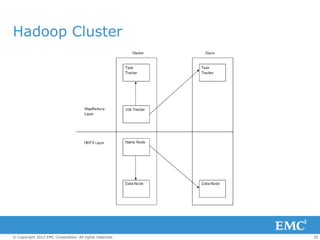
The document discusses MapReduce and Hadoop for processing large datasets. It provides an overview of MapReduce, how it works, and the map and reduce functions. It also discusses Hadoop, how to set up a Hadoop cluster, interacting with the Hadoop file system (HDFS), and demonstrates a word count example in MapReduce. The presentation includes an agenda, definitions of big data and MapReduce, and descriptions of Hadoop daemons and the programming model.














![MapReduce/Hadoop Programming
Job configuration
– Identify classes implementing Mapper and
Reducer interfaces
▪ job.setMapperClass(TokenizerMapper.class);
▪ job.setCombinerClass(IntSumReducer.class);
▪ job.setReducerClass(IntSumReducer.class);
– Specify inputs, outputs
▪ job.setOutputKeyClass(Text.class);
▪ job.setOutputValueClass(IntWritable.class);
▪ FileInputFormat.addInputPath(job, new
Path(otherArgs[0]));
▪ FileOutputFormat.setOutputPath(job, new
Path(otherArgs[1]));
© Copyright 2012 EMC Corporation. All rights reserved. 15](https://image.slidesharecdn.com/bigdataanalytics-120823050558-phpapp02/85/Big-Data-Analytics-MapReduce-Hadoop-A-programmer-s-perspective-15-320.jpg)