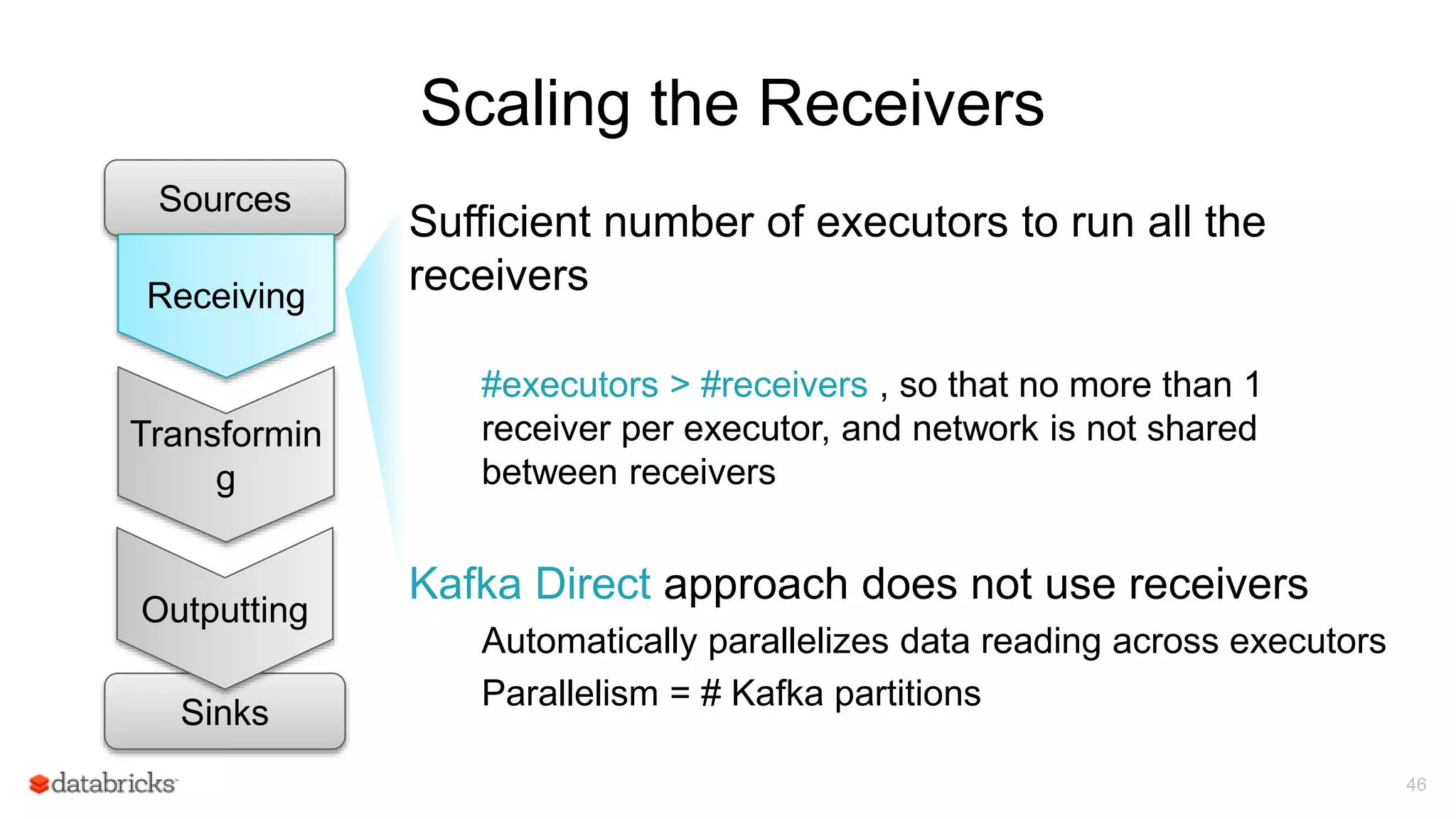
![Spark Streaming Application: Process data
23
Executo
r
Executo
r
Receiver
Data
Blocks
Data
Blocks
Data
stor
e
Every batch
interval, driver
launches tasks to
process the
blocks
Driver
object WordCount {
def main(args: Array[String]) {
