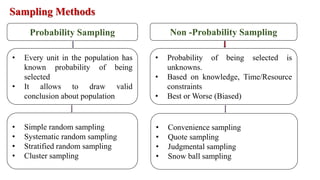
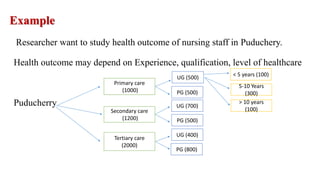
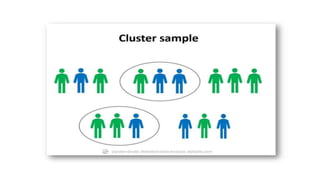
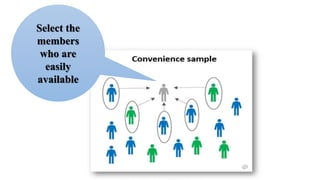
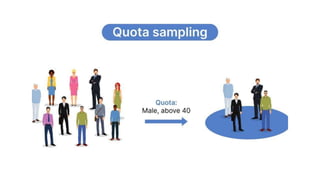
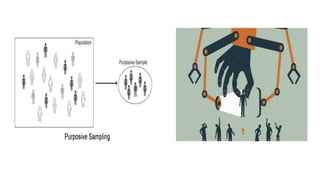
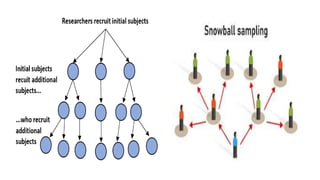
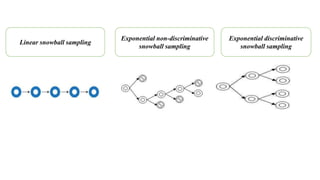
The document outlines various sampling methods used in research, including probability and non-probability sampling techniques. It explains procedures and examples for methods such as simple random sampling, systematic sampling, stratified sampling, cluster sampling, convenience sampling, quota sampling, judgmental sampling, and snowball sampling. Each method is discussed regarding its pros and cons, focusing on aspects like validity, efficiency, and potential biases.


















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)













