Downloaded 55 times





![CPSLAB (http://cpslab.snu.ac.kr)
Learning From Demonstration
6Learning From Data
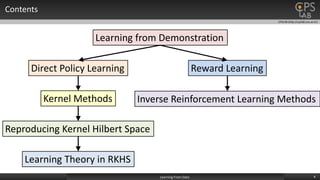
There are two approaches: direct policy learning and reward learning.
Direct policy learning Reward learning
• Try to find a policy function which maps a state
space to an action space.
State
space, 𝑆
Action
space, 𝐴
Policy function
𝜋: 𝑆 → 𝐴
• Cast the learning problem to regression or multi-class
classification problem.
• Standard learning theory or approximation theory are
often used to analyze the performance of learning.
• Try to find a reward function indicating how ‘good’
each state-action pair is.
Joint State-
Action space,
S × 𝐴
Reward
space, 𝑅
• “The reward function, rather than the policy, is the most
succint, robust, and transferable definition of the task.” [1]
[1] Ng, Andrew Y., and Stuart J. Russell. "Algorithms for inverse reinforcement learning." ICML. 2000.
• Often refer to as an Inverse Reinforcement Learning
(IRL) problem.](https://image.slidesharecdn.com/labseminar-learningfromdata-151211060146/85/Robot-Learning-From-Data-6-320.jpg)

![CPSLAB (http://cpslab.snu.ac.kr)
Definition and Existence Reproducing Kernel Hilbert Space
9Learning From Data
Existence of the RKHS is shown by Moore-Aronszajn theorem.
Following is the definition of the reproducing kernel Hilbert space. [1]
[1] Rasmussen, Carl Edward. "Gaussian processes for machine learning." (2006).](https://image.slidesharecdn.com/labseminar-learningfromdata-151211060146/85/Robot-Learning-From-Data-9-320.jpg)
![CPSLAB (http://cpslab.snu.ac.kr)
Reproducing Kernel Hilbert Space
10Learning From Data
Existence of the RKHS is shown by Moore-Aronszajn theorem.
Following is the definition of the reproducing kernel Hilbert space. [1]
[1] Rasmussen, Carl Edward. "Gaussian processes for machine learning." (2006).
What…?](https://image.slidesharecdn.com/labseminar-learningfromdata-151211060146/85/Robot-Learning-From-Data-10-320.jpg)









![CPSLAB (http://cpslab.snu.ac.kr)
Learning Theory
21Learning From Data
The goal of the learning theory is to minimize following functional:
𝐿 𝑓 = 𝑥∈𝑋
𝑓 𝑥 − 𝑓𝜌 𝑥
2
𝑃 𝑥 𝑑𝑥.
𝐿 𝑓 = 𝑓𝜌 − 𝑓
𝐿2 𝑃
2
is often called generalization error.
[1] Niyogi, Partha, and Federico Girosi. "On the relationship between generalization error, hypothesis
complexity, and sample complexity for radial basis functions." Neural Computation 8.4 (1996): 819-842.
If we use a radial basis function network, 𝑓 𝑥 = 𝑖=1
𝑛
𝑔𝑖 exp
𝑥−𝑧 𝑖
2
𝑙 𝑖
2 , we can
achieve following bound on the generalization error [1].
with probability at least 1 − 𝛿.](https://image.slidesharecdn.com/labseminar-learningfromdata-151211060146/85/Robot-Learning-From-Data-21-320.jpg)
![CPSLAB (http://cpslab.snu.ac.kr)
Learning Theory
22Learning From Data
[1] Niyogi, Partha, and Federico Girosi. "On the relationship between generalization error, hypothesis
complexity, and sample complexity for radial basis functions." Neural Computation 8.4 (1996): 819-842.
There are two sources of errors:
1. We are trying to approximate an infinite dimensional object, the regression
function 𝑓0 with a finite number of parameters (approximation error).
Approximation error: 𝑂
1
𝑛
2. We minimize the empirical risk and obtain 𝑓𝑛,𝑙, rather than minimizing the
expected risk (estimation error).
Estimation error: 𝑂
𝑛𝑘 ln 𝑛𝑙 −ln 𝛿
𝑙
0.5](https://image.slidesharecdn.com/labseminar-learningfromdata-151211060146/85/Robot-Learning-From-Data-22-320.jpg)


