Downloaded 35 times












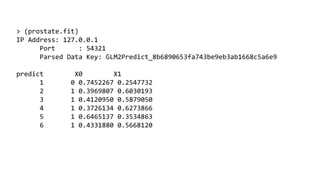
![Example in R
library(h2o)
localH2O = h2o.init(ip = 'localhost', port = 54321)
irisPath = system.file("extdata", "iris.csv", package="h2o")
iris.hex = h2o.importFile(localH2O, path = irisPath, key = "iris.hex")
iris.data.frame <- as.data.frame(iris.hex)
> colnames(iris.hex)
[1] "C1" "C2" "C3" "C4" "C5"
>](https://image.slidesharecdn.com/datajob-mlscale3-141120160307-conversion-gate02/85/scalable-machine-learning-19-320.jpg)


![Same but with Spark API
// H2O Context provide useful implicits for conversions
val h2oContext = new H2OContext(sc)
import h2oContext._
// Create RDD wrapper around DataFrame
val airlinesTable : RDD[Airlines] = toRDD[Airlines](airlinesData)
airlinesTable.count
// And use Spark RDD API directly
val flightsOnlyToSF = airlinesTable.filter(f =>
f.Dest==Some("SFO") || f.Dest==Some("SJC") || f.Dest==Some("OAK")
)
flightsOnlyToSF.count](https://image.slidesharecdn.com/datajob-mlscale3-141120160307-conversion-gate02/85/scalable-machine-learning-26-320.jpg)


.collect
.map ( _.result.getOrElse("NaN") )](https://image.slidesharecdn.com/datajob-mlscale3-141120160307-conversion-gate02/85/scalable-machine-learning-28-320.jpg)



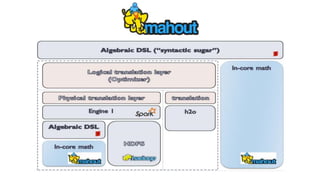
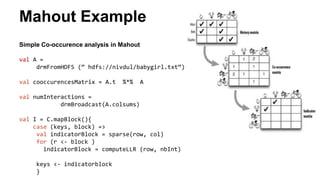
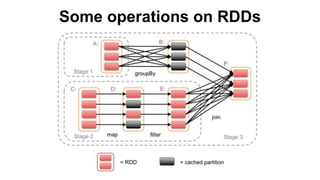
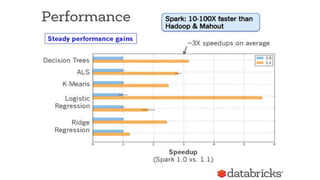
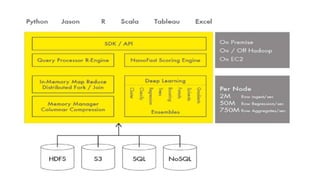
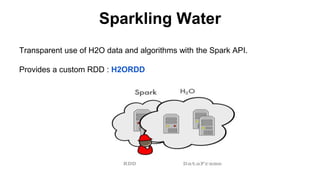
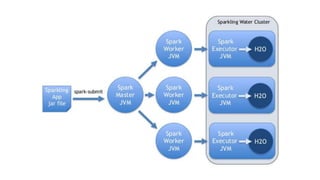
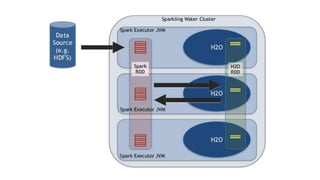
This document discusses scalable machine learning techniques. It summarizes Spark MLlib, which provides machine learning algorithms that can run on large datasets in a distributed manner using Apache Spark. It also discusses H2O, which provides fast machine learning algorithms that can integrate with Spark via Sparkling Water to allow transparent use of H2O models and algorithms with the Spark API. Examples of using K-means clustering and logistic regression are provided to illustrate MLlib and H2O.





































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




