Download as PDF, PPTX



































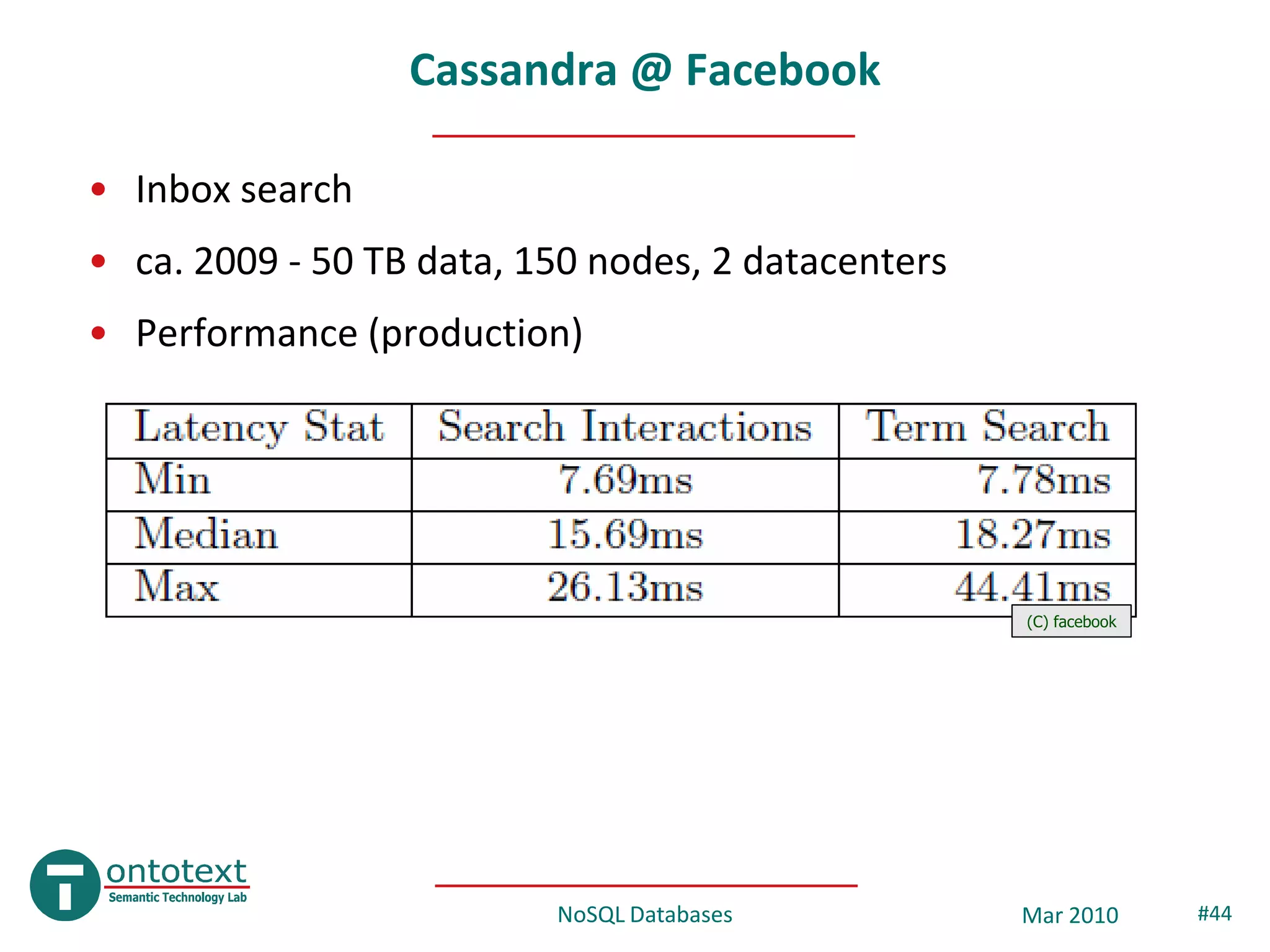

![CouchDB
• http://couchdb.apache.org/ , ~2005
• Schema-free, document oriented database
– Documents stored in JSON format (XML in old versions)
– B-tree storage engine
– MVCC model, no locking
