Download as PDF, PPTX












![public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setMapperClass(MapClass.class);
conf.setCombinerClass(ReduceClass.class);
conf.setReducerClass(ReduceClass.class);
FileInputFormat.setInputPaths(conf, args[0]);
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setOutputKeyClass(Text.class); // out keys are words
(strings)
conf.setOutputValueClass(IntWritable.class); // values are counts
JobClient.runJob(conf);
}](https://image.slidesharecdn.com/lecture-2part3-150801042758-lva1-app6892/85/Lecture-2-part-3-17-320.jpg)
![import sys
for line in sys.stdin:
for word in line.split():
print(word.lower() + "t" + 1)
import sys
counts = {}
for line in sys.stdin:
word, count = line.split("t”)
dict[word] = dict.get(word, 0) +
int(count)
for word, count in counts:
print(word.lower() + "t" + 1)](https://image.slidesharecdn.com/lecture-2part3-150801042758-lva1-app6892/85/Lecture-2-part-3-18-320.jpg)
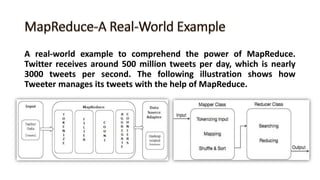





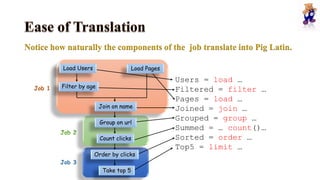



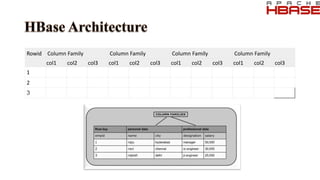

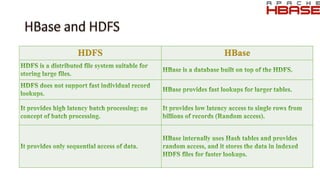

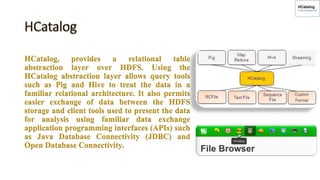



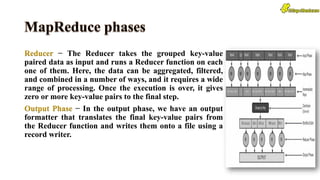
The document discusses key concepts related to Hadoop including its components like HDFS, MapReduce, Pig, Hive, and HBase. It provides explanations of HDFS architecture and functions, how MapReduce works through map and reduce phases, and how higher-level tools like Pig and Hive allow for more simplified programming compared to raw MapReduce. The summary also mentions that HBase is a NoSQL database that provides fast random access to large datasets on Hadoop, while HCatalog provides a relational abstraction layer for HDFS data.








































































