Download to read offline






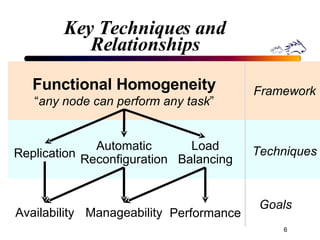
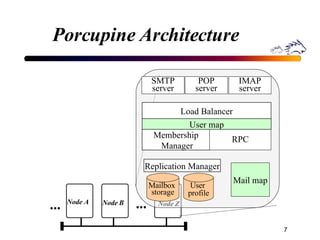
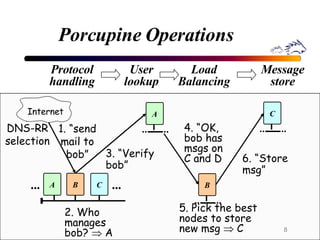
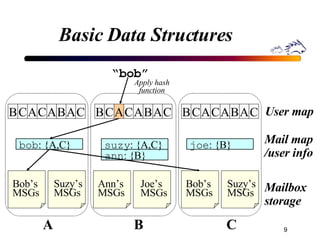




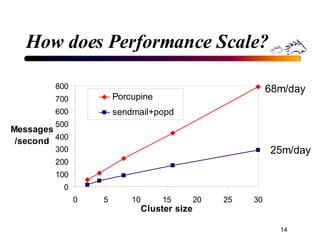

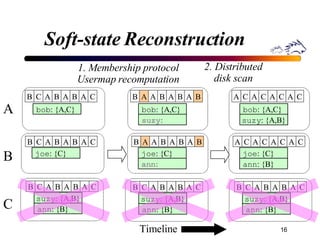
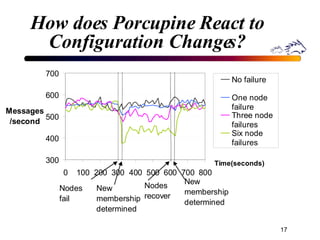

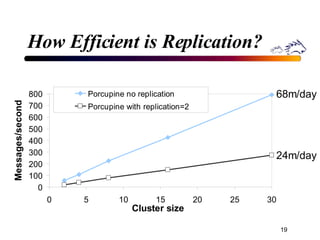
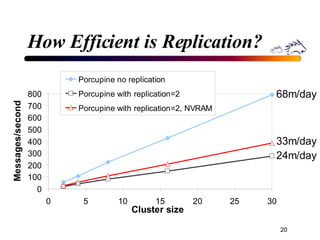

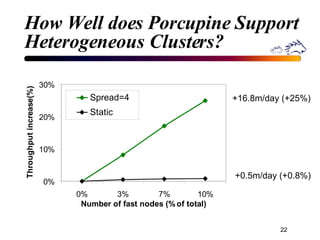



Porcupine is a highly available cluster-based mail service that uses commodity hardware to provide scalable email services. It addresses challenges of conventional mail solutions in performance, manageability and availability. Key techniques used include functional homogeneity, automatic reconfiguration, replication and load balancing to provide better availability, manageability and linear performance scaling with cluster size. Evaluation shows it efficiently handles failures, heterogeneous hardware and skewed workloads.























































