– no joins, no PK/FK (UUIDs are auto assigned)
– Implemented in Erlang
• 1st version in C++, 2nd in Erlang and 500 times more scalable (source:
“Erlang Programming” by Cesarini & Thompson)
– Replication (incremental)
{
• Documents “name”: “Ontotext”,
“url”: “www.ontotext.com”
– UUID, version “employees”: 40
– Old versions retained “products”: [“OWLIM”, “KIM”, “LifeSKIM”, “JOCI”]
}
NoSQL Databases Mar 2010 #46](https://image.slidesharecdn.com/techwatch-nosql-100329073709-phpapp01/75/NoSQL-databases-46-2048.jpg)



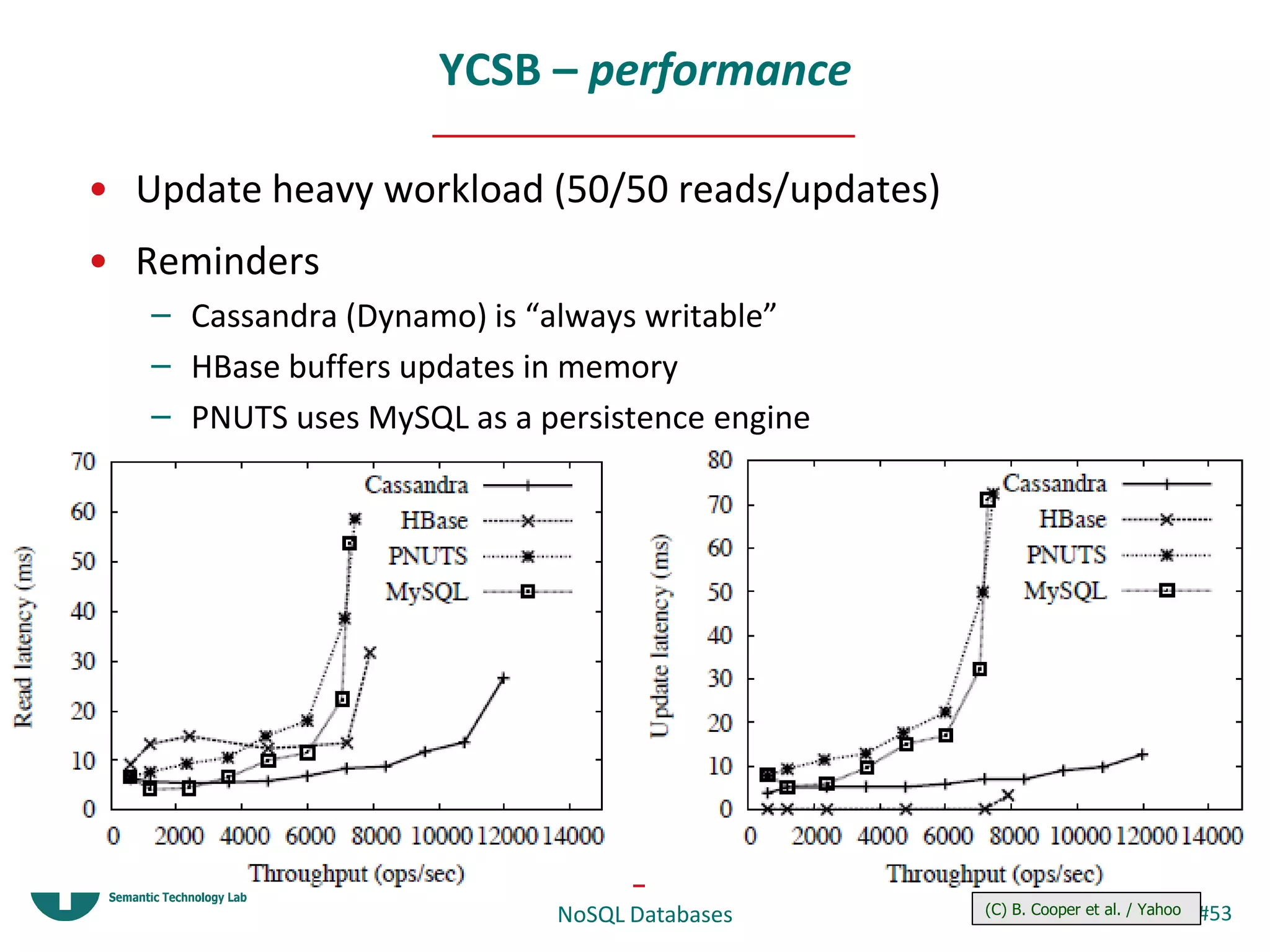
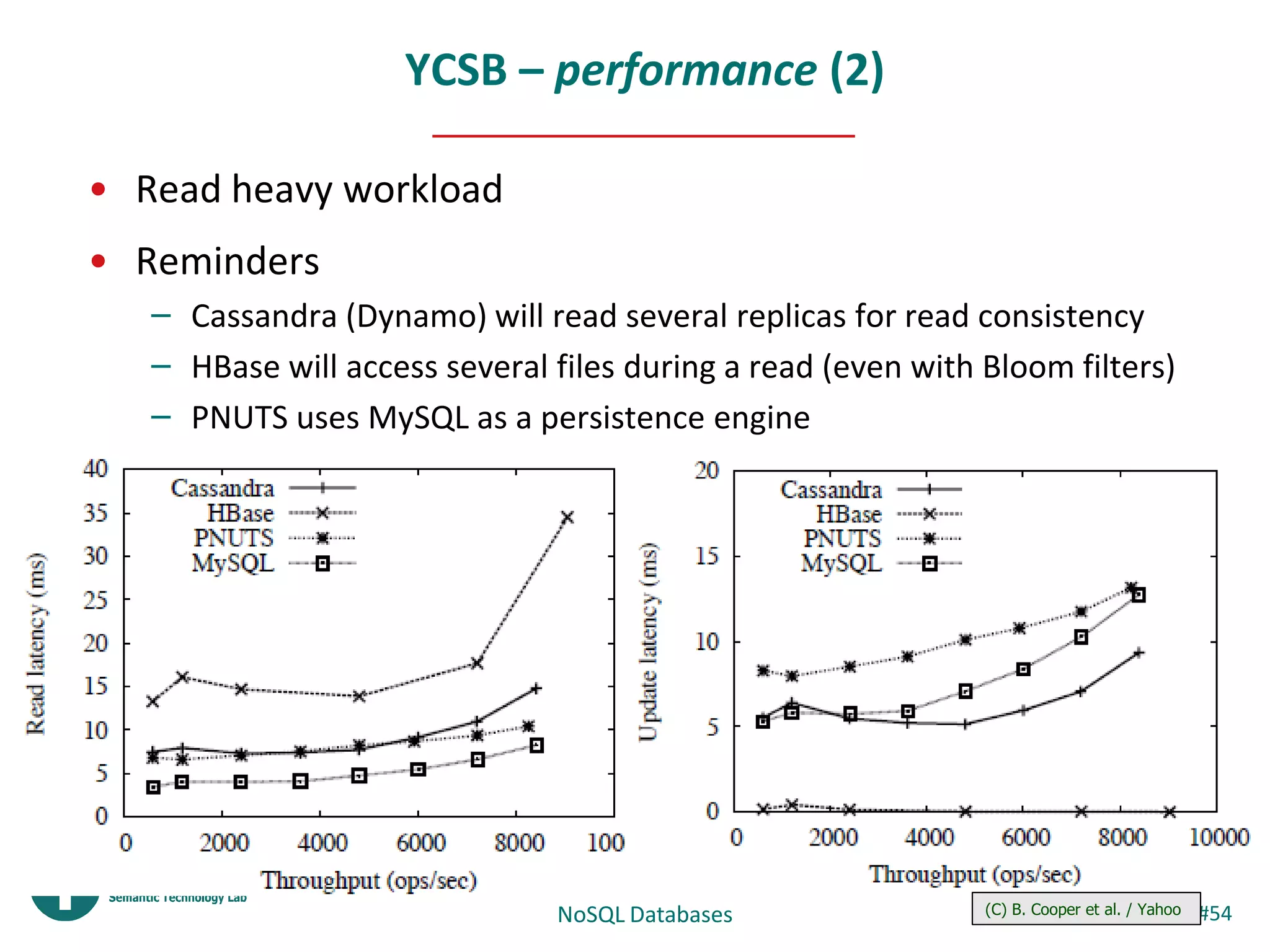
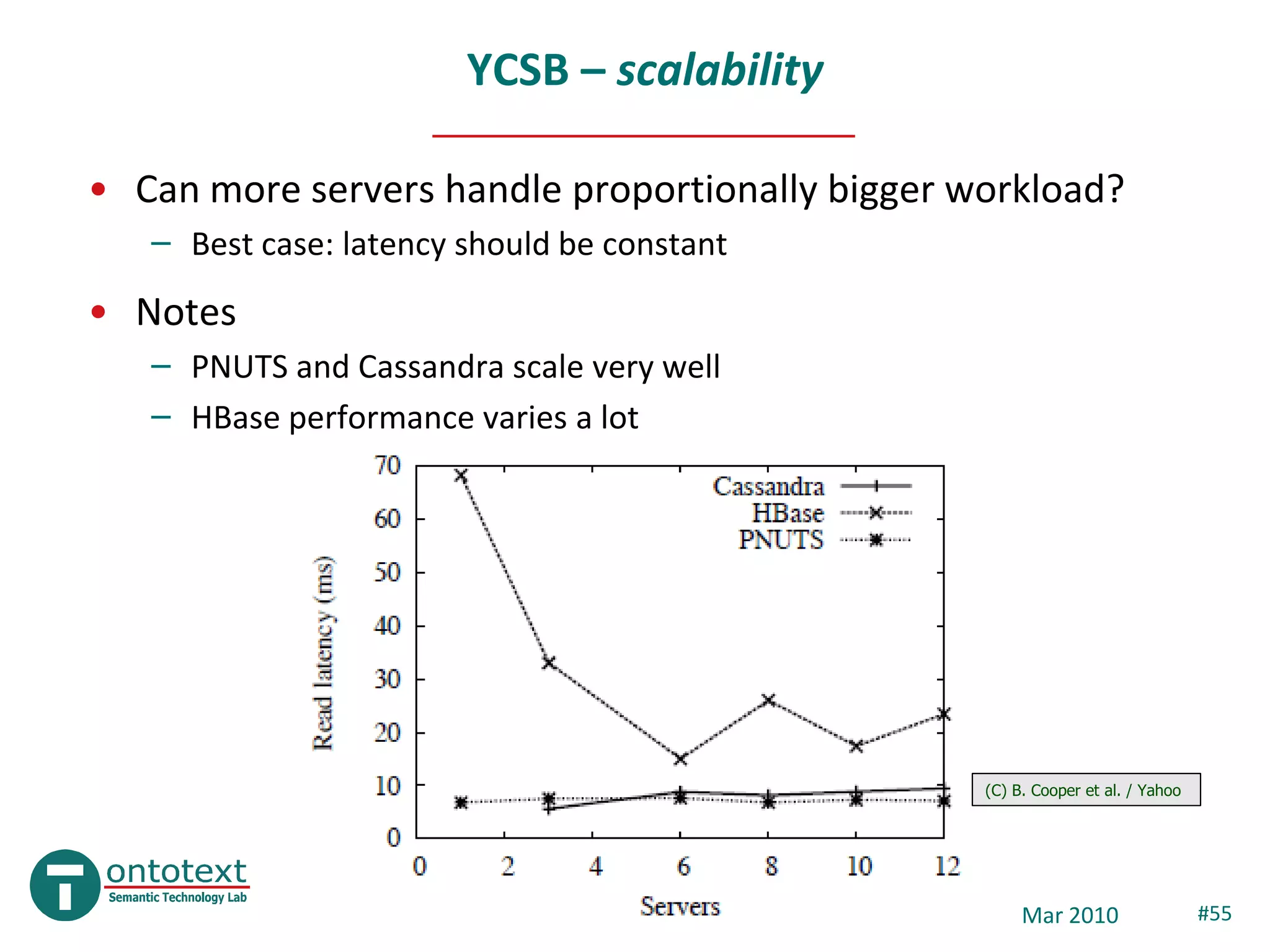
