Download as PDF, PPTX










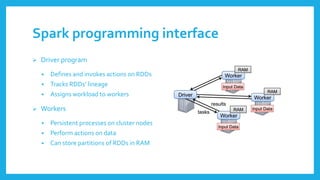

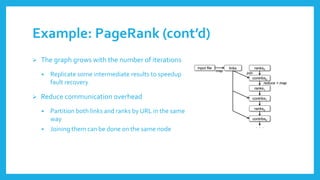














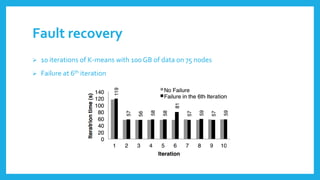









The document introduces Resilient Distributed Datasets (RDDs), a fault-tolerant in-memory computing abstraction designed for efficient data processing in cluster environments, particularly for tasks like machine learning and real-time data mining. RDDs enable efficient data reuse, lazy computation, and user control over data persistence while addressing high I/O latency and fault recovery issues. Implemented in Apache Spark, RDDs leverage a lineage tracking system to optimize performance through task scheduling and recovery from failures.



































































