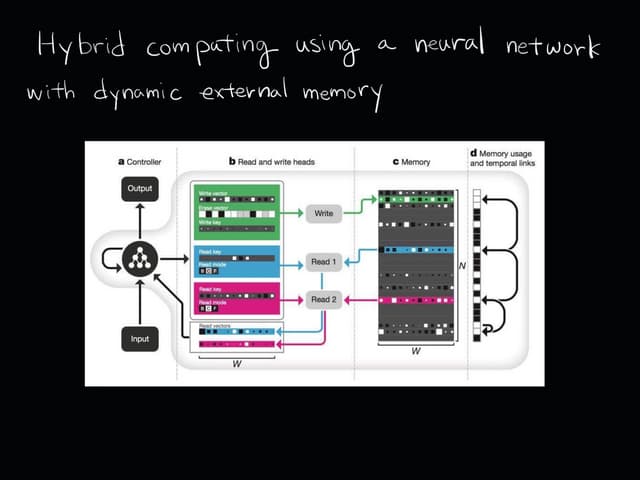
Download as PDF, PPTX















![Conclusion
17Scalable Robust Learning from Demonstration with Leveraged Deep Neural Networks
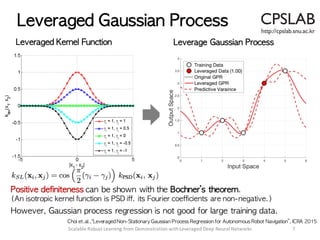
§ Robust and scalable learning from demonstration is presented.
§ Robustness comes from the leverage optimization [1].
§ Scalability comes from the leveraged deep neural network using
the proposed leveraged cost function.
§ The proposed method is successfully applied to a track driving
task where the demonstrations are collected from multiple modes
with different proficiencies.
§ Further work will focus on incorporating the uncertainty information
of a model prediction using a Bayesian network where the initial
results can be found in [2].
[1] Choi et.al.,"Robust Learning from Demonstration Using Leveraged Gaussian Processes and Sparse-Constrained Optimization”, ICRA 2016
[2] Choi et. al. ‘Uncertainty-Aware Learning from Demonstration using Mixture Density Networks with Sampling-Free Variance Modeling’, ArXiv1709.02249, 2017](https://image.slidesharecdn.com/slidesfinal-170927060750/85/LevDNN-17-320.jpg)



The document discusses a method for scalable and robust learning from demonstration (LfD) using leveraged deep neural networks and Gaussian processes. It addresses existing limitations in LfD, particularly the need for optimality in demonstrations and scalability concerns, proposing a leverage optimization approach that integrates mixed-quality data. The proposed method shows promising results in autonomous robot navigation and aims to incorporate uncertainty information in future work.








![[PR12] Spectral Normalization for Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/pr12spectralnormalizationforgans-180513142600-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/pr12understandingdeeplearningrequiresrethinkinggeneralization-180121135850-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Lecture 4] AI and Deep Learning: Neural Network (Theory)](https://cdn.slidesharecdn.com/ss_thumbnails/lecture4ink-180216131712-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PR12] intro. to gans jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12intro-170416162251-thumbnail.jpg?width=640&height=640&fit=bounds)