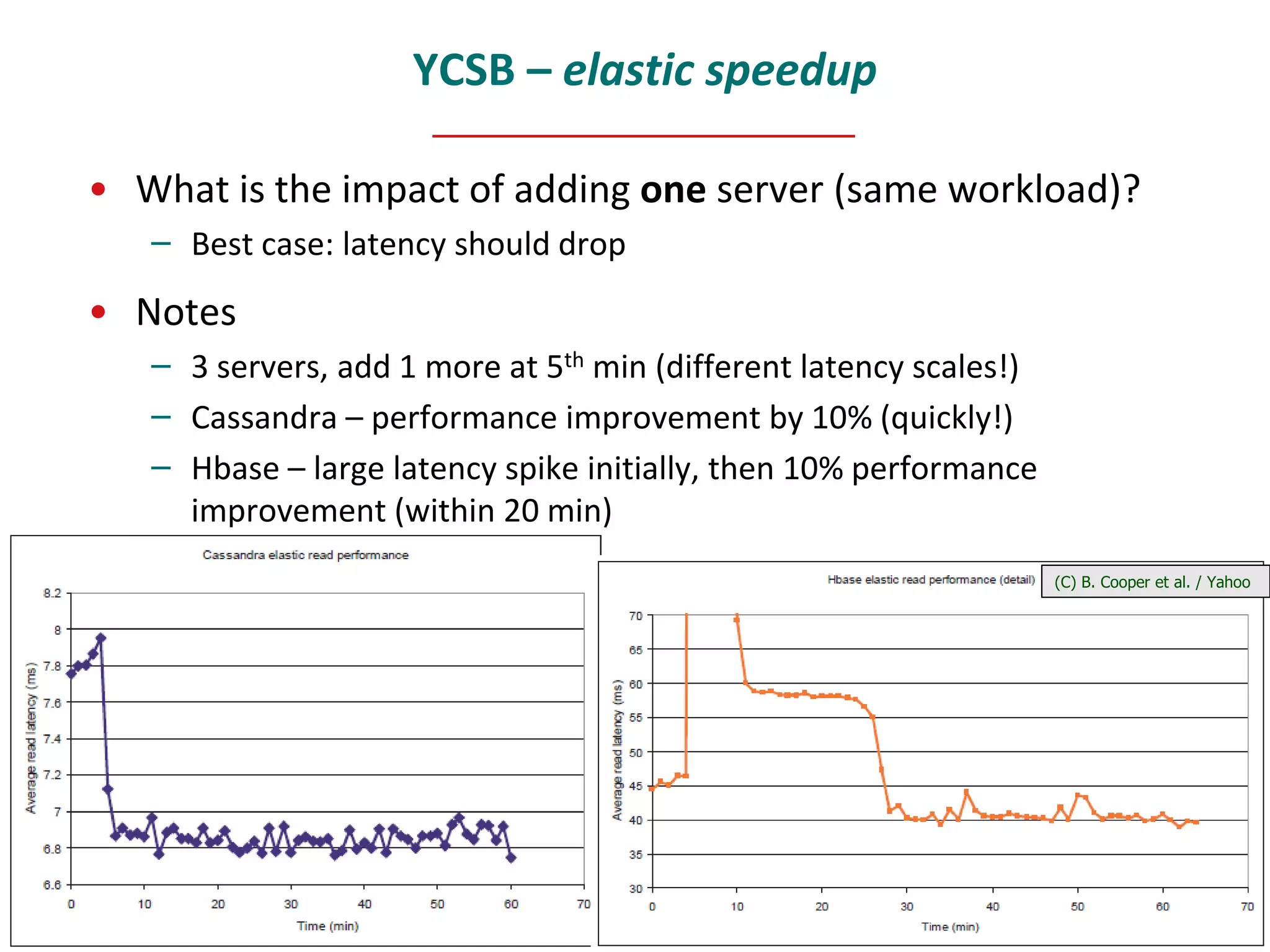





This document provides an overview and introduction to NoSQL databases. It discusses key-value stores like Dynamo and BigTable, which are distributed, scalable databases that sacrifice complex queries for availability and performance. It also explains column-oriented databases like Cassandra that scale to massive workloads. The document compares the CAP theorem and consistency models of these databases and provides examples of their architectures, data models, and operations.




























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