val context = new StreamingContext(…)
val lines = KafkaUtils.createStream(...)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x,1))
.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}](https://image.slidesharecdn.com/june101205pmdatabricksdas-150619213533-lva1-app6891/75/Modus-operandi-of-Spark-Streaming-Recipes-for-Running-your-Streaming-Application-in-Production-23-2048.jpg)

















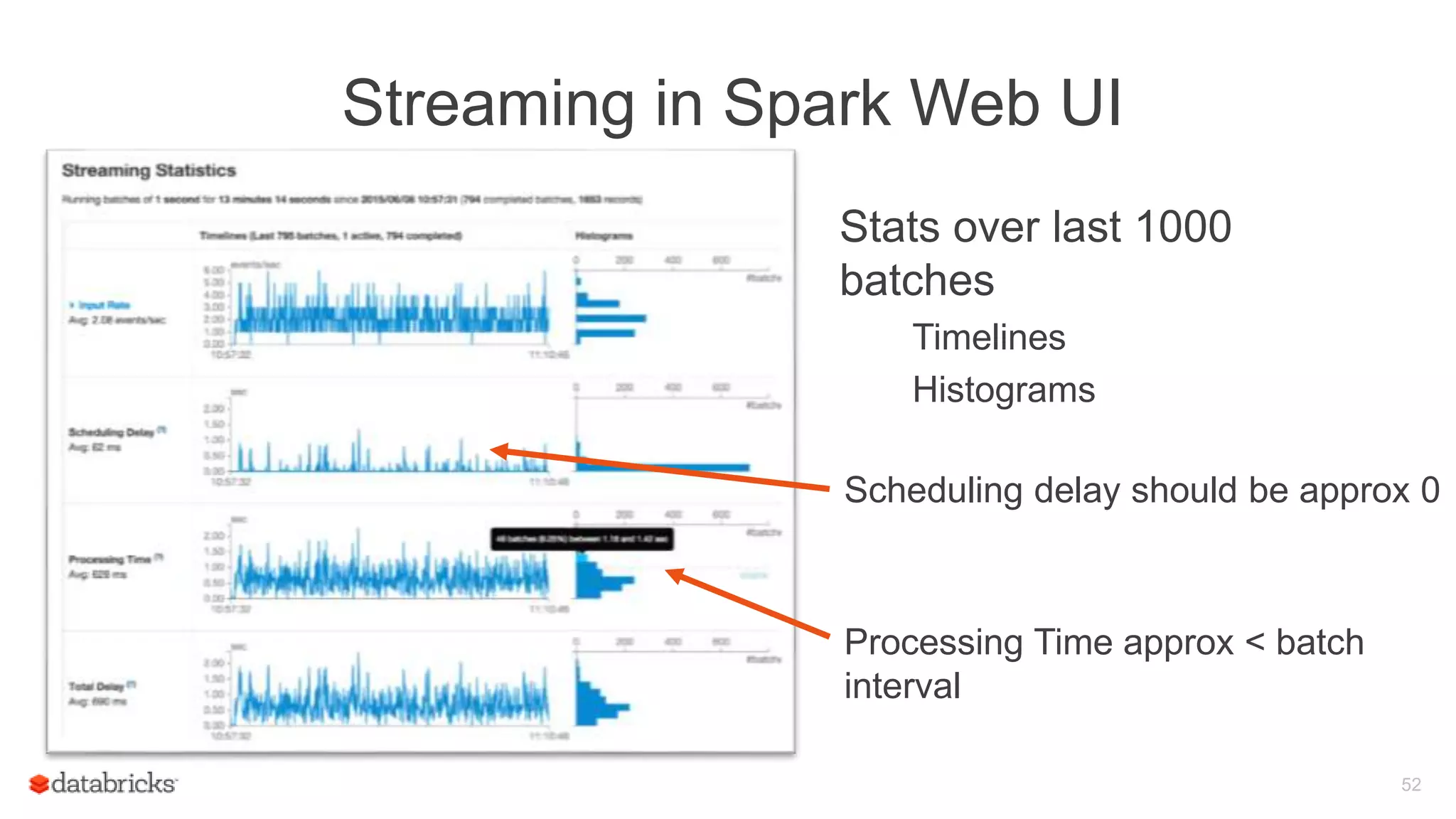
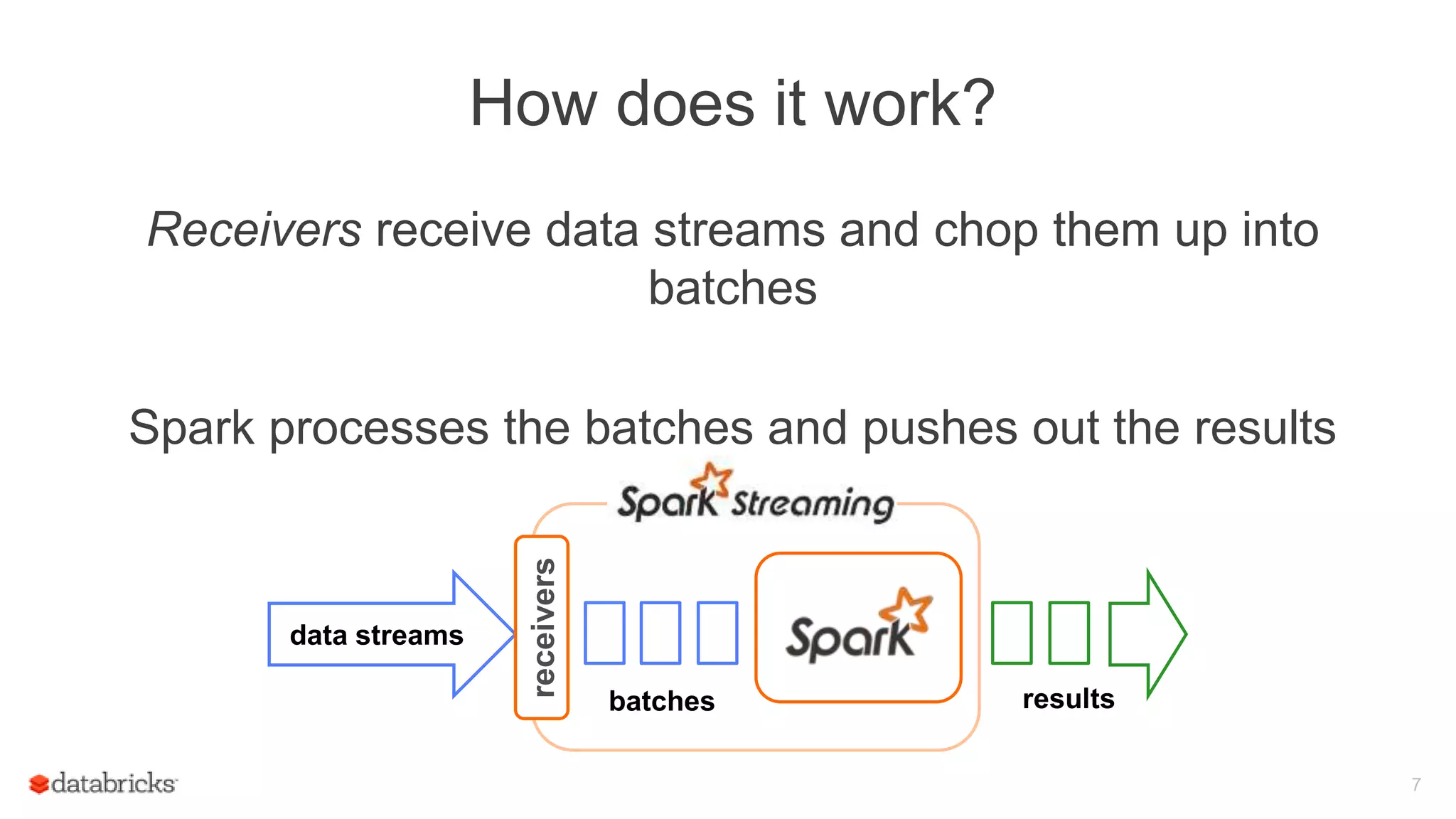
![Streaming in Spark Web UI
Details of individual batches
