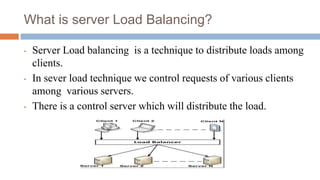
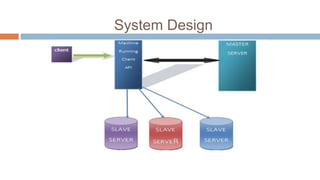
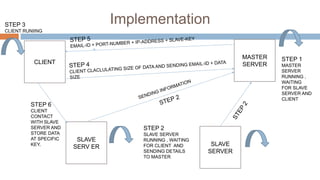
This document describes a server load balancing system for structured data. The objectives are to develop a load balancer that can manage large amounts of data and provide functionality for uploading, downloading, and deleting data, while providing reliability, scalability, and high performance. The system uses a master server to distribute loads to slave servers and track their locations. Clients communicate directly with slave servers to access data using unique keys. This allows for horizontal scaling and fault tolerance. The system is designed to handle large volumes of data across multiple servers and provide reliable access even if servers fail.




















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




