Downloaded 44 times








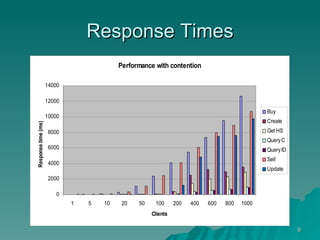
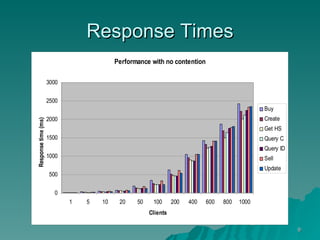
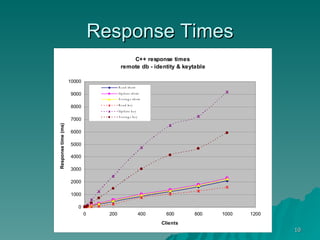


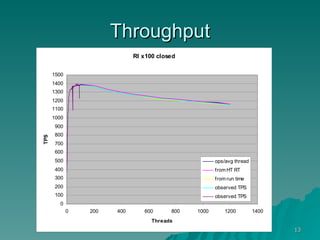

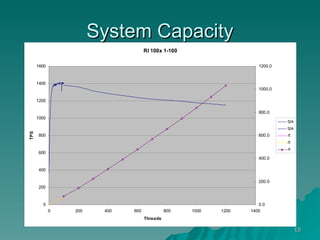

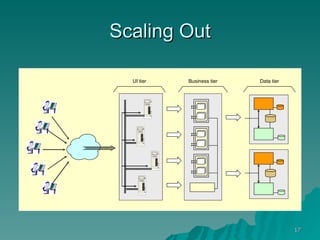

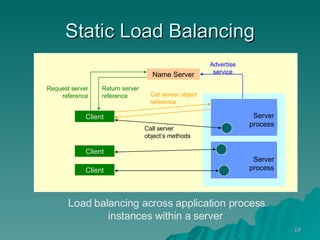



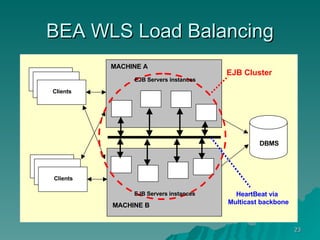

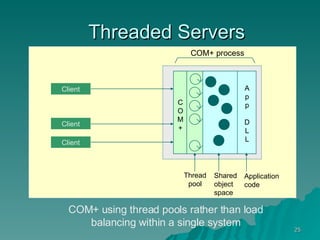



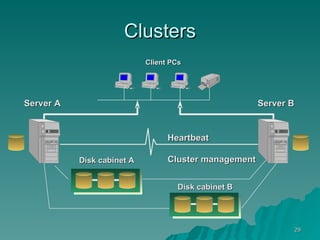



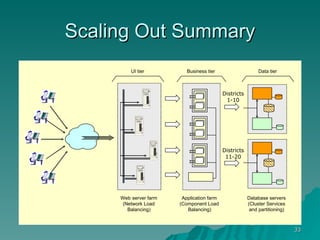


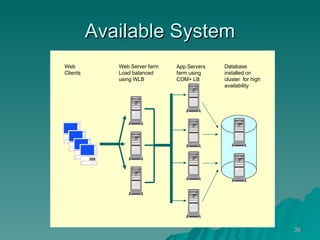





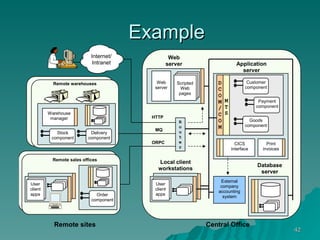

The document discusses several concepts related to building scalable and available systems, including: - Scalability involves a system's ability to handle expected loads with acceptable performance and to grow easily when loads increase. This may involve scaling up using bigger/faster systems or scaling out across multiple systems. - Availability is the goal of having a system operational 100% of the time, requiring redundancy so there are no single points of failure. - Performance measures like response time and throughput relate to a system's scalability and capacity. Distributing load across redundant and partitioned components can help improve scalability and availability.






























































































