The document provides a comprehensive overview of 'sparkr', an R interface for Apache Spark, highlighting its origins, features, and usage. It covers key concepts such as data frames, RDDs, machine learning libraries, and practical applications for data analysis and visualization using R. Additionally, it discusses the future development plans for sparkr and includes various references and resources for further learning.























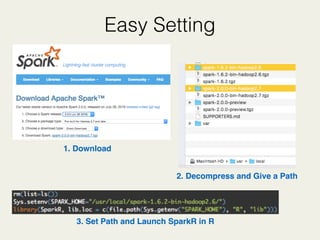




![Word Count
# read data into RDD
rdd <- SparkR:::textFile(sc, "data_word_count.txt")
# split word
words <- SparkR:::flatMap(rdd, function(line) {
strsplit(line, " ")[[1]]
})
# map: give 1 for each word
wordCount <- SparkR:::lapply(words, function(word) {
list(word, 1)
})
# reduce: count the value by key(word)
counts <- SparkR:::reduceByKey(wordCount, "+", 2)
# convert RDD to list
op <- SparkR:::collect(counts)](https://image.slidesharecdn.com/20160909hadoopcon-160911182018/85/SparkR-Play-Spark-Using-R-20160909-HadoopCon-29-320.jpg)
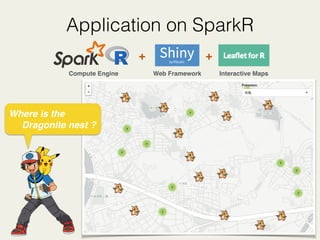
![RDD v.s. DataFrames
flights_SDF <- read.df(sqlContext, "data_flights.csv",
source = "com.databricks.spark.csv", header = "true")
SDF_op <- flights_SDF %>%
group_by(flights_SDF$hour) %>%
summarize(sum(flights_SDF$dep_delay)) %>%
collect()
flights_RDD <- SparkR:::textFile(sc, "data_flights.csv")
RDD_op <- flights_RDD %>%
SparkR:::filterRDD(function (x) { x >= 1 }) %>%
SparkR:::lapply(function(x) {
y1 <- as.numeric(unlist(strsplit(x, ","))[2])
y2 <- as.numeric(unlist(strsplit(x, ","))[6])
return(list(y1,y2))}) %>%
SparkR:::reduceByKey(function(x,y) x + y, 1) %>%
SparkR:::collect()
DataFrames
RDD](https://image.slidesharecdn.com/20160909hadoopcon-160911182018/85/SparkR-Play-Spark-Using-R-20160909-HadoopCon-30-320.jpg)








































































![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)