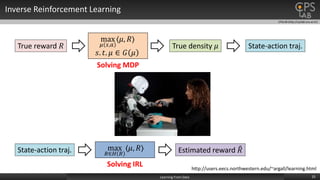
![CPSLAB (http://cpslab.snu.ac.kr)
Inverse Reinforcement Learning Methods
26Learning From Data
NR [1]
MMP [2]
AN [3]
MaxEnt [4]BIRL [6] RelEnt [7]
StructIRL [8] GPIRL [5]
DeepIRL [9]
[1] Ng, Andrew Y., and Stuart J. Russell. "Algorithms for inverse reinforcement learning." ICML, 2000.
[2] Ratliff, Nathan D., J. Andrew Bagnell, and Martin A. Zinkevich. "Maximum margin planning." ICML, 2006.
[3] Abbeel, Pieter, and Andrew Y. Ng. "Apprenticeship learning via inverse reinforcement learning." ICML, 2004.
[4] Ziebart, Brian D., Andrew Maas, J.Andrew Bagnell, and Anind K. Dey, "Maximum Entropy Inverse Reinforcement Learning."AAAI. 2008.
[5] Levine, Sergey, Zoran Popovic, and Vladlen Koltun. "Nonlinear inverse reinforcement learning with Gaussian processes." NIPS 2011.
[6] Ramachandran, Deepak, and Eyal Amir. "Bayesian inverse reinforcement learning.“, AAAI, 2007
[7] Boularias, Abdeslam, Jens Kober, and Jan R. Peters. "Relative entropy inverse reinforcement learning." AISTATS. 2011.
[8] Klein, Edouard, Matthieu Geis, Bilal Piot, and Olivier Pietquin, "Inverse reinforcement learning through structured classification." NIPS. 2012.
[9] Wulfmeier, Markus, Peter Ondruska, and Ingmar Posner. "Deep Inverse Reinforcement Learning." arXiv. 2015.](https://image.slidesharecdn.com/labseminar-learningfromdata-151211060146/85/Robot-Learning-From-Data-26-320.jpg)
![CPSLAB (http://cpslab.snu.ac.kr)
Inverse Reinforcement Learning Methods
27Learning From Data
NR [1]
MMP [2]
AN [3]
Maximize discrepancy between expert’s and sampled value.
Objective
Maximize margin between expert’s demonstration and every state-actions.
Minimize value between expert’s and sampled ones.
StructIRL [8] Cast IRL to multi-class classification problem.
NR [1]
MMP [2]
AN [3]
StructIRL [8]](https://image.slidesharecdn.com/labseminar-learningfromdata-151211060146/85/Robot-Learning-From-Data-27-320.jpg)
![CPSLAB (http://cpslab.snu.ac.kr)
Inverse Reinforcement Learning Methods
28Learning From Data
MaxEnt [4]
BIRL [6]
RelEnt [7]
GPIRL [5]
DeepIRL [9]
Objective
Define likelihood of state-action trajectories and use MLE.
MaxEnt [4]
BIRL [6]
Define posterior of state-action trajectories and use MH sampling.
Define likelihood using SGP and use gradient ascent method.
Minimize relative entropy between expert’s and learner’s distribution.
GPIRL [5]
RelEnt [7]
DeepIRL [9]
Model likelihood with neural networks.](https://image.slidesharecdn.com/labseminar-learningfromdata-151211060146/85/Robot-Learning-From-Data-28-320.jpg)


The document presents an overview of machine learning approaches in robotics, specifically focusing on direct policy learning and reward learning methods within the framework of reproducing kernel Hilbert spaces (RKHS). It discusses the theoretical foundations of these methods, including regression techniques and kernel-based approaches, and outlines various applications in reinforcement learning and inverse reinforcement learning. The conclusion emphasizes the importance of selecting appropriate algorithms for effective learning from data.








![[PR12] PR-050: Convolutional LSTM Network: A Machine Learning Approach for Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/pr12-convlstm-171126135417-thumbnail.jpg?width=640&height=640&fit=bounds)