53
Details of Spark jobs run in a
batch
[New in Spark
1.4]](https://image.slidesharecdn.com/june101205pmdatabricksdas-150619213533-lva1-app6891/75/Modus-operandi-of-Spark-Streaming-Recipes-for-Running-your-Streaming-Application-in-Production-53-2048.jpg)



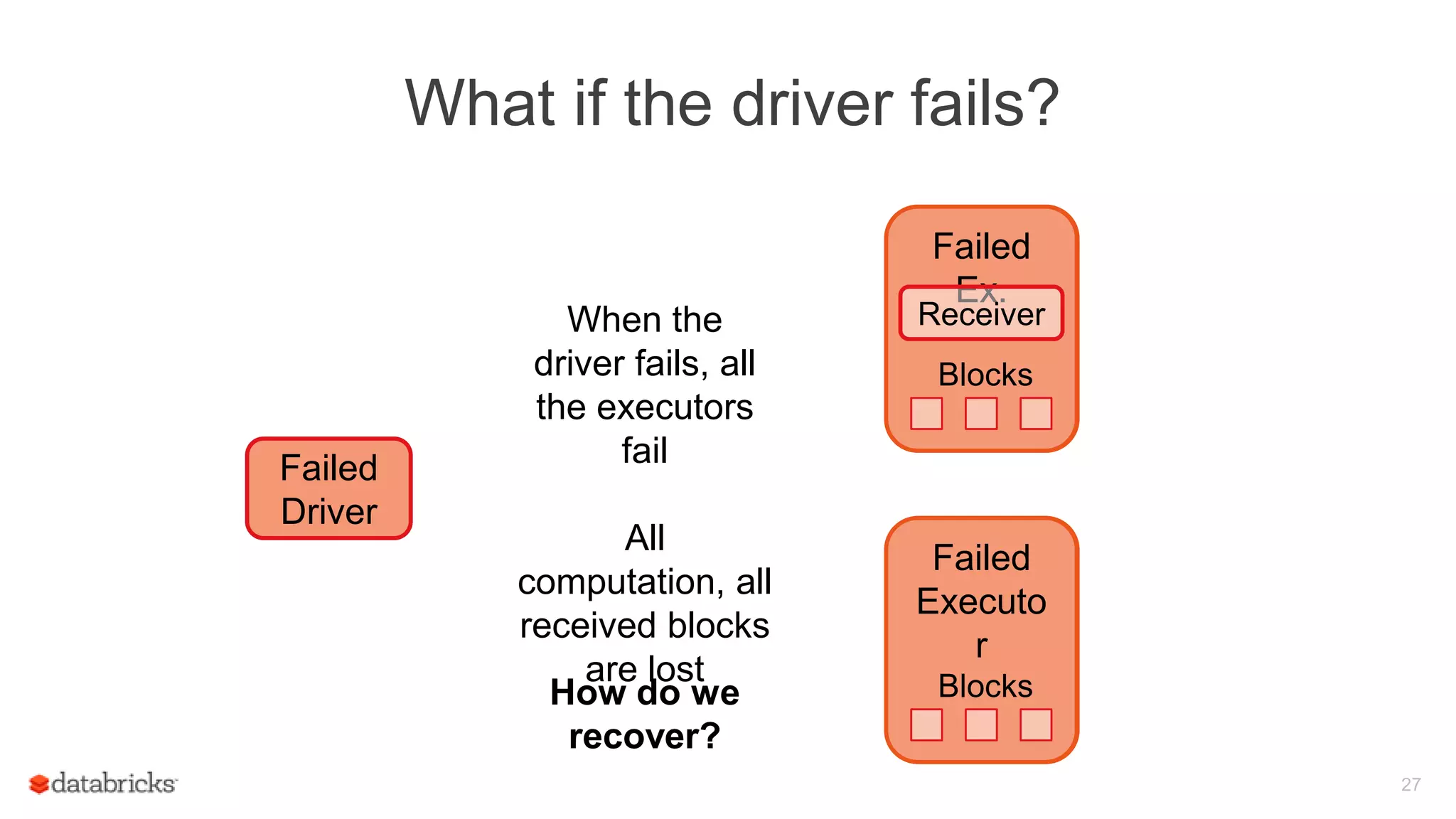
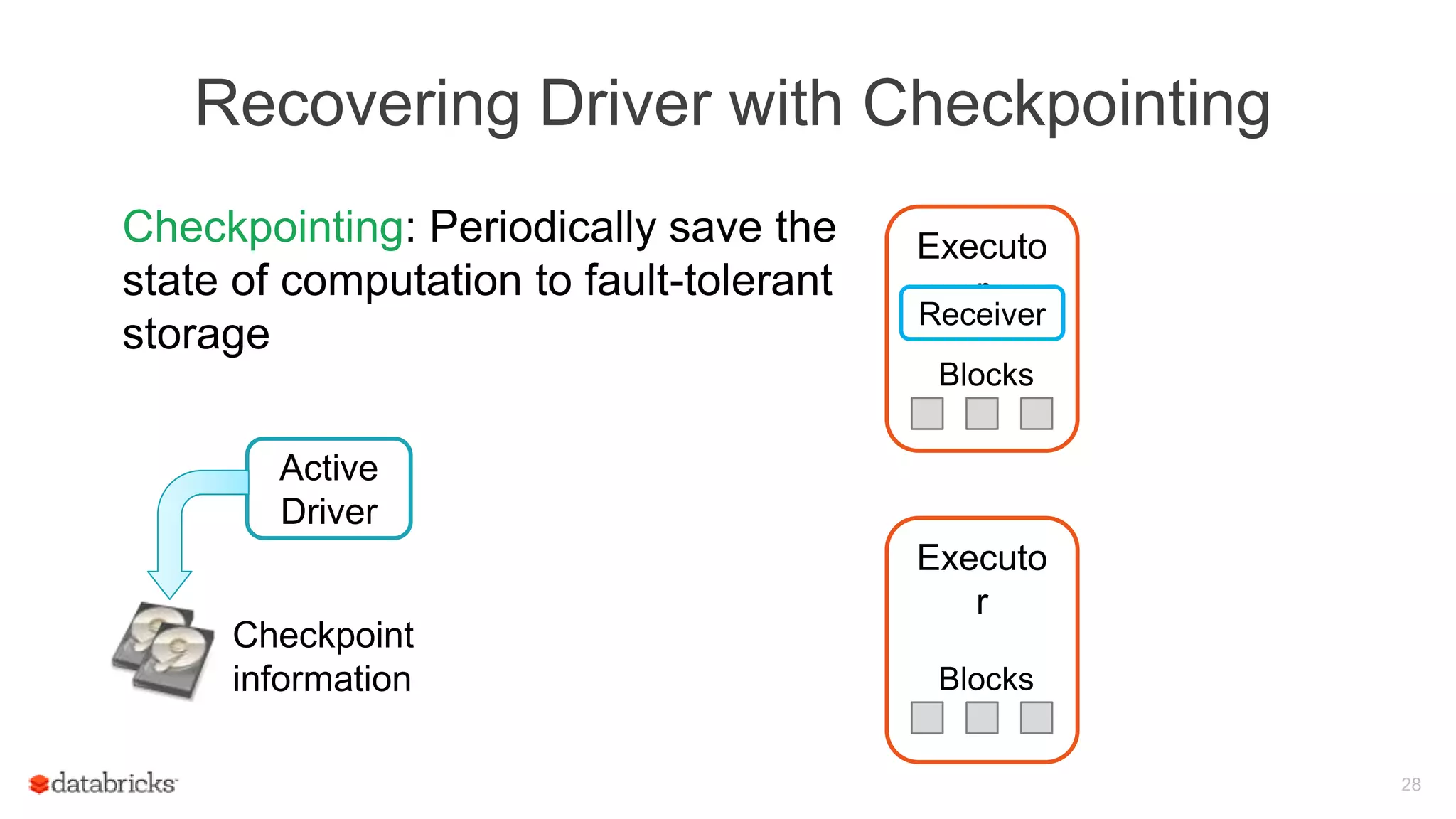
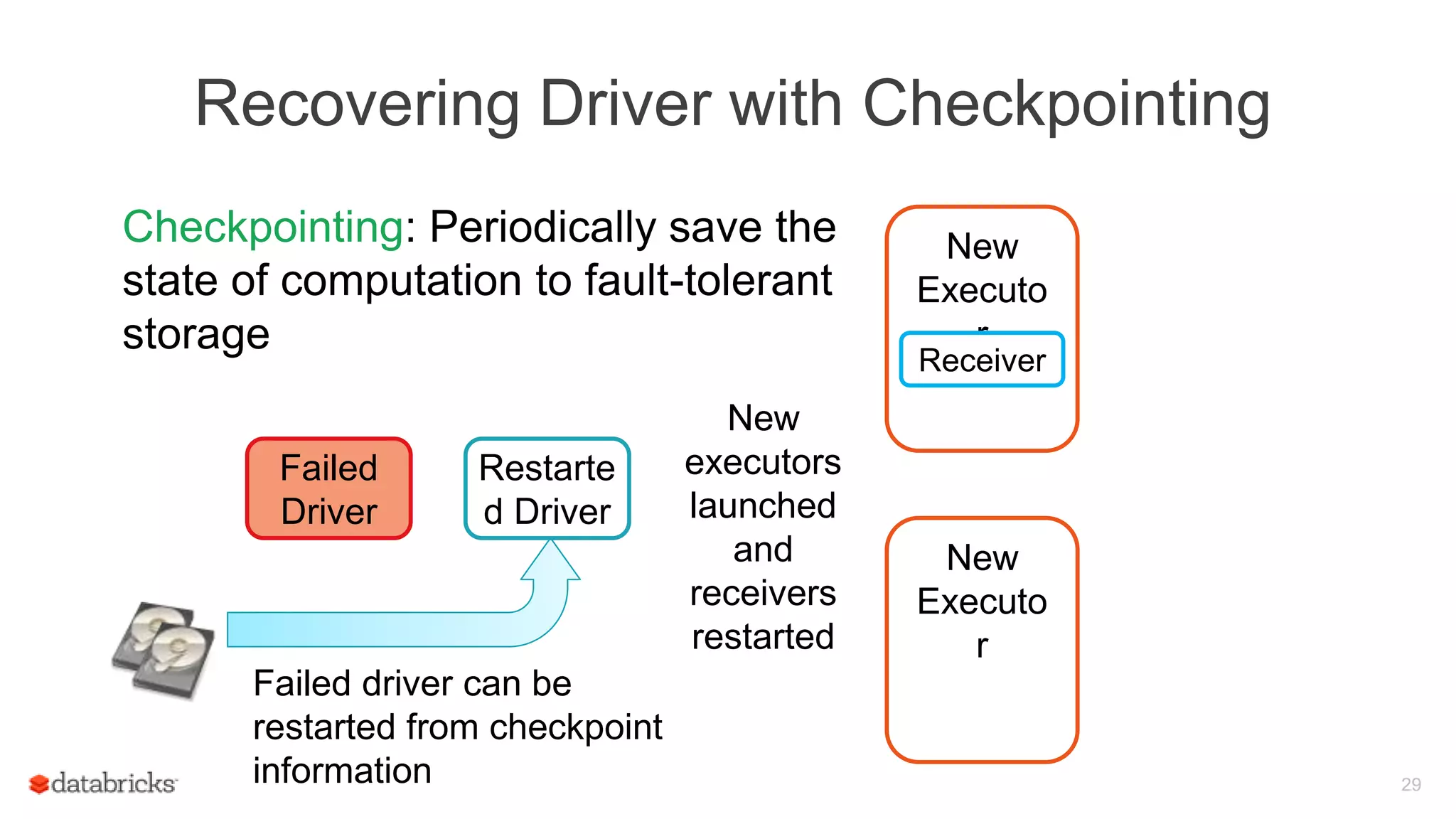
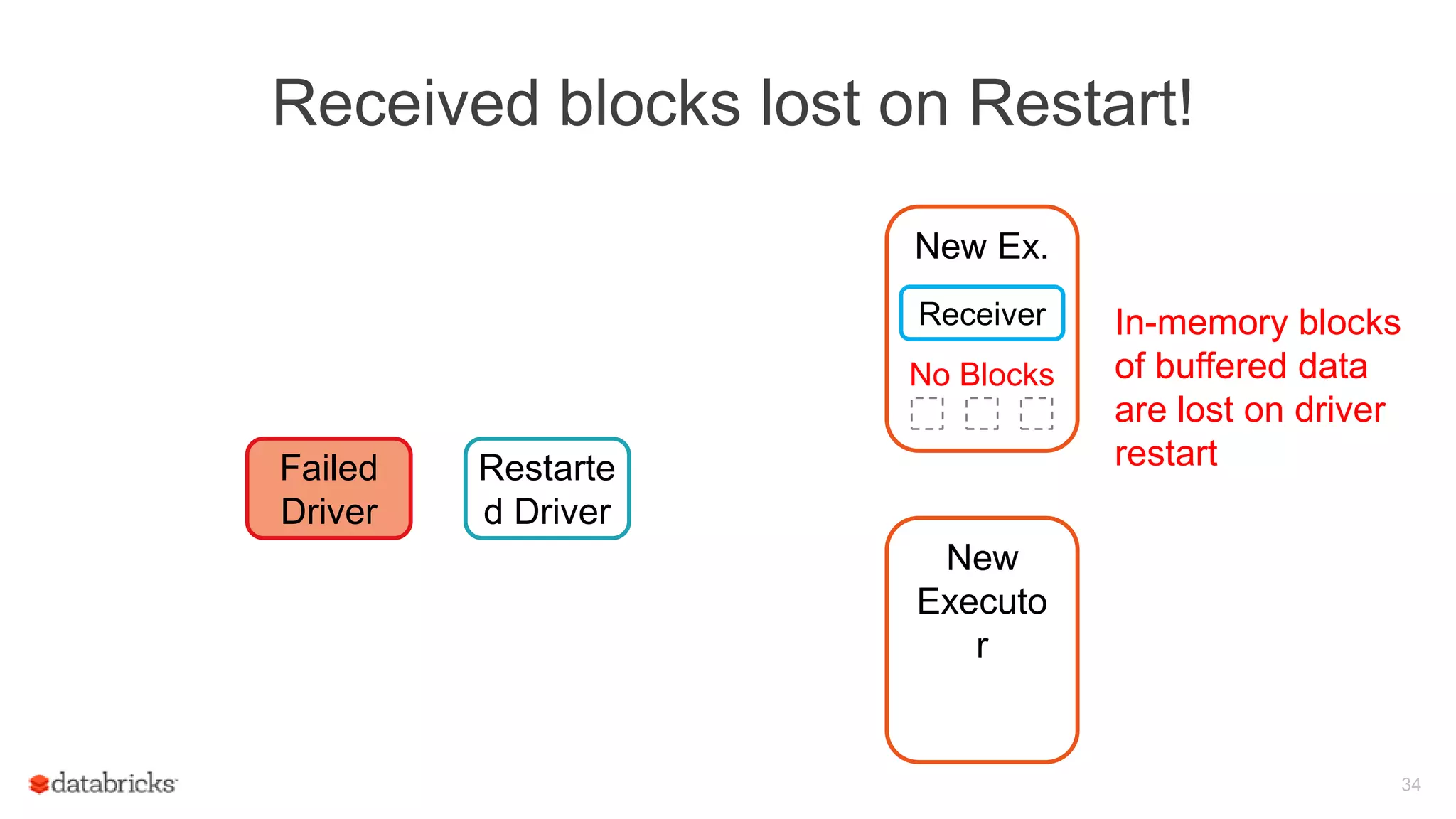
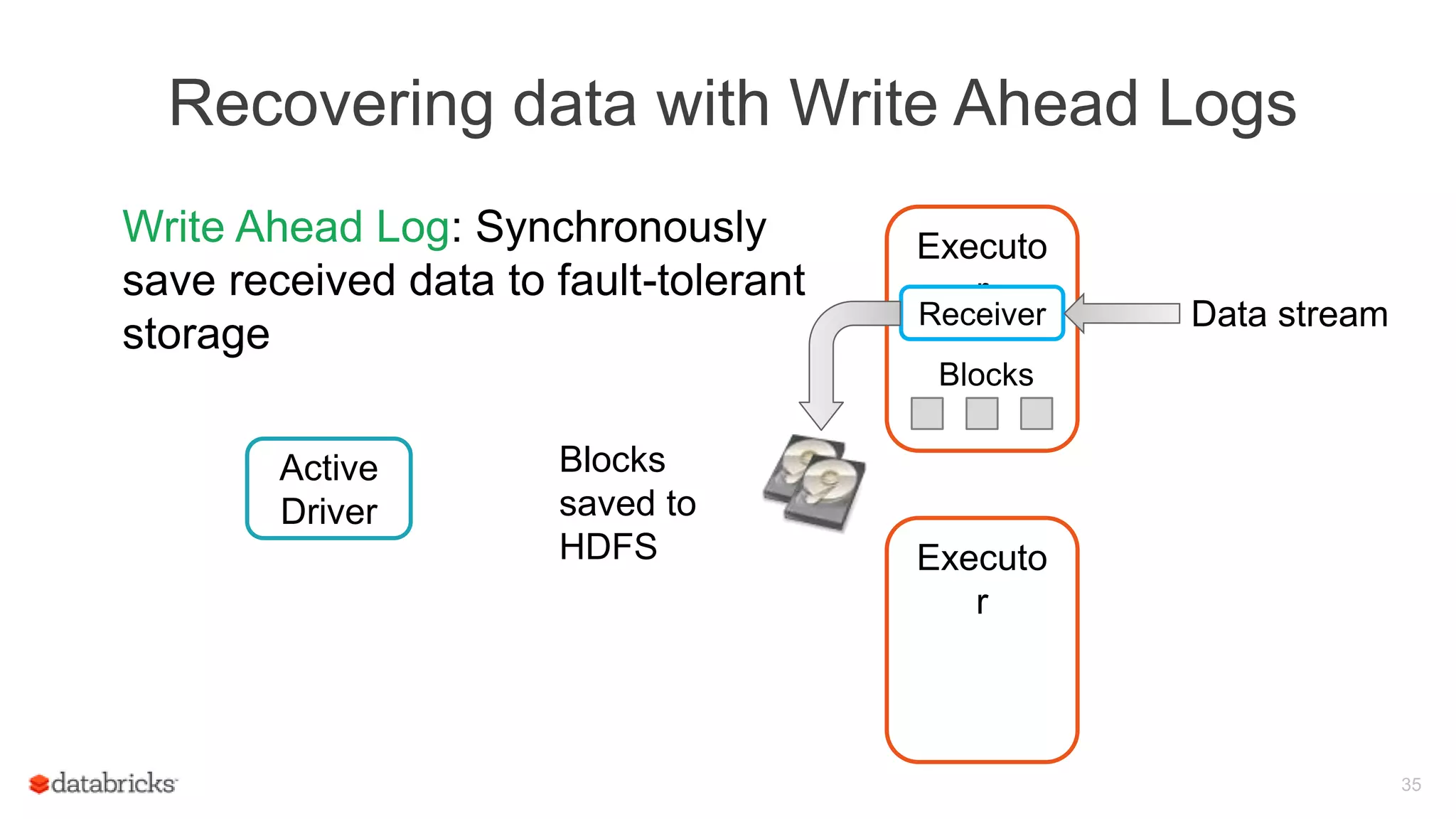
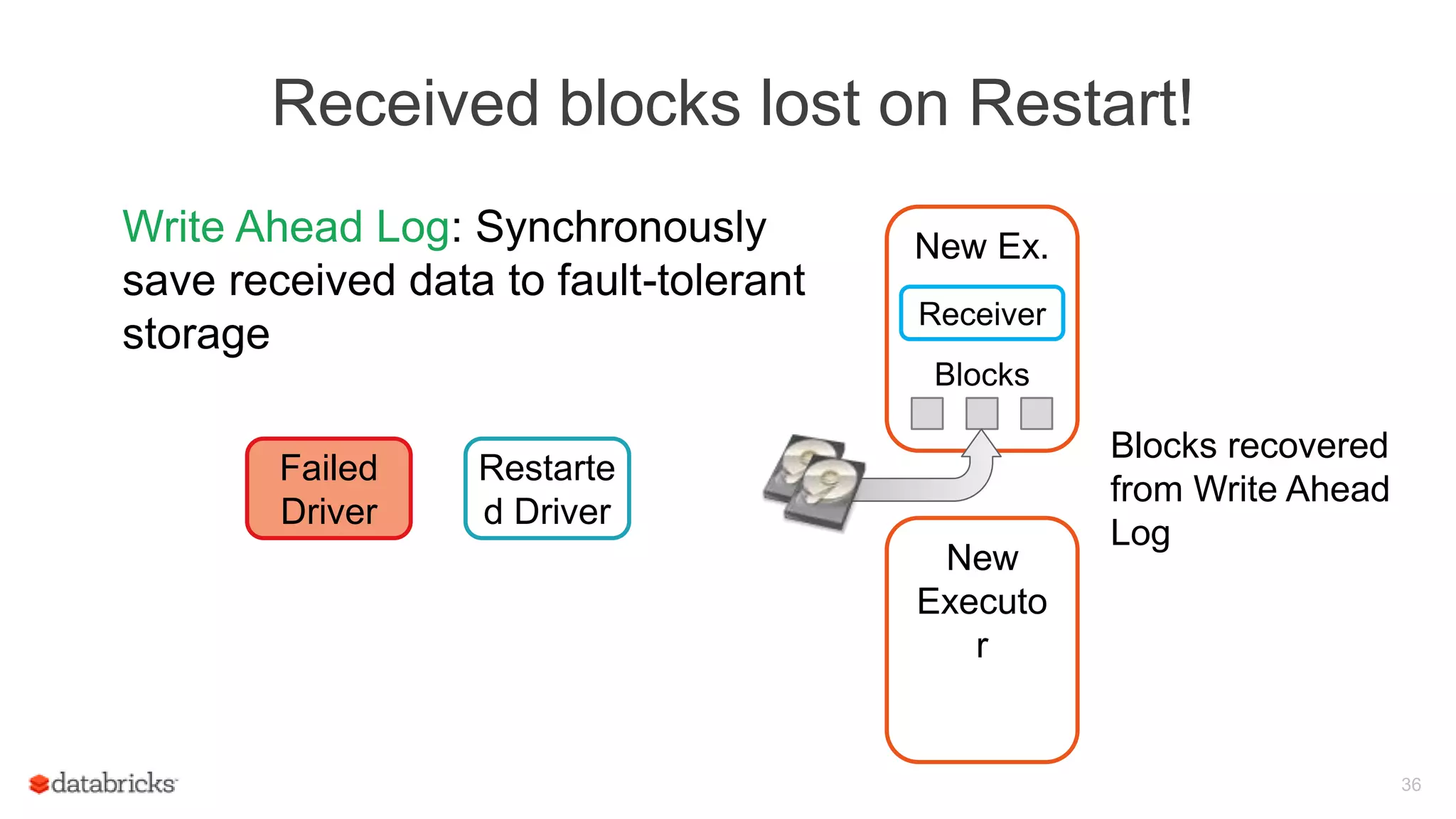
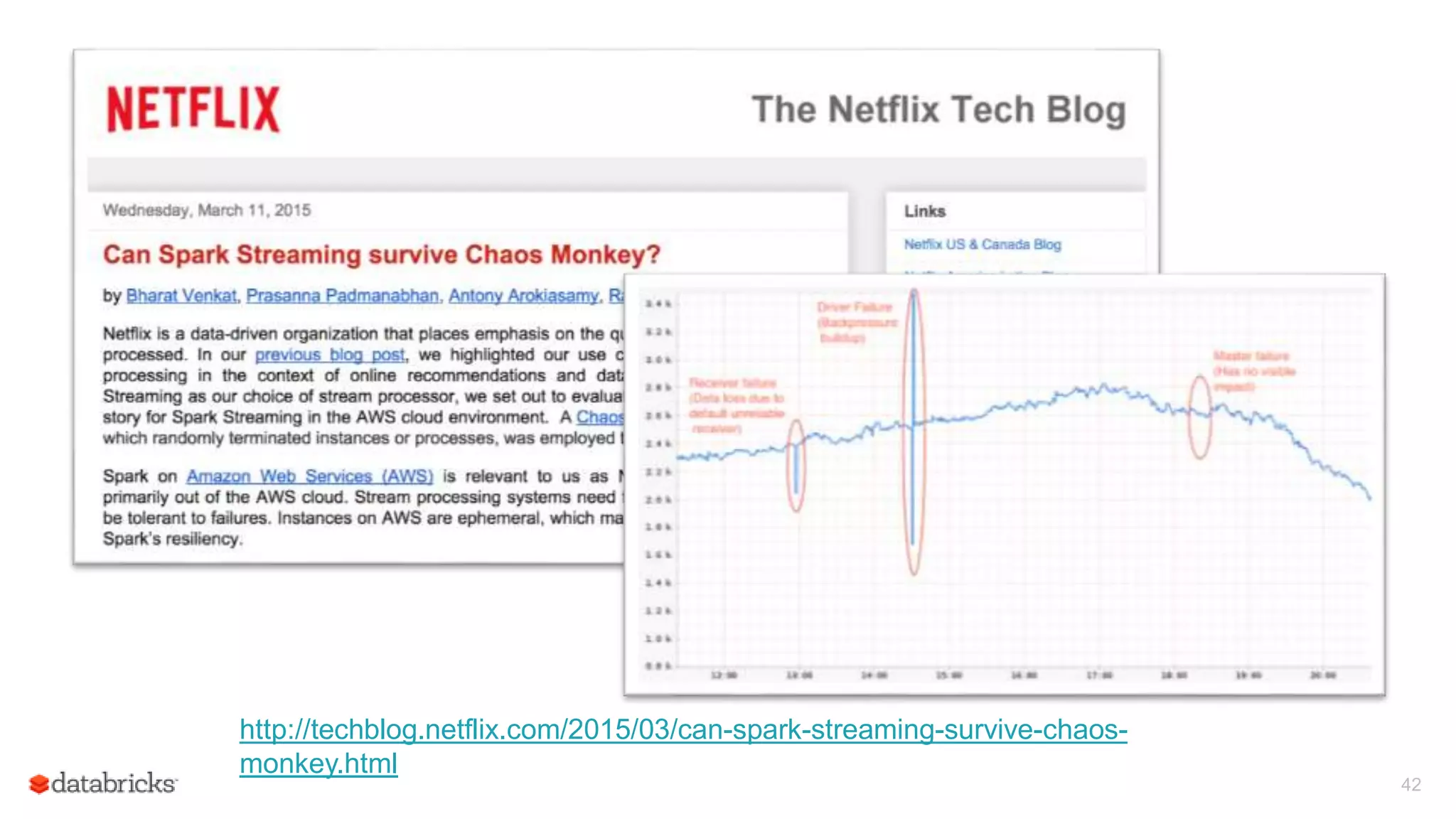
Spark Streaming provides fault-tolerant stream processing capabilities to Spark. To achieve fault-tolerance and exactly-once processing semantics in production, Spark Streaming uses checkpointing to recover from driver failures and write-ahead logging to recover processed data from executor failures. The key aspects required are configuring automatic driver restart, periodically saving streaming application state to a fault-tolerant storage system using checkpointing, and synchronously writing received data batches to storage using write-ahead logging to allow recovery after failures.















































![Inspiring Travel at Airbnb [WIP]](https://cdn.slidesharecdn.com/ss_thumbnails/june91205pmairbnbqiancheng-150616222059-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